
現時点で最強AIモデルと噂されるHuggingGPTを使ってみた

Hugging Faceで、HuggingGPTのSpacesが出来たということで早速利用してみました。HuggingGPTは、簡潔に言うと、Hugging Faceにある大量のモデルをテキストベースのチャットで利用することが出来るモデルとなります。
HuggingGPTのSpacesからプログラムをダウンロードしてGoogle Colabの環境で実現したいと思いましたが、今回はどんなことがHuggingGPTで出来るのか見ていきます。
HuggingGPTのSpacesは以下です。
最初に、1番目のテキストボックスにOpenAIのAPIキーを入力してください。2番目のテキストボックスには、HuggingFaceのAccessTokenを入力してください。入力しましたら、各々送信を押下します。
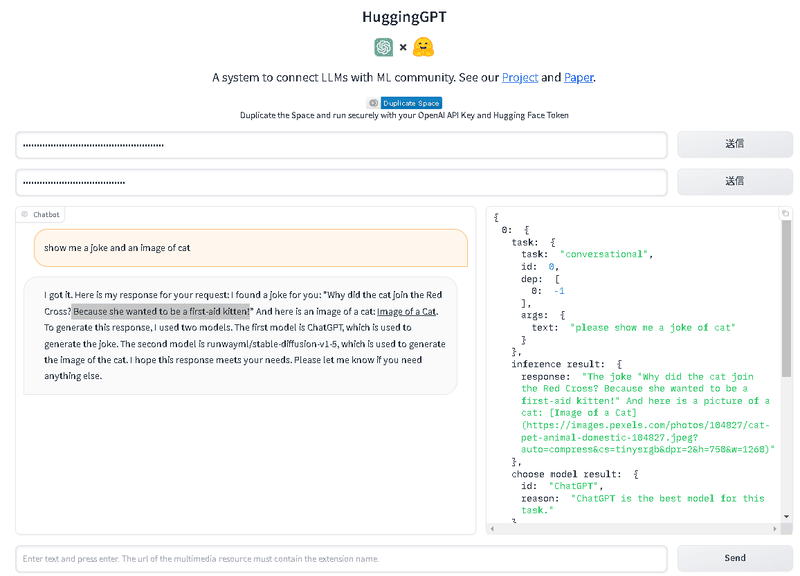
Sendのところのテキストボックスに、「Show me a joke and an image of cat」と入力して、Sendを押下すると上記の結果が出てきます。
結果についてみていきます。
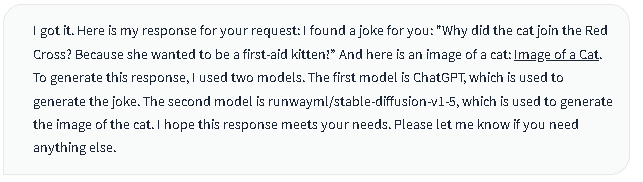
猫に関するジョークを作成してと聞いたら、「猫が赤十字になぜ入りたかったのだい?」と聞いたら、「猫は救急キャットになりたかったからさ。」というジョークを作成しています。ここは、私もあまりジョークの意味がわからなかったのですが、子猫が救急処置を施すことができないことを暗示しているユーモアを表したジョークだそうです。
そして、画像のリンクもありますので、画像は以下でした。

その後の文言は、このジョークと画像を作るのに、ChatGPTとrunwayml/stable-diffusion-v1.5を利用したと、利用したモデルを紹介しています。
さて、他にもどんなことが出来るの色々とみてみます。


runwayml/stable-diffusion-v1.5を利用して猫の画像を作りましたが、アニメ風に変換するモデルが見つからなかったそうです。prompt次第だと思いますので、アニメ風には出来るのではないかと思います。

上記の作成された画像について、質問してみます。


結果は猫は1匹いますとのことです。画像から猫が1匹を算出するまでの過程で、ydshieh/vit-gpt2-coco-enで画像で表現されていることをテキスト化してたら、街中に1匹の猫がいるとわかりましたとのことです。
その他にも、facebook/detr-resnet-101を画像からオブジェクトを抽出するために使い、1匹猫がいることがわかりましたとのことです。
最後に、dandelin/vlit-b32-finetuned-vqaというビジュアルクエスチョン回答モデルを使い、猫が1匹いることを突き止めましたとのことです。
画像から猫1匹を検出するために、3つのモデルを利用して、判別しているようです。
他にも見ていきましょう。画像系のモデルを利用しましたので、今度はテキスト系はどの程度なのか見てみます。


GPT-4は、1750億パラメータがあり、要約、質疑応答、翻訳、感情分析などに役立ちますし、数学的問題や論理的推論も強くなりましたとのことです。きっちりと要約されているように思えます。

利用したモデルとしては、text2text-generationをChatGPTで使いましたとのことです。ChatGPTのAPI料金が少し気になりました。(笑)
使用した印象は、質問の仕方次第で様々なことが出来るのかなと考えています。いかに質問を精錬させていくかが今後のユーザ側の課題でしょう。また、下記のように全てのモデルが使えるわけでもないような気がします。


猫の動画を作るのに、text-to-videoは無いそうです。ここ数週間でtext-to-videoのモデルをhuggingfaceにありましたので使えるかと思いましたが残念です。ただ、そのうち使えるようにはなるのでしょう。
(※追記)
下記にHuggingGPTをGoogleColabで使用する記事を用意しました。
この記事が気に入ったらサポートをしてみませんか?