
Filemakerで蔵書管理アプリ(その6)入力部分とブラウズ部分を切り分ける

2024.3.1追記
国立国会図書館サーチの仕様変更に対応して、巻末のダウンロードデータを更新しました。
久しぶりの更新です。ちょっと間が空いてしまったので前回どこまでやったか忘れ気味ですが、予定通りに管理アプリのチューニングについてです。
よりデータベースらしくチューニングする
前回までに作ったものは、見た目は専用アプリっぽくはなっていますが、内部の処理は大きなスプレッドシートに1行ずつ追加しているのと変わりはありません。データ自体はそれ以外にないのですが、誤って書き換えてしまったり、途中で入力をやめたものがゴミのように残っていたり、ということが可能性は低いとはいえ起こり得ます。「レコードの削除」をショートカットキー1発でできてしまい(そのときには削除したデータが何だったかわからなくなる)、そして(Cmd+Z)にあたるものがないので、可能性は低いとはいえども、そういった事故を起こりにくくするための工夫を加えていきます。
これらのことは、ストックした情報を後で使うときにも、使いやすいものになります。
データベースを堅牢にする
ストックしたデータをうっかり書き換えたり削除したりしないためには、アクセスは容易にできても、編集は容易にできないようにしておきます。現状では一つの大きな表しかなく、そこで追加も編集も削除もできてしまうので、新規追加用のフォーマットと、保管用の表が別々にある状態にします。新規追加用のフォーマットが1件分完成したら、それを保管用のバインダーに追加していくといえばイメージしやすいでしょうか。
以下のような流れになります。
1.新規入力用のフォーマットにISBNを入力する(バーコード)
2.入力されたISBNで国会図書館データベースを検索
3.検索結果から各項目を抽出し、新規入力用フォーマットの各項目に格納。
(ここまでは前回までに取り上げました)
4.入力されたものを「仮置き」として、手入力で修正を行う場合はここで行う。
5.決定したらその内容を保管用の表にコピーし、新規入力用のフォーマットは白紙に戻す。
これによって、直接入力するのは新規入力用のフォーマットのみで、保管用の表に直接手を加えることがなくなるので、不用意にデータを改変してしまうリスクは減ります。事後的に修正する必要はないものとし、また改めて取り上げます。
同じ内容のテーブルを2つ用意する
イメージは新規追加用のフォーマットと、保管用のバインダーですが、Filemaker上では同じテーブルが2つあり、片方はレコード0件で新規入力用、もう片方はこれまでに入力したものがストックされてる状態になります。
スタートは第4回で作成したデータです。(楽天ではなくNDLをベースに使いたいという個人的な願望によります)
データベースの管理画面を開き、これまでに作成したテーブル「ほん」を選択してコピー&ペーストしてできたテーブルをストック用として「蔵書」という名前のテーブルに、元々あったテーブル「ほん」を「新規入力用」にします。これを逆にしてしまうとスクリプトを書き換えないといけなくなります。

こうしてできた2つのテーブルをISBNでリレーションシップさせます。

コピーした方のテーブル「蔵書」のフィールドを設定していきます。各フィールドを自動入力「ルックアップ値」にチェックして、「新規入力」テーブルの同じフィールドを指定します。

この作業を、ISBNと計算フィールド以外の全てに行います。ISBNで自動生成されるリクエストURLは計算フィールドにし、計算式をコピーしています。「蔵書」テーブルのフィールドは以下のようになります。

ストック用の画面を新しく作る
これで、アプリ内にデータ格納する場所が整いましたが、まだ画面で見える状態になっていません。元々あったテーブルは新規入力用にしましたので、既ににあるレイアウトも新規入力用のレイアウトになります。つまり常に白紙が用意される状態にしなければならないので、ストックしたものを表示するために、「蔵書」テーブルに関連づけられたレイアウトが新たに必要になります。
同じ名前が行ったり来たりでややこしいので、先にレイアウトの名前を変更してしまいます。レイアウトの管理画面を開き、「蔵書」レイアウトを「新規入力画面」にし、複製します。複製してできたレイアウトを「蔵書」テーブルに関連付け、レイアウト名もそのまま「蔵書」に変更しておきます。

新たにできた「蔵書」レイアウトに配置されてる各フィールドは、「新規入力」テーブルの各フィールドが表示される状態になっていますので、「蔵書」テーブルの各フィールドに設定し直します。
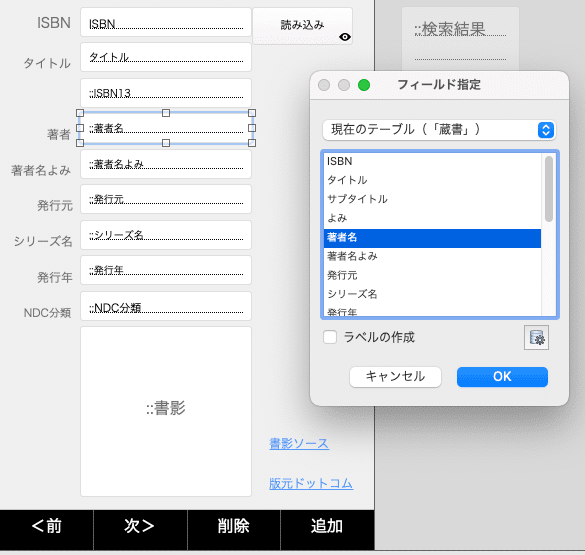
ドロップダウンで「現在のテーブル」を選択する。
このレイアウトでは新規入力は行わないので、「読み込み」ボタンと「検索結果」フィールドは削除してしまいます。それから、各フィールドの「フィールド入力」の欄にある、ブラウザモードのチェックを外しておきます。これで「蔵書」レイアウトでデータを改変してしまうことはほぼ不可能になります。
そして、右下の「追加」ボタンは「新規入力」レイアウトへの切り替えにとりあえず今は割り当てておきます。
逆に新規入力画面では、基本的にレコード数0もしくは1なので、「前」「次」ボタンは不要です。
入力のフローをスクリプトで半自動化する
これで、データを格納する環境が整いましたので、先に触れた入力のフローに従ってスクリプトにしていきます。各項目の取得までは前回までと同じですので、「新規入力」レイアウトの各項目が入力されていて、必要な修正を手入力で行なった状態からスタートしますので、必要なスクリプトは、
5.決定したらその内容を保管用の表にコピーし、新規入力用のフォーマットは白紙に戻す。
これだけです。「蔵書」テーブルのISBNに「新規入力」の内容をコピーしてやれば、他の項目はルックアップで自動入力されるので、それで入力完了。新規入力レイアウトに戻ってレコードを削除したのちに白紙を追加。これで次の入力ができるようになります。スクリプトにすると以下のようになりますが、1ステップずつマウスで操作する内容ですので、そんなに難しくはないでしょう。

これを「入力確定」という名前にして、右下の確定ボタンに割り当てます。ISBNが無い場合も考えられますので、タイトルを必須事項として、空欄の場合はスクリプトが作動しないようにifで制御しています。
今回はここまで。次回はストックされたタイトル一覧や検索など、データベースとしてより使うためのチューニングのことを書こうと思います。首を長くしてお待ちいただけますと幸いです。
追記:本記事のように、追加分とストック分で別のテーブルにすることなく、1つのテーブルで複数レイアウトを制御することで、同様の機能が実現できるのではないかと記事を公開してから考えてます。おそらく可能で、データとしてはシンプルになるはずですが、実際やってみないとどうなるかわからないので、別の機会に試してみようと思います。が、データの保全の観点では「別のテーブルにしておき、直接加工できないようにしておく」というのが確実だと思います。
今回も、作成したFilemakerアプリをこの下の有料部分でダウンロードできるようにしておきます。お手持ちのiPhoneでバーコードを読んで遊んでみてください。

この記事が気に入ったらサポートをしてみませんか?