
読書ノート 統計学がわかる ハンバーガーショップで無理なく学ぶ、やさしく楽しい統計学

はじめに
「統計学がわかる ハンバーガーショップで無理なく学ぶ、やさしく楽しい統計学」通称ハンバーガー本を読了したので覚えておきたい内容を備忘録。
感想
大学生の統計学の授業で出会いたかった1冊。実際のハンバーガー店を例に統計学を使ってビジネスを動かしていく様子が分かりやすく描かれている。これは統計を使わなさそうな社会人も読んでほしい。
分析ツールが発達して統計を実際に使用するハードルは低くなっているものの、一番重要などの統計手法をどこで使用するべきかを把握できていないことが多い。この本はその根本の部分を例をとともに理解できるので、実際のビジネスの現場ですぐに統計学を実践できるところが非常に良い。
重要ポイントメモ
「他の店よりポテトの長さが短い?」
平均・分散・標準偏差
平均値は同じ、でもばらつきが異なる(分散・標準偏差)
分散=((データ-平均値)の2乗)の総和÷個数
標準偏差=(分散)の平方根
「ポテトは何本入っているの?」
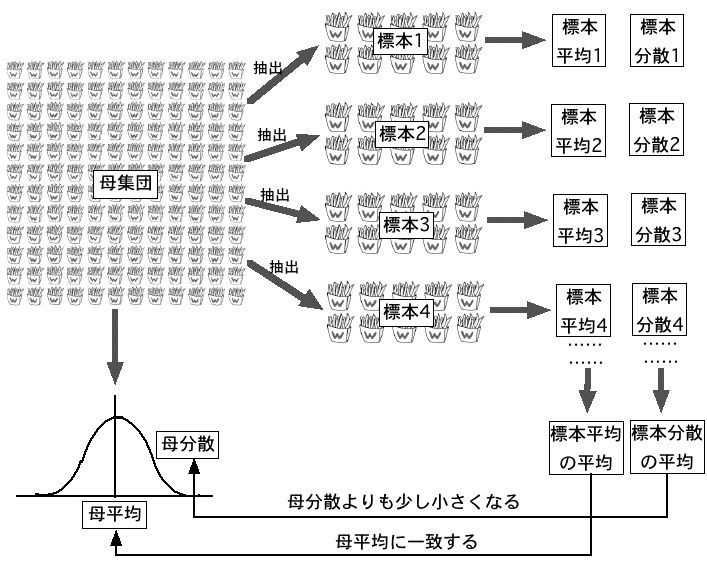
サンプリング:母集団の平均値と分散を標本から推定する
母集団の平均:標本平均の平均
母集団の分散:標本不偏分散の平均
不偏分散=((データ-平均値)の二乗)の総和÷(個数-1)
「推定値はどれくらいの精度?」
区間推定を行う
標本平均と母集団の平均の間に、誤差がどれほどあるかを考えるのが区間推定
誤差は、標本平均の分布のばらつき(分散)を考える。
標本平均の平均は、母平均に一致。
標本平均の分散は、母分散÷サンプルサイズ に一致。

標本の取得は1回として、信頼区間は下記のように求められる
信頼区間=標本平均±t×標本標準誤差
t: t分布表を参照。自由度(サンプルサイズ)から決定される
標本標準誤差 (SE: standard error)
= 標本平均の標準偏差
= (母分散 / サンプルサイズ) の平方根
= (不偏分散 / サンプルサイズ) の平方根
「チキンの売上がライバル店より少ない?」
帰無仮説「両店のポテトとチキンの売り上げ割合に差がない」を考える。
観測度数(実際の売上個数)と期待度数(チキンとポテトが同じ割合で売れるとした時の売上個数)を調べた上で、カイ2乗検定を行う
ばらつきの大きさを示す値
カイ2乗値=(((観測度数-期待度数)の2乗)÷期待度数)の総和
期待度数と観測度数が完全に一致すれば、カイ2乗値はゼロになる
逆に、不一致(ずれ)が大きくなれば、カイ2乗値は大きな値になる
カイ2乗分布とは、カイ2乗値と確率密度の関係をプロットしたもの。
確率密度とは、たとえば横軸3のところで切った右側の面積が「カイ2乗値が3以上になる確率」になるように決めたもの。期待値が小さくなるほど、カイ2乗値は大きくなる
自由度によってカイ2乗分布が決まる。
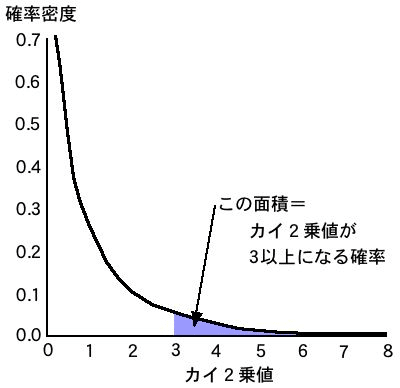
つまり、自由度が決まれば、5%の確率で起こる場合のカイ2乗値が求められ、その値より観測されたカイ2乗値が大きければ、「滅多に起こらないことが起きた」という事になる。
ちなみに自由度は(列の数-1)×(行の数-1)で求められる
「ライバル店より女子高生にウケていない気がする」
1人1つハンバーガーを食べてもらって点数をつけてもらう。
平均点の差をt検定(対応なし)して、差がないこと(帰無仮説)を調べる。
母集団の平均値に差がない=標本平均に差がない&標本平均の誤差にも差がないと考えることができる。

t=(標本平均の差)/(標本平均の差の標準誤差)
このtは、自由度(NA+NB-2)のt分布に従うことが知られています
自由度:(Aのサンプルサイズ-1)+(Bのサンプルサイズ-1)
差の分散は、AとBの標本平均の分散を足したもの。
AとBの母分散は同じと仮定する(推定母分散)
標本平均の差の標準誤差
=sqrt((Aの不偏分散/Aの標本数)+(Bの不偏分散/Bの標本数))
=sqrt((推定母分散/標本数A)+(推定母分散/標本数B))
推定母分散=(標本Aの平均からの偏差の平方和+標本Bの平均からの偏差の平方和)/((標本数A-1)+(標本数B-1))
つまり、
t=(標本平均の差)/sqrt(推定母分散×((1/標本数A)+(1/標本数B))
「ライバル店より女子高生にウケていない気がする」をもっと詳しく調べる
1人に2種類のハンバーガーを食べてもらって点数をつけてもらう
差をt検定(対応あり)で差がないことを調べる
t値の求め方が少し異なる。
t=(標本平均の差)/(標本平均の差の標準誤差)
標本平均の差の標準誤差
= sqrt(母分散/標本数)
=sqrt(不偏分散/標本数)
=sqrt(標本分散/(標本数-1))
t=平均の差/sqrt(標本分散/(標本数-1))
自由度:差のサンプルサイズ - 1
「2つ目のライバル店が出現、うちのポテトが一番美味しい?」
3社以上で比較する場合、t検定は使えない。
帰無仮説「3つのお店のポテトの評価の平均のどの組み合わせにおいても差はない」として、分散分析(F分布表)を行う。
分散分析表を埋める。
全体の平均からのズレ=群間のズレ+郡内のズレ
もし、群内のズレに比べて、群間のズレが大きければ、標本集団の間の違いが大きいということですから、「母集団の平均に差がない」という帰無仮説を棄却することになります。

群間の自由度=群の数 - 1
郡内の自由度 = (群1のサンプルサイズ - 1)+ (群2のサンプルサイズ - 1)+(群3のサンプルサイズ - 1)
全体の自由度 = 各群のデータを合わせたサンプルサイズ - 1
平均平方 = 平方和 ÷ 自由度
平方和:平均からの差を2条して足したもの(=分散*サンプル数)
F = 群間の平均平方 ÷ 郡内の平均平方

「クリスピーチキン・辛口チキン・辛口クリスピーチキンどれがいい?」
2要因の分散分析を使用する。
食感:クリスピー・普通の衣
味付け:辛口・普通味
上記の4つの組み合わせについてアンケートをとる。交互作用があるかどうかについて調べる。
帰無仮説:要因1による差がなく、要因2による差がなく、また交互作用による差もない
対立仮説:
Aの主効果だけが有意
Bの主効果だけが有意
交互作用だけが有意
Aの主効果とBの主効果が有意
Aの主効果と交互作用が有意
Bの主効果と交互作用が有意
Aの主効果とBの主効果と交互作用のすべてが有意
それぞれについてF分布表から判断
残差に対して、各要因によるズレが大きいかを検定していく
全体の平均からのズレ
=食感(要因1)によるズレ+味付け(要因2)によるズレ+交互作用によるズレ+残りのズレ(残差)
交互作用によるズレ=各群(4つの要素)の平均のズレ - 要因1によるズレ - 要因2によるズレ
残りのズレ(残差)=郡内の平方和を足したもの
要因1・2の自由度(群間の自由度):郡内の数から1を引いたもの
交互作用の自由度(群間の自由度):要因1の自由度×要因2の自由度
残差の自由度(群内の自由度):全体の自由度(サンプル数-1)- 要因1・2の自由度 - 交互作用の自由度
F = 平均平方 / 残差の平均平方

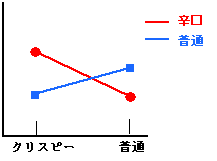
交差作用とは、平均値をプロットしたときに並行でないことを意味する

正規分布の特性
平均値±標準偏差×1で全体の68%
平均値±標準偏差×2で全体の95%
平均値±標準偏差×3で全体の99%
偏差値とは?
偏差値は、平均値を50、標準偏差を10になるように変換した時の値
偏差値60の場合、上位16%((100%-68%)/2)
偏差値70の場合、上位2.5%((100%-95%)/2)
となる。
おわりに
度々引用しましたが、内容がWebで公開されていたので、リンク貼っておきます!
この記事が気に入ったらサポートをしてみませんか?