モデリングする

研究課題を設定しました。さあ統計・・・とちょっと待ってください。
あなたの研究にはどんな側面があって、どういう構造をしているのでしょうか。これを明らかにしてわかりやすくモデルを作ります。こんな図のグラフィカルモデルとか。
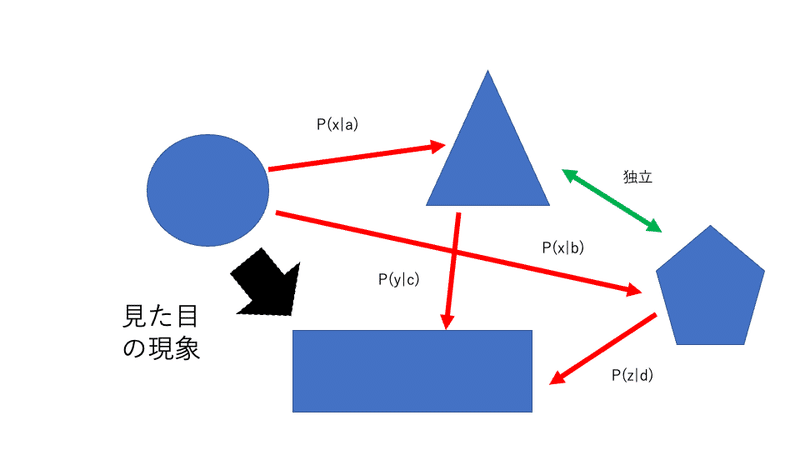
それぞれの関係を数理モデルにしていきます。図は適当です。ここが一番難しいかもしれません。●⇨■という現象があって、よく調べてみたら▲や☗を介して繋がっていたりとかいろんなことが分かるかもしれません。もちろん気がついてない他の要素が関係していることも多分にあります。
「ある病気でA薬を出した。効いた人にはみんなBの症状があった。」
ある病気・・・確定診断はついているのか。精度に問題はないか。
A薬・・・これは品質管理がどうこうというのはちょっと気が遠くなりますね。
薬を出された人・・・何人?男女差は?年齢差は?
効いた人・・・効くor効かないの2種類
Bの症状・・・ある人は通常、何割くらいいるのか?
例えば、B症状の人が5人くらいで、ない人が95人だとするとたまたま起こってる可能性もあります。男性に多いのかもしれませんし、年齢によって効きやすさが違うのかもしれませんし。
年齢、男女比が似たようなある病気のグループでA薬が効いた人、効かなかった人に分けることを考えます。
そうすると身体的なデータは差がない、A薬が効くかどうか、B症状があるorなしとなります。A薬が効くかどうかは二項分布に従いそうで、B症状のあるなしでも二項分布で良さそうです。二つの二項分布の同時性の確率を調べるχ二乗検定が使えそうです。年齢にばらつきがありそうだったらどうなるのでしょうか?年齢を調整しないで集めたデータは無限に集めると正規分布になると言われています(中心極限定理)。ただ、抜き取り標本と考えると集めたデータで最尤推定をすることになりそうです。0>の計測データなのでガンマ分布を使うことになるのでしょうか。
そうするとまずは一般線形化モデルで分析ができそうです・・・と複雑になっていきます。自分たちでとってきたデータというのは過去未来にわたって同じようなプロフィールを持つ無限の人の抜き取り標本と考えると最終的にはベイズ推定のようなものになっていきます。
こうした因果関係の階層構造を図にして行くことで何がどう関わっているのかをはっきりすることができます。逆に、この部分が曖昧だと何を言いたいか分からず後からデータを追加し続けてp値がp値がと徘徊する原因になりかねません。臨床研究は実用的な臨床的疑問に答える内容であるはずですからよく分からないp値を追い求めることになってはいけないわけです。行った検定の意味については臨床的な意義や背景にある分布の性質などよくよく吟味しないといけません。
モデリングについては次の参考書が有名です
●データ解析のための統計モデリング入門
●RとStanでベイズ統計モデリング
この記事が気に入ったらサポートをしてみませんか?