
【試験体験記】Python3エンジニア認定データ分析試験

Python3エンジニア認定データ分析試験を先日受験し、合格しました。
この試験もある程度知名度が増してきて、同じような体験記書かれてる方も多くいらっしゃいますが、私のエントリーレベルに近い方の役に立つかもと思い投稿します。
試験公式ページはこちら↓
受験した理由
pythonについては、働き始めるくらいから世の中でデータサイエンスがバズワード仕出してることもあり、ミーハー心も手伝って使いこなせるようになりたいと感じてました。
また、直近1 年前後は特に、会社の仕事でもニーズを感じてました。
社内でpython環境は(任意で)構築出来るようになってはいましたが、使ってる人はほんの一握りで、(私含め)処理速度の遅いデータ分析ツールが使っている人が大半でした。
そんなような背景もあり、存在を知ったこの資格のことを調べているうちにpythonでのデータ分析などを身に付けるのにちょうど良いのではと感じて思い切って受験するに至りました。
受験前の私のデータ分析やPythonのリテラシーレベル
ここから先の内容を読むにあたり、筆者のpython、機械学習、数学などの前提情報は、読者の方々自身との近しい所や違う部分から勉強方法を調整するのに必須と思われるので、なるべく詳細に書いておきます。
大学の勉強分野
人文系でデータ分析はほぼ全く利用なし。
線形代数、微積分、確率統計学習経験
専門的にはなし。
ただし、高校生のとき(学校の方針として、文系でも数学Ⅲを理解してると文系範囲も解き易いという方針もあり)軽く数学Ⅲや線形代数の参考書を(大半は意味も分からないまま)読み流していたことはあり。
普段の業務分野
マーケティング関連で、システム系ではないながらデータマネジメント関連も経験あり。
データ分析経験
↑の業務の中で多少はあり。分析実務というよりは、その環境構築がメイン。
利用経験のあるソフトは、SQL 、Micosoft Access。
python利用経験
自宅でJupyterやGoogle Colabなどの環境構築は作ってネットで断片的に調べて操作したことはあり。
体系的ではなく断片的だが、触ったことがあるライブラリはこちら:numpy、pandas、scikit-learn、matplotlib、seaborn、polars
機械学習関連の学習・実務経験
2年半程前にG検定に合格しており、非エンジニアとしては初歩の初歩レベルならキーワードや概念は頭に詰め込んでいる状態。
ただし、実際の機械学習利用経験はほぼなし。auto ML製品を会社で周りの人が使っているのを見て一応何が使えるのかは理解しているくらい。
試験対策と期間
試験対策の戦略を考えるにあたり、以下の記事を大変参考にさせていただきました。
書いてくれた方ありがとうございます。
これらを参考にして、以下の参考書やアプリ・ページを活用しました。
https://a.r10.to/h5stCT
(気が向いた方はアフィリエイトリンク経由で購入いただけるとありがたいです)
巷では、他にPrime Studyをおすすめする記事もありましたが、私の学習初期の経験値的に全く歯が立たず、挫折しそうだったので辞めました。(YouTubeに解説動画もあったので、合う方には合う教材だと思います。)
勉強の仕方は、以下のような流れでした。
(一応公式なので)『データ分析の教科書』を通読。
内容的にはpythonのデータ分析周りの基礎をある程度整理して押さえてくれていて良い勉強になりました。(レビューサイトにも同じようなこと書かれてましたが、目的別というより機能別に書かれてる印象があり、機械学習やpythonの前提理解が全くないとかなり読み解き辛い気がします。。)
examappとDProをほぼ同時並行で周回。
模試については、前者は時間制限がなかったので、通勤電車の中で細切れに進めてました。
DProの模試は時間制限があったので、自宅で落ち着いているときに周回しました。
難易度的にはDProの方がやや簡単で解くこと自体は1周10-15分で終えられました。examappは中級編・上級編へと上がっていくに連れ時間もかかり、最初は解くだけでも30分前後かかった記憶です。
どちらのアプリも解説が充実しており、間違えた箇所を何度も読み込んでいました。受験前にはほぼ全問回答暗記しかけてましたが、問題は重要な論点に絞ってくれていたのでそれが理解を深めるのに役立ちました。
DProのテキスト部分も通勤電車で読み解き進めてました。時間制限なく、1章5-10で終えられる区切りで読み進め易かったです。
こちらは公式の『データ分析の教科書』とことなり、目的別で整理してくれていたので、スルスルと理解して行けました。(初学者の方はこちらから始めるのを強くおすすめします)
ただし、DProのテキストはpython環境構築や数学部分はほぼなかった(模試ではあった)ので、試験範囲を網羅するには『データ分析の教科書』も本番までに読んでおく方が良いと思います。(実務上もそれらの知識は役立つと思いますし。)
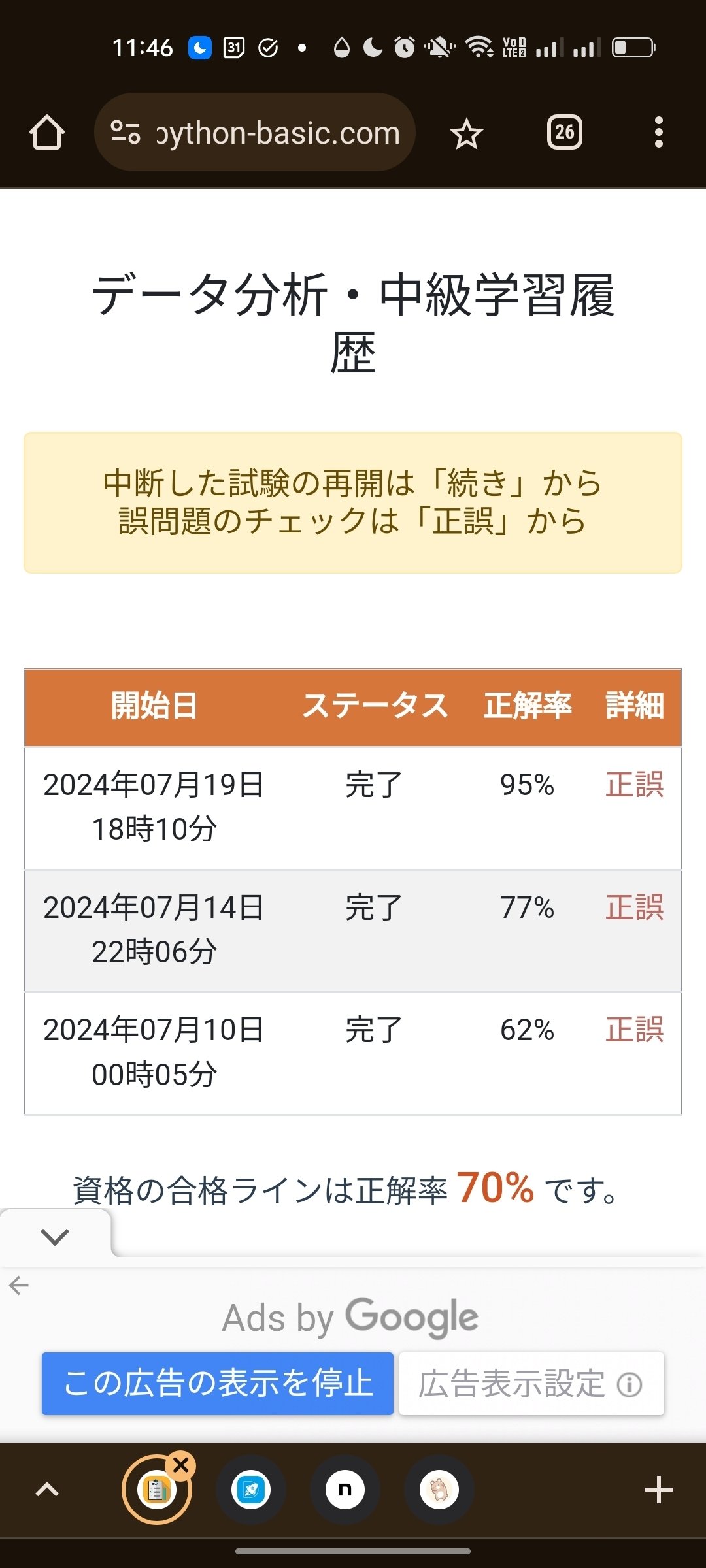
2つのアプリの模試受験履歴はこちらです。
※上3枚がexamapp、一番下がDProです。
※DProは直近5回のみ保存。
最初から解けてたわけではなく、(問題+回答を暗記し出してるのもありつつ)徐々に理解が深まって行くのがイメージ出来るでしょうか。
本番後の感覚も踏まえると、凡ミスがあっても8割5分以上安定して正解出来る水準に出来ておくと安心して合格狙えるのではと感じました。



本番試験の感覚
本番試験は学習開始から約2ヶ月後の時期に予約しました。私の場合は、その頃から別の試験対策をしないと行けないこともあり、そこに期限を定めました。
この試験はテストセンター受験でいつでも受験出来てしまうが故にともすればいつまでも億劫で受験出来ないことになりかねないとおもいます。(私も最初それで受験を躊躇ってました。)
教科書の通読や模試である程度合格の見通しが見えて来たら(模試なら7割得点出来そう くらいでしょうか)、思い切って申し込んで後は本番までに苦手分野を徹底して潰していくという思い切りの良さが大事と感じました。
本番の問題は、(公開NGなので詳細は触れられませんが)DPro模試やexamapp初級編〜中級編模試と同程度の難易度に感じました。
引っ掛けのような選択肢がいくつかあったので(行と列だけ記述違うなど)、そこは注意して読み返すのが良いと思います。
時間配分について、私は1周15分程で最後まで解き終えました。その後迷ってチェックを入れておいた箇所10問程度を見返し+最後に全問見返し(チェック入れてない箇所も冷静に読み返すと数問間違えてたのでこの確認は大事そう)まで終えて途中退室したのが開始後30分くらいでした。
複雑な計算はなかったので(数学の問題は計算能力というより基本的な公式理解の確認程度)、ある程度勉強して臨んだ方は時間に余裕を持って解答し終えられると思います。
試験結果
試験完了後その場で画面に試験結果が表示されて、結果レポートも印刷してもらえました。

全部で40問で得点1,000点なので1問25点のようです。
6問迷ってましたが、2問の間違いで済んでたようです。
学習の仕方で少々後悔してるのは試験学習中一度もpythonコードを書かなかったことです。テキストの内容全部写経してると時間いくらあっても足りないと思ってそうしてましたが、何度も間違える箇所(配列のアダマール積など)や区別が分かりづらい箇所(python標準とnumpyでのデータ型変換など)を書いて挙動見ておけばより効率良く理解したり本番で間違えなかったかもと感じました。
受験勉強で個人的に身になったと感じる論点
そんなわけで無事合格したわけですが、学習過程で今まで知らなかったり、理解が曖昧だった箇所の理解を深められたのは収穫でした。
pickleファイル
今までpythonでデータ加工するときは最終結果まで加工してcsv出力するか、ゼロからpyファイルを実行し直すかしかできないと思ってたので、Dataframeなどのまま保存出来る形式があると知れたのは実務上大きな収穫でした。
体系的に学習してると、独学で学習中は敢えて調べないと出くわさない領域も知ることが出来るのがメリットの一つと感じました。
オブジェクト指向の考え方
importしたクラスのインスタンス化
Matplotlibのfig >ax
オブジェクト指向についてはまだ完全に理解しきれてないですが(そのため理解が誤ってる部分もあるかも)、大カテゴリ>小カテゴリという包含関係がオブジェクト指向の一要素として重要そうと感じました。
行列の縦=行、横=列の感覚
そもそも縦横とっちかこれまで行列式を見るたびに混乱してましたが、模試で行列計算やDataframeなどの計算して感覚がつかめて来ました。
行→列なので、多くの処理でaxis=0が行で、1が列なんでしょうか。
またSQLを分析で使ってるだけだとほぼ意識しないインデックス(行方向)も理解し始められました。set_indexなどでプライマリーキーを保管しておくと機械学習の際にプライマリーキーの(正規化されてない)値の大きさで学習が阻害されずに済みそうです。
行列・ベクトルの内積とアダマール積の違い
前者はm行s列× s行n列=m行n列となり、縦横の最小公倍数が揃ってなくてもできるが、かける順番を変えると結果が変わる。
後者は同じ行列成分同士の計算で、行列が揃ってなくても、最小公倍数が合えばブロードキャストで計算される。
meshgridで縦横の座標上に値を振り直す感覚はこのアダマール積やブロードキャストの延長で理解出来た。
正規化の使い分け。
最小最大正規化は外れ値も含めて全ての値を0-1に収めたい(収めても良い)とな、標準正規化は外れ値は極端に外れてるままにしておきたいときに使う。
この使い分けは、df.describe()や箱ひげ図で値の分布を見れば判断し易そう。
受験全体を通しての感想
受験関連費用はそこそこ高かった(受験費用約1万円+公式テキスト約3,000円+DPro1ヶ月契約約1,000円)ですが、Pythonや機械学習実務の解像度が上がり有意義でした。
個人の経験としては、G検定で半ば頭でっかちに詰め込んだ知識を実務上どう使うかイメージ深められたのが特に大きかった。
第一線で仕事をされているデータサイエンティストの方には簡単な試験な気がしますが、これからデータサイエンスを仕事や趣味で取り組みたい方には最初期の取っ掛かりとして有効な気がします、
受験後の活動
受験当日、勢いを失わないうちに(アカウントだけは作っていた)kaggleのtitanicを始めてみました。
手探りで進めて合計半日ほどかかりましたが、DProなどの学習のおかげで全体観見据えた上で必要なことを調べつつ取り組め受験日のうちにsubmit出来ました。特徴量エンジニアリングの仕方など改善の余地はまだありますが、そもそも提出するための(pythonでの)データ加工の仕方が分からなかった所からは大きな進歩と思うことにしています。
他の課題については、まずは簡単な所から、Housing Priceなども手を付けて行きたいです。

また、今後は他の資格など余裕あるときにE資格も受験して行きたいと考え始めてます。Avilenの講座が学習コンテンツも充実して合格実績も高そうなので事前の研修はこちらで基礎を更に固めて受験したいです。
この記事が気に入ったらサポートをしてみませんか?