
推薦システムの国際学会RecSys2020の参加録

イントロ
RecSysは推薦システムに関する国際学会で、今年で14回目の開催になります。本来ならブラジルで開催予定でしたが、昨今の情勢により今年はオンラインでの開催になりました。2020年9月22日から9月26日にかけて開催されました。
推薦システムは、Amazonのこれもチェックしている人はこれもチェックしていますのように、たくさんあるアイテムの中からおすすめのアイテムを選び出してくれる仕組みで、最近ではあらゆるサービスに組み込まれています。そのため、RecSysでは、大学などの学術機関だけでなく、AmazonやNetflixなどの企業からの参加者が6割を超えています。また、オンライン開催ということもあり、参加者は過去最多で1000人を超えています。


この記事では、推薦システムの国際学会でどんなことが今話題なのか、どんな研究があるのかを簡単にざっくりと紹介できればと思います。(WantedlyさんのRecSys参加レポートがすごく詳しいので詳細が気になる方はこちらもご参考ください。)
2020月10月17日に、RecSys2020の勉強会も開催しますので、ご興味ある方はぜひご参加ください。
RecSys2020
発表は主に次のような種類がありました。
・キーノートスピーチ(招待講演)
・スポンサーによる企業発表
・採択された論文の発表
・テーマ別のワークショップでの発表
論文やワークショップの一覧はこちらから確認できます。
キーノートスピーチ
今年は3つの招待講演がありました。
Reasons Why Social Media Make Us Vulnerable to Manipulation
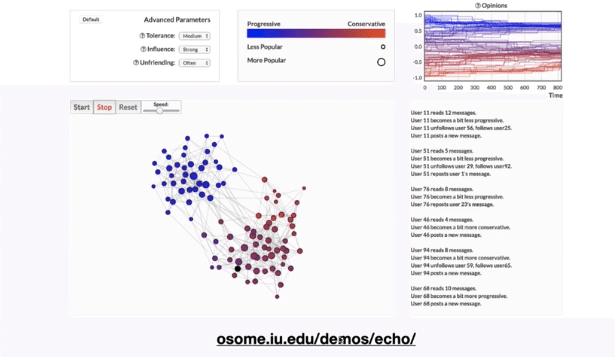
1つ目がソーシャルメディア上でのフェイクニュース拡散やコミュニティの分断などに関するものでした。自分と異なる意見が入ってこなくなり、自分の考えが偏ったまま増強されてしまうエコチェンバーという現象が起こる仕組みを「Social influence」と「unfollowing」という観点で説明していました。こちらでシミュレーションもできます。
Bias in Search and Recommender Systems
2つ目は、検索と推薦システムのバイアスについての講演でした。まずはじめに、検索と推薦システムの違いとして、クエリが明示的か暗黙的か無いのか、データが構造化されているのかされていないのかという軸で分けられていたのが印象的でした。

検索と推薦システムを作る際には様々なバイアスが含まれてしまいます。例えば、人気バイアスでは、人気なものはより表示されやすくなり、より人気になってしまいます。そういったバイアスを除去するためには、アルゴリズムや評価手法、データに対して工夫する必要があります。しかし、バイアスは入り組んでおり各バイアスがお互いに影響を与えていて、簡単に取り除くことはできません。バイアスを除去して公正な推薦システムを構築するというテーマは最近の話題の1つです。

"You Really Get Me": Conversational AI Agents That Can Truly Understand and Help Users
3つ目は、ユーザーのパーソナリティを把握して、よりパーソナライズしたAIエージェントを開発するという講演でした。ユーザーのパーソナリティをユーザーが入力したテキストを元に、ビッグファイブを推測するというものでした。ビッグファイブとは心理学の分野で盛んに研究されているモデルで、人のパーソナリティを外交性や誠実性などの5つの要因で説明するものです。そのパーソナリティによって好むものの傾向が違うので、その情報を活かすことで、より適切なレコメンドを行うというものでした。


スポンサーによる企業発表
今年は下記の企業がメインのスポンサーになっており、スポンサー枠として、数十分ほどの発表枠をもらうことができ、どのような推薦システムを作っているかについて発表できます。世界中から推薦システムに携わる研究者やエンジニアが集まるので、企業にとっては絶好の製品紹介や採用活動の場になります。Netflixの発表を簡単にご紹介したいと思います。

Netflix
アイテムの類似度とは何なのかをユーザー調査しながら分析しています。Netflixの動画推薦では、1)Netlixの画面上のどの場所でおすすめするのか、2)ユーザーがどのような興味を持っているのか、3)ユーザーの今のコンテキスト(気分や状況)は何なのかという3つの要素が重要という結論になったそうです。新しい類似度のモデルをリリースしたところ、以前のものより納得度が高いものが推薦されるようになりました。
採択された論文の発表
今年は39のロングペーパーと26のショートペーパーが採択されました。日本からも4本の論文が採択されています。

研究のテーマとしては、推薦システムのアプリケーションやアルゴリズムに関するものがメインで、ユーザー体験に関する研究や社会や経済の影響に関する研究もありました。
Best Paper

今年のBest paperの候補は4つあり、最終的に「Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations」が選ばれました。
Best paperの候補4つと個人的に気になったものをいくつかピックアップして、簡単に紹介していきます。(少し専門的な言葉が増えますので、「テーマ別のワークショップでの発表」の章まで適宜読み飛ばして貰えればと思います。)
マルチタスク学習では、1つのタスクで性能を上げようとすると他のタスクの性能を下げてしまうシーソー現象が観測されます。例えば、動画推薦で視聴回数を上げようとすると視聴時間が下がってしまうというような問題です。その問題を解決するために、Progressive Layered Extraction(PLE)というモデルを提案しています。

実際にテンセントの動画推薦のサービスでA/Bテストしたところ、視聴回数と視聴時間のどちらの指標も有意に増加し、ビジネス価値も大きいものでした。
SSE-PT: Sequential Recommendation Via Personalized Transformer (Best Paper Candidates)
自然言語処理の分野で人気のTransformerの仕組みを推薦システムに応用したものです。Transformerでは、文章内の単語をランダムに欠損させて、それを予測していますが、推薦システムにおいては、ユーザーの購入やクリックなどの行動履歴において一部のアイテムを欠損させて、それを予測するようにしています。純粋にTransformerを推薦システムに適用するものは以前にあったのですが、この論文では、ユーザーベクトルの導入と学習が上手くいくようにStochastic Shared Embeddingsという正則化手法の導入をしています。結果として性能が良くなり、かつ、解釈性に優れたモデルになっています。

Revisiting Adversarially Learned Injection Attacks Against Recommender Systems
推薦システムに偽のデータを混入させることで、特定のアイテムを推薦させてしまうという攻撃について、今までの研究を精査してまとめた論文になります。今までの手法の問題点を整理した上で、リアルワールドのデータを用いて、様々な条件下での推薦システムに対する攻撃のシミュレーションをしています。

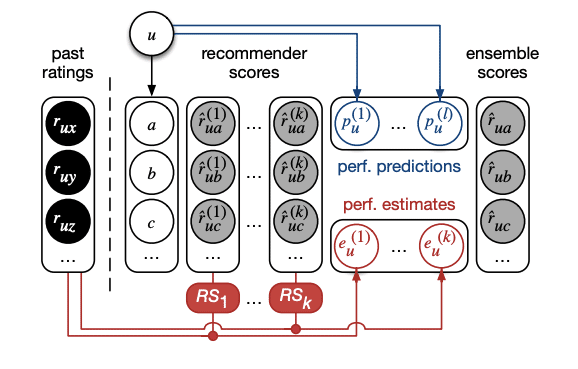
Exploiting Performance Estimates for Augmenting Recommendation Ensembles
複数の推薦システムを組み合わせることで予測精度を上げるのは効果的です。しかし、各推薦システムの強み弱みを把握して、特徴量エンジニアリングなどの人手による作業が多いこともあります。この研究では、各推薦システムを組み合わせるときの重みをユーザーの過去の評価値から直接推測することで、人手の作業を排除し、予測性能を大幅に向上させました。
Are We Evaluating Rigorously? Benchmarking Recommendation for Reproducible Evaluation and Fair Comparison
昨年のベストペーパーのAre we really making much progress? A worrying analysis of recent neural recommendation approachesと似た論文で、最近のRecSysやSIGIRなどのトップカンファレンスに採択された推薦システムの85論文を調査しました。データの分割方法やパラメータ調整についてまとめています。なんと37%の論文がテストデータを用いてハイパーパラメータを調整していました。この論文では、統一的な評価プロセスを提案し、それらが簡単に実行できるDAISYというPythonのライブラリを公開しています。
Contextual and Sequential User Embeddings for Large-Scale Music Recommendation
Spotifyによる音楽推薦に関する論文です。音楽推薦では、過去の視聴履歴とその時のセッションにおけるコンテキストの2つが重要です。セッションにおけるコンテキストとは、日中なのか夜なのか、スマホなのかPCなのかという情報です。これらの2つの情報を活用して、ユーザーの好みをLSTMなどを用いて推測します。

Contextual User Browsing Bandits for Large-Scale Online Mobile Recommendation
eコマースのモバイルサイトでは、画面が小さく、一度に表示される商品の数に限りがあります。そのため次の2つの問題が発生しています。1つ目が上にある商品のほうがクリックされやすい。2つ目は下の方にあるせいで、閲覧されてないからクリックされてないものをネガティブサンプルとして学習に使ってしまう問題です。これらを解決するcontextual banditの手法を提案しています。

Debiasing Item-to-Item Recommendations With Small Annotated Datasets
これが好きな人はこれも好きというItem-to-itemの推薦は、いろいろなサービスに使われていて重要です。Item-to-itemの推薦を過去のインタラクションのデータから学習すると様々なバイアスがあります。この論文では、アノテート付きの少量のデータから、因果推論に基づいてそれらのバイアスがない形で、Item-to-itemの推薦を行う手法を提案しています。
Recommending the Video to Watch Next: An Offline and Online Evaluation at YOUTV.de
動画サイトにおいて、次の動画をおすすめするときに、ユーザーの短期間での好みを推測することは重要です。この論文では、マルコフ連鎖を利用して、ユーザーの短期間の好みを推測するモデルを提案しています。実際にサービスでオンラインでA/Bテストしたところ、CTRが93.61%ほど増加しました。
Neural Collaborative Filtering vs. Matrix Factorization Revisited
行列分解に代表されるEmbeddingの内積を使って推薦するという古典的な手法と、類似度をニューラルネットワークで学習するという最近の手法を改めて検証した論文です。適切にパラメータを調整することで、古典的な行列分解のほうが、ニューラルネットワークベースのものより性能が良いことを示しています。
ImRec: Learning Reciprocal Preferences Using Images
オンラインマッチングサービスの相互推薦で、顔写真を使った新しい推薦システムの手法を提案しています。日本のPairsのデータを使って、精度向上を検証しています。ユーザーが過去にポジティブ/ネガティブな反応をした人たちの顔写真をSiameseネットワークで学習するというものです。

From the lab to production: A case study of session-based recommendations in the home-improvement domain
セッションベースの推薦システムについて検証した論文になります。オフライン評価方法として、推薦した商品が実際に購入されたものかどうかを指標とする場合、その商品IDが正確に一致していないと間違ったものとみなされています。しかし、その商品が実際に購入されていたものと似ている場合もあります。そういったことを考慮して新しく評価データセットを作ったところ、今までの評価データセットと新しい評価データセットで、良い性能を出す推薦システムが異なりました。新しい評価データセットで良い性能を出した推薦システムを実際にオンラインで試してみると15.6%ほどCVRが増加しました。

テーマ別のワークショップでの発表
ワークショップでは、ファッションや音楽、強化学習などの各ドメインごとに、本会議とは別に論文の投稿/査読があり、発表が行われます。各ドメインごとに、濃密な議論がされていますので、これから推薦システムを作ろうと考えている方は、似ているドメインのワークショップの資料を過去に渡ってざっと眺めるのがおすすめです。
REVEAL 2020: Bandit and Reinforcement Learning from User Interactions
バンディットや強化学習に関するワークショップになります。NetflixやMicrosoftなどの企業から発表が多いです。日本からは、@usaitoさんのバンディットアルゴリズム用の大規模データセットの公開に関する発表があり、大きな注目を集めていました。
RecSys 2020 Challenge Workshop: Engagement Prediction on Twitter’s Home Timeline
毎年開催されているRecSysチャレンジというデータ分析のコンペティションのワークショップです。今年はTwitterのデータを使って、ユーザーのいいねやリツイートなどの行動を予測するというものです。1位はNvidiaのチームで、3位は日本からWantedlyのチームでした。
Workshop on Recommender Systems in Fashion
ファッションに特化した推薦システムに関するワークショップです。ファッションにおいて重要な色やサイズ、コーディネーションをどうモデルに組み込むかといった発表がありました。
他にもいろいろと面白いワークショップがありました。こちらにワークショップ一覧があります。
まとめ
推薦システムの国際学会について簡単にまとめました。参加者が年々増えていて、企業からの注目も大きくなっているように思います。
キーノートや採択論文では、バイアスに関するものが多い印象でした。データやアルゴリズム、評価方法に潜むバイアスをどのように除去して、精度が高い推薦システムを作るかが最近盛り上がっているテーマのように感じました。
企業からの発表も多く、各企業の求人の一覧が見れるページもあったのですが、 AmazonやNetflix、Apple、Twitterなどが企業が推薦システムの求人を出していました。それぞれの企業ごとに求める推薦システム人材に特色があり、興味深かったです。
来年はオランダのアムステルダムで開催のようです。
おまけ
本来ならブラジルで開催予定でしたが今年はオンライン開催となりました。オンラインに居ながらブラジルを感じるということで、レセプションで、カイピリーニャというカクテルの作り方についての講座もありました。
たまたま家にカシャーサがあったので作ってみたのですが、すごく美味しかったです。


この記事が気に入ったらサポートをしてみませんか?