
ChatGPTをファインチューニング:とりあえずPythonで動かしてみよう

ChatGPTなどの生成AI(人工知能)は、文章や画像、音楽などをAIを使って作成する技術です。
この記事では、生成AIを特定の目的に合わせて調整する「ファインチューニング(Fine-Tuning)」について、ChatGPTを使って基本的な説明からPythonでの実装例までを解説します。
ファインチューニングとは?
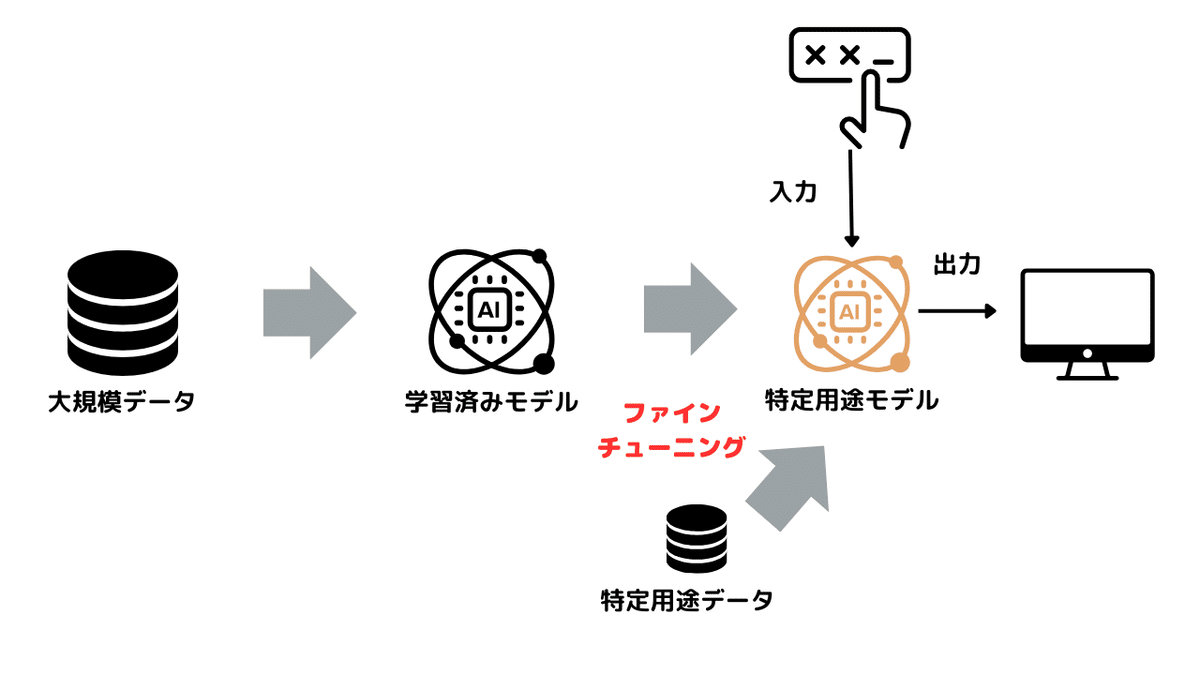
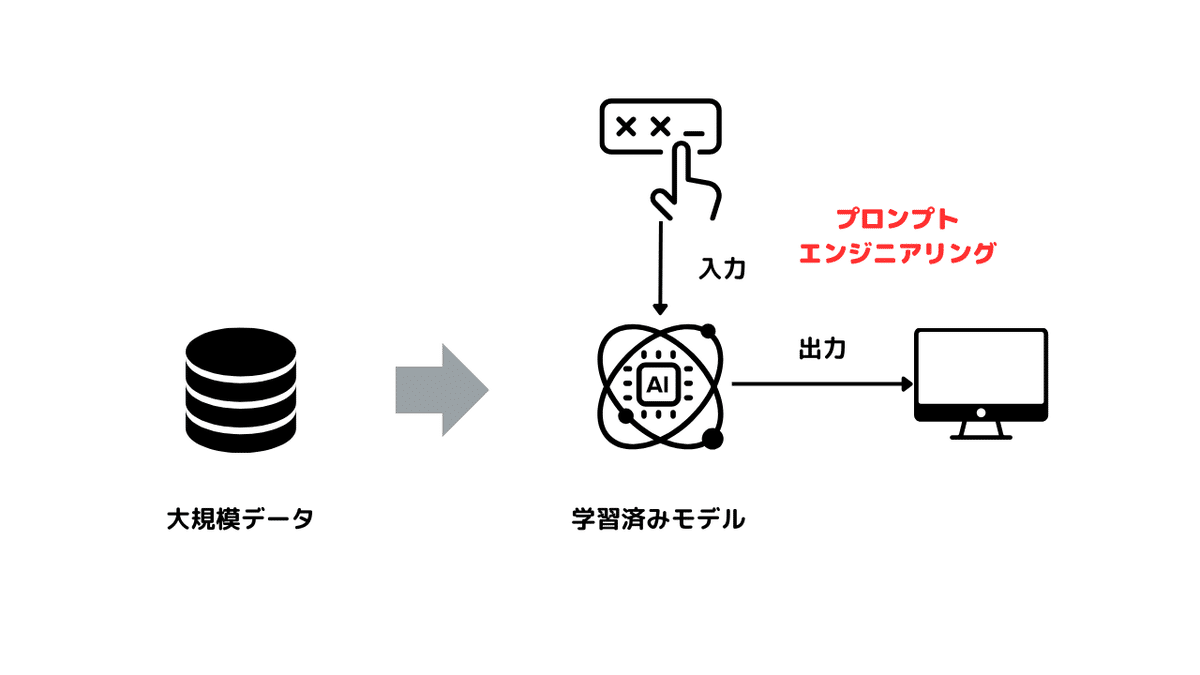
ファインチューニングは、既存のAIモデルを特定のタスクやデータに合わせて調整する方法です。よく似た手法にプロンプトエンジニアリングがあります。
ファインチューニングが事前学習済みモデル自体を特定のタスクやデータに合わせて調整して最適化するのに対し、プロンプトエンジニアリングは出力を調整するための指示(プロンプト)を工夫する方法です。
プロンプトエンジニアリングについては下記の記事で紹介しています。
ファインチューニングはより高品質な結果と低レイテンシを提供しますが、時間とリソースが必要です。一方、プロンプトエンジニアリングは比較的簡単で早く、即座のフィードバックが得られます。
なお、ファインチューニングは有料サービスであり、こちらに詳細な価格表があります。

Pythonでのファインチューニングの実装
それでは、ファインチューニングのイメージを具体的にするために、実際にChatGPTに実装してみましょう。
STEP1 Open APIのAPI Keyを用意
Open AIのAPI Keyを取得し、下記のような内容で「api_key.txt」として保存します。
sk-xxxxxxxxxxxxxxxxxxxxxxSTEP2 学習データを用意
下記のようなJSONLのフォーマットで学習データを記載します。ここでは、ファイル名を「mydata.jsonl」とします。
{"messages": [{"role": "system", "content": "あなたは、Codeland Teachersという名前で、プロキッズが提供する子供向けプログラミングスクール「Codeland」に関する質問の受け答えをするChatです。"}, {"role": "user", "content": "プロキッズのメンター陣のバックグラウンドは?"}, {"role": "assistant", "content": "プロキッズのメンター陣は、大学生から社会人、主婦まで多様なバックグラウンドを持っています。"}]}
{"messages": [{"role": "system", "content": "あなたは、Codeland Teachersという名前で、プロキッズが提供する子供向けプログラミングスクール「Codeland」に関する質問の受け答えをするChatです。"}, {"role": "user", "content": "Codelandは何ですか?"}, {"role": "assistant", "content": "Codelandはプロキッズが提供するプログラミング教育サービスです。"}]}ここで示した例は2個ですが、OpenAIのガイドラインによると、実際には最低でも10個のデータセットを用意する必要があります。
STEP3 Pythonのコードを実行
# 必要なライブラリをインポート
import os
import openai
# OpenAIのAPIキーを設定ファイルから読み込む
openai.api_key_path = "api_key.txt"
# JSONL形式のデータファイルを読み込み、ファインチューニングの目的でアップロード
uploaded_file = openai.File.create(
file=open("mydata.jsonl", "rb"),
purpose='fine-tune'
)
# アップロードしたファイルのIDを取得
training_file_id = uploaded_file.id
print("training_file_id: ",training_file_id)
# ファインチューニングジョブを作成。使用するモデルは"gpt-3.5-turbo"
openai.FineTuningJob.create(training_file=training_file_id, model="gpt-3.5-turbo")
# 最新のファインチューニングジョブのリストを取得し、上限を10に設定
job_list = openai.FineTuningJob.list(limit=10)
print(job_list)STEP4 ファインチューニングが終わるまで待機
Pythonを実行後、下記のように出力されます。
training_file_id: file-xxx
{
"object": "list",
"data": [
{
"object": "fine_tuning.job",
"id": "ftjob-1111",
"model": "gpt-3.5-turbo-0613",
"created_at": 1695640113,
"finished_at": null,
"fine_tuned_model": null,
"organization_id": "org-abc",
"result_files": [],
以下略)
fine_tuned_modelがnullなのでまだ完了していないことが分かります。
STEP5 メールを受信
ファインチューニングが完了すると下記のタイトルでメールが送信されます。
Fine-tuning job ftjob-1111 successfully completed
STEP6 OpenAI Playgroundで動作確認
OpenAI Playgroundにアクセスし、動作を確認します。
入力すると、下記のような結果を得ることができました。

ちなみに、ファインチューニングしていない「gpt-3.5-turbo」の場合は、下記のような出力でした。事実と異なる内容ですね。

ファインチューニングを使う上での注意点
今回はデータ量が少なかったこともあり、ファインチューニングを使うまでもなく、プロンプトエンジニアリングでも良かった内容でしたが、今回は理解度を高めるために使ってみました。
実際に使ってみて、下記のような課題を実感しました。
学習させるデータ量の問題
その中で、一般的に利用されている用語は下記のように出力されました。既存のモデルの知識として存在しているため、これを上書きするためにはデータ量を増やすなどの対策が別途必要です。

不要なModelの削除
不要なModelは混乱の原因になるので削除しておきましょう。
import openai
openai.api_key_path = "api_key.txt"
fine_tuning_jobs = openai.FineTuningJob.list(limit=10)
print(fine_tuning_jobs)
for fine_tuning_job in fine_tuning_jobs.data:
if fine_tuning_job.fine_tuned_model != None:
try:
openai.Model.delete(fine_tuning_job.fine_tuned_model)
except:
print("error:すでに削除されている可能性があります",fine_tuning_job.fine_tuned_model)まとめ
ファインチューニングは、特定のタスクやデータセットにAIモデルを最適化する強力な手法です。Pythonでの実装も比較的簡単であり、多くの用途で活用できるでしょう。
しかし、このプロセスは時間とリソースがかかるため、用途と目的に応じて最適な手法を選ぶことが重要です。プロンプトエンジニアリングと比較して、ファインチューニングはより高度なカスタマイズが可能ですが、費用も考慮する必要があります。
この記事が気に入ったらサポートをしてみませんか?