SNS研究者から見た都知事選〜ここがすごいよTTTC〜 #安野たかひろ

安野チームでブロードリスニングに携わっていたMです。普段はSNSデータ分析などの研究者をしております。
安野とは大学の研究室とサークルで同期でした。
この記事は何?
ここでは安野チームのブロードリスニングで使われていたTTTC(Talk to the City)というツールについて、解説や経験談を書こうと思います。
TTTCの概要は西尾さんのnote記事やScrapbox、TTTC公式ページをご覧ください。この記事ではもうちょっと別角度の話をします。
TTTCとは、簡単に言うと、人々の声を大規模テキストとして収集して、AIにうまいこと要約させてしまおうというツールだと筆者は認識しています。
アウトプット例はこちら↓。
ちなみに筆者は当初、TTTCの存在を西尾さんのSNS投稿を見て知っていたくらいでしたが、実際に使ってみるととても便利だという感想を持ちました*1。
記事を書くにあたっての想い
正直、TTTCのフローは複雑なため、この記事を書くのをためらっていました。しかし、安野の「誰でも私と同じようなキャンペーンをすることができるように」という理念のもと、やはり(難しくとも)記事に書き記しておくことが重要だと思い直しました*2,3。とにかく「今後TTTCでブロードリスニングすることに興味ある人に届いたら嬉しい」という想いです。
SNS分析を専門にしてきた筆者からしても、TTTCの技術やコンセプトは素晴らしいです。特に、大規模テキスト分析における生成AI*4の有用性については、非常に感銘を受けました。
このようなツールが今後も政治やビジネスにおける多くの場面で使われていくことを強く願っています。
要するに言いたいこと(TL;DR)
SNS分析は生成AIとの組み合わせで大幅に性能アップ
TTTCはSNS以外にも任意のテキストで分析できるので汎用性が高い
生成AIによる文意抽出のポテンシャルはすごい
安野がリーダーだからこそできた高度な分析の実活用
TTTC分析の6ステップ
TTTCのアウトプットページの下部までスクロールをすると、下図スクショのような6つの分析ステップと、使われたコード・プロンプトが公開されているのを見ることができます。

この6つのステップ(1.抽出〜6.概要)は、さらに以下の3つにまとめて考えることができます。
a. 生成AIによる前処理(1.抽出)
↓
b. 大規模テキストのクラスタリング(2.埋め込み&3.クラスタリング)
↓
c. 生成AIによる後処理(4.ラベリング&5.まとめ&6.概要)
ここで、aとcは生成AIを使う部分で、bは生成AIを使いません。そしてbは伝統的なSNS分析の手法でもあります。
これを見たときに筆者は、b(テキストクラスタリング)にaとc(生成AIによる前処理と後処理)をつけることで、TTTCはSNS分析を生成AIで大幅にパワーアップしているものなのだと捉えました。
そのため、まずコアであるbのテキストクラスタリングのお話からします。知っている方や興味のない方は読み飛ばしてください。
大規模テキスト分析の技術と、実用の問題点
みなさんもどこかで大量のテキストをうまく要約したいと思ったことはないでしょうか。SNSのデータもそうですし、Googleフォームで集めた問合せやアンケートの記述欄など、現代のビジネスで大量のテキストデータに触れることは珍しくないかもしれません。
しかし、テキストが1000件を越えようものなら、それらを読み込むのもどうしても大きな労力がかかるものです。そこで、それらの大量テキストをAIに要約・可視化させてテキストの理解を促進しようという発想が出てきます。この着想を得たときにまず候補に上がるのが「テキストの情報圧縮」*5と「クラスタリング」の組み合わせです。
クラスタリング
まずクラスタリングの話をします(実際は情報圧縮→クラスタリングの順番に行います)。
クラスタリングとは、データ間の類似度に基づいて似たものを集めてグルーピングをする手法で、教師なし機械学習の一種です。
例えば、スーパーの顧客の購買データがあるときに、顧客をグルーピングしたいとします。そこでまず、顧客一人ひとりを「購買頻度」や「一回あたりの購入代金」、「購買タイミング」などに基づいた空間にプロットします。そして、その空間にプロットしたデータ群にクラスタリングアルゴリズムをかけると、「高ロイヤリティ顧客」「大口顧客」「セールス狙い顧客」等々に自動で分かれてくれることが期待されます(実際は結果を見ないとわかりません)。
このように、データは一つ一つの何かしらの特徴を持っており、その特徴に基づいてデータ間の類似度が計算できるのでれば、大量のデータ群をなんとなくのグループに分けることができます。
実際に上であげた例のように、クラスタリングはマーケティングの分野でも顧客セグメンテーションに使われたりする技術です。
詳しい話は神嶌先生のクラスタリングの資料がとてもわかりやすいので、気になった方はご一読をおすすめします。
情報圧縮
上記のクラスタリングは便利な技術ですが、それをテキストのような非構造化データで扱うためには、一度対象となるもの(ここではテキスト)をベクトル化する必要があります。そうでなければコンピュータが上手く扱ってくれません。
テキストの単純なベクトル化の手法にはBag-of-Wordsというものがあります。これは、テキストを単語レベルに分解したあと、テキスト本体をそれらの単語で作られた空間にプロットするものです。ここでベクトルの数値にはテキスト内の単語の出現頻度を入れます。
例えば「私は猫が好きです」といった文章は、「私」「猫」「好き」といった単語の空間で(1,1,1)といった表現ができると思います(名詞と動詞だけ扱う場合)。
しかし、Bag-of-Wordsの問題点は、大規模テキストだと空間が広くなりすぎることです*6。1単語で1つの軸を構成してしまうと、大規模テキストでは何十万、何百万といった軸(=単語)で構成された空間が作られてしまい、通常のコンピュータは効率的に演算を行ってはくれません。そのため、一度上手く圧縮してあげることが求められます。
最近の機械学習技術では、この圧縮手法が特に優れています。それは、一度超大量のテキストデータで学習した学習済みモデルを使うことで、テキストをだいたい1000次元くらいにうまいこと圧縮してくれます*7。1000次元くらいなら今の一般的なコンピュータの機能なら効率的に扱えます*8。この圧縮を、この文脈では「埋め込み」と呼んでいます。
このあたりのお話は、岡崎先生の解説がわかりやすいので、気になった方はご一読をおすすめします。
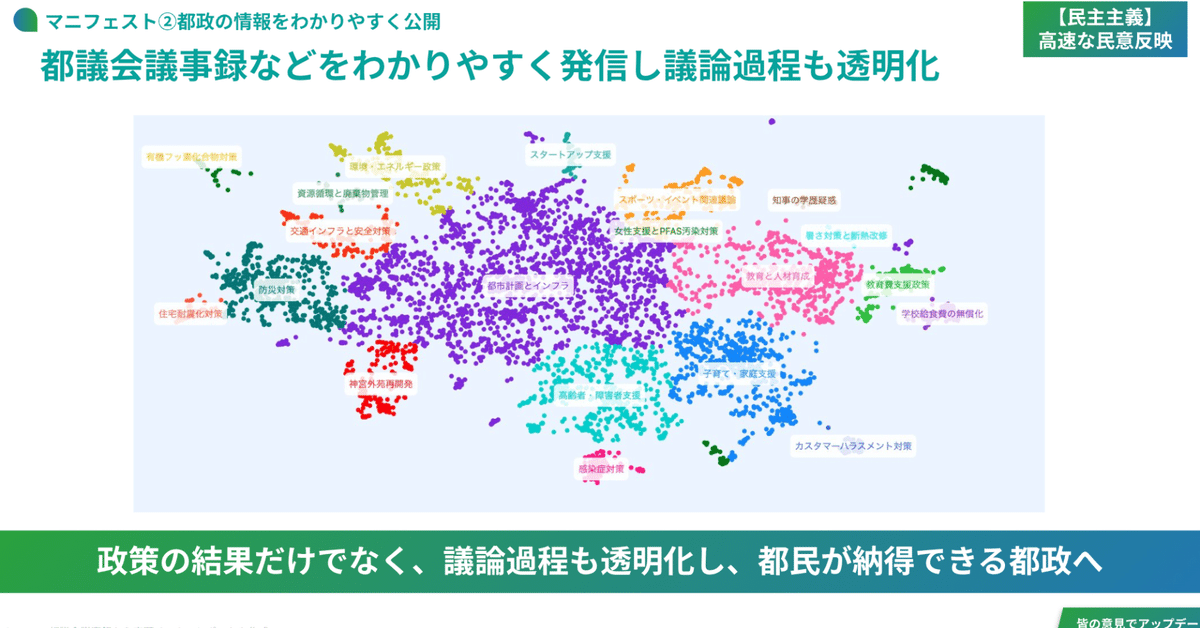
これにより、下図のような図が作成されます。点一つ一つはもともとテキストであり*9、色はクラスタリングした結果です。このような情報圧縮(埋め込み)→クラスタリングの組み合わせは、大規模テキストの分類に近年よく使われています。

実用上の問題点1. 解釈に労力が必要
ただ、これらのテキストクラスタリングは問題がいくつかあります。まず、クラスタリングにより大規模テキストをグルーピングしたとしても、クラスタの解釈のためには結局クラスタ内のテキストを一つ一つ読んで、そのクラスタの概要を掴まなければならないからです。これは特にクラスタリングに慣れてない人からすると大変な作業になります。
この問題を、TTTCでは、クラスタのラベリングを生成AIにすべて任せるということで解決しています。しかも、ラベリングをする際に、他のクラスタとの違いが際立つようにラベリングするプロンプトを組み込むことで、より解釈性の高いラベリングを実現しています。
さらに、各クラスタのラベリングのあと、クラスタの要約とレポート生成までも一気通貫で生成AIが行っています。これらの後処理により、これまで大きな労力がかかっていたクラスタリング分析を格段に効率的にしてくれています。近年の生成AIの発展により、TTTCと似たような発想はあったかもしれませんが、実際に一気通貫でUIまで備えて公開しているツールは筆者は知りませんでした。
実用上の問題点2. SNSテキストはノイズが多い
そしてもう一つ問題が、テキストという非構造化データ、しかもSNSのテキストには本当に(×3)様々なノイズが含まれるという点です。
例えば、不定形な日本語や新しい顔文字などで文章が構成されている場合や、多くの主張が一つの文章に含まれている場合などは、最新のAIでも上手くテキストの情報処理をしてくれません。ビジネスの現場でSNSの解析やポジネガ分析が上手くいかない場合は、これが大きな理由の一つだと思います。
これも、TTTCは生成AIでなんとかしてました(これは一番筆者は驚きました)。何をしているかというと、生成AIに、前処理として各テキストの文意を要約・抽出させているのです。例えば複数の主張がテキストに入っていた場合は、元のテキストを複数のテキストに分解しています。また、長くて読み取りが難しいテキストでも、一番の主張のみをうまく抽出できます。これらの前処理により、ノイズの多いSNSテキストも上手くコンピュータが扱える形に変換して、クラスタリングの精度を上げることができます。このような自動要約・抽出は、生成AIだからこそできた技術だと思います*11。
生成AIによる前処理
6ステップのうち1.抽出の部分です。概要については上記の「実用上の問題点2」で少し述べましたが、ここではもう少し細かい実体験的な話をします。
以下が生成AIに与えたプロンプトです。これは、まずオリジナルのプロンプトを日本語化し、その後少し改変したものです。
まず、TTTCが日本語の文章に対応してくれるか若干不安でしたが、プロンプトを日本語化してからテキストを入力してみると、その時点である程度うまく出力してくれることがわかりました(感動しました)。
その後の改変ポイントは大きくは2つで、/system で与えている背景を今回の文脈に合わせたこと。もう一つは、/human 以下で与えているfew shotの実例を必要に応じて加減したことです。
/system
あなたはプロのリサーチ・アシスタントで、私の仕事を手伝うことがあなたの仕事です。
私の仕事は、論点を整理したきれいなデータセットを作成することです。
背景は、私がX上であるハッシュタグ#TOKYOAIを通じて寄せられた声でどのような論点が出ているかを抽出したいということです。
これから、ソーシャルメディアサイトXにおける#TOKYOAIを含むポストを渡します。
これから与える投稿をより簡潔で読みやすい意見にするのを手伝ってほしい。
ポストを要約する際の事例を挙げます。
本当に必要な場合は、2つ以上の別々の意見に分けることもできるが、1つのトピックを返すのが最善であることが多いだろう。
要約が難しい場合は、そのままの文章を返してください。
結果は、きちんとフォーマットされた文字列形式(strings)のJSONリストとして返してください。
/human
気候変動を考慮したさらなる風水害対策の強化について、都の具体的な計画をお伺いします。
/ai
[
"気候変動を考慮したさらなる風水害対策の強化してほしい。"
]
/human
豪雨対策全般の基本方針の検討を進める中、具体的にどのような施策を作ってほしい。
/ai
[
"豪雨対策全般の基本方針の具体的な施策を作ってほしい。",
]
/human
AI技術は、そのライフサイクルにおける環境負荷の低減に重点を置いて開発されるべきである。
/ai
[
"私たちは、AI技術が環境に与える影響の軽減に焦点を当てるべきである"
]
/human
AIの能力、限界、倫理的配慮について一般の人々を教育するための協調的な努力が必要である。
/ai
[
"AIの能力について一般の人々を教育すべきである。",
"AIの限界と倫理的配慮について、一般の人々を教育すべきである。"
]
背景の変更がどれくらい結果に作用したかはわかりませんが、適切な事例を与えることの重要性は感じました。実際にあったこととして、「いいね」とか「あとで読む」「読んだ」などの(おそらく)短すぎる投稿を要約するときに、こちらが与えた例文を文脈に関係なく返してしまうハルシネーションが起きていたので、「あとで読む」などはそのまま返すようにプロンプトに明示的に(例として)組み込んだりしていました。
ハルシネーションの対応は主にプロンプトの工夫で補っており、ハルシネーションが見当たらなくなるまで何回かプロセスを回す処理が必要でした。
生成AIによる後処理
後処理(4.ラベリング&5.まとめ&6.概要)では特段プロンプトの大きな変更を(日本語化以外)していませんでした。詳細が気になる方は実際のプロンプトをアウトプットのページからご覧頂ければと思います。
唯一筆者が変更したのは、(後段で述べるように)「主張」ではなく「提案・要望」を抽出する際は、ラベリングのプロンプトで使われている事例のテキストを提案・要望「風」に変更していました。
TTTCのメリット・デメリット(まとめ)
ここまではTTTCの詳細や使い方を述べてきましたが、ここでは改めてメリット・デメリット・その他疑問を述べようと思います。
汎用性
大規模テキストデータであればどんなテキストでも対応可能です。
実際我々も、SNSテキスト以外ですと、
・ニュースサイトへのコメント
・過去の都議会議事録
・YouTube動画へのコメント
などでTTTCを行っていました。
便利さ
分析→レポーティングまでを一気通貫で行ってくれるのは本当に便利だと感じました(改めて)。
プロンプトの柔軟性
オリジナルのプロンプトではテキストから「主張」を抽出するようにプロンプトが作成されていましたが、今回それを少し変えてみました。
具体的には、Xの投稿から「要望・提案」のみを抽出するように試してみたところ、全体としてよりクリアな結果を得ることができたと思います。
また、都議会の議事録でTTTCを行ったときは、都議会の論点把握のため、議員からの「質問」のみを自動で抽出するようにしました。
このように、生成AIによる文章要約は強力であり、特にピンポイントで欲しい情報のみを抽出することが可能だと思います。筆者は特にこの点で特にTTTCのポテンシャルを感じました。
発展性
今回使ったTTTCはscatterバージョンのみでしたが、機能としてはturboのバージョンもあります。turboはよりクラスタ内部のテキストを調べやすくなっているバージョンです。これは今回時間の関係上使えませんでした。つまり我々(というか筆者)はまだまだTTTCのポテンシャルを引き出しきれておりませんでした。さらに今後もTTTCは良い感じな可視化機能がさらに開発されていきそうな機運があるそうです。今後に期待です。
困った点
たまに挙動がおかしい
やはりハルシネーションはゼロにはできません。なので、結果を逐一確認し、プロンプトなどで対応していく必要があると思います。特に結果を公表する際には気をつけました。(公表せずに内部で活用するだけならば、データはUI上で確認できるので、完璧を求めなくてもいいかもしれません)。
ラベリングがおかしい
これはハルシネーションとは若干違う話で、TTTCでは固有名詞は集めたデータに基づいて判断されます。なので集めたデータが間違っているとラベリングも間違います。具体的には、ニュースサイトのコメントでTTTCしたとき、他の候補者の名前を間違っているコメントがあり、TTTCもそれに基づいてクラスタのラベリングをしてしまったことがありました。そのような例は(結果を公表する場合は特に)気をつけなければならないと思います。
完全な自動化は難しい
TTTC→結果をそのまま公開というフローを当初は理想としていましたが、中々難しかったです。上記のラベリングの例もそうですが、どうしても目に付く間違いをおかすことがあるため、最終的に分析者が目で見る必要があります。一回の実行も即座に終わるわけではなく、gpt-4oで1000テキストですと20分程度、10000テキスト以上だと1時間かかることもありました*12。さらに、内容を正しくするためにプロンプトをいじって何回かテストをする必要があるため、一つ一つのレポートの作成にそこそこの時間は現状かかりそうです。
不思議だった点
これはものすごい細かい話なのですが、TTTCのクラスタリングにはBERTopicが使われています。そのため、HDBSCANを使っているものだと筆者は勝手に考えていたのですが、コードをよく見るとHDBSCANではなくスペクトラルクラスタリングが使われていました。
これはおそらく、HDBSCANだとどうしても外れ値のテキストを捨てることになるということや、クラスタの数をなるべく均等にしたいという思いがあったのではないかと思います。(もしくは誤コミットの可能性)(ちゃんと検証していません。)
最後に
この記事ではTTTCの技術的側面を多く取り上げましたが、それ以外に(とても)大事なことを述べます。
テクノロジーで誰も取り残さない東京
TTTCは要約のツールですが、大きな声ばかりを反映させるツールではありません。あくまで大量のテキストを要約・可視化することで、すべて見やすくするためのサポートツールです。実際、政策チームの方々は作られたTTTCを読み込んで(散布図の点をポチポチしながら)政策への反映を考えていました(これ自体も大変なことだと思います。筆者としては今後もっとうまくサポートできるような方策を考えたいと思いました)。これにより、通常なら拾いきれない声も、拾える可能性が大きく高まると思われます。
安野だからこそ活用できた技術
ここまで書いて伝わったかもしれませんが、TTTCはかなり最先端のツールです。このようなツールを自身の大一番で活用できたのは、安野が技術をわかっている人間だからではないかと思います。安野には様々な場面で「副知事の方がいいのでは」という声が寄せられていたそうですが、実際技術がわかる人間がリーダーでないと、良いツール(特に新しいデジタルのツール)を組織として活用するは難しいのではないかと、今回改めて実感しました。とはいえ、TTTC自体(もしくはそれに類する技術)に関して述べると、今後も世間の理解が進むことで普及していき、政治やビジネスの場で使われていくことを祈っています。
安野とチーム、みなさんに感謝
SNS研究者として、TTTCのような技術が日本の選挙で使われるとは思ってもませんでした。いち研究者として、現場でこういう技術の活用をさせてくれた安野には感謝です。また、あくまで研究者だった筆者はあまり共同作業やデプロイに慣れておらず、チームの方(特に西尾さんやなのくろさん)にはとても助けていただきました。。そして、今回のブロードリスニングという試みは、陣営だけが画策しても意味のあるものではありません。実際に声を寄せてくれた皆様がいたからこそ、この双方向性のある選挙活動が実現できました。分析を担ったものの一人として、すべての環境に感謝致します。ありがとうございました。
以下補足
*1: 筆者は6月7日に安野から「TTTCでどんどん人々の声を可視化してほしい」という依頼をいただき、そこからTTTCを触り始めました。
*2: pentaさんの記事にも触発されました。
*3: 難しいとはいえ、それでもわかりやすくなるようトライはしてみました。わかりにくかったら筆者の力不足ですすいません。。
*4: この記事ではLLMをすべて「生成AI」と呼んでいます。
*5: 実務や研究では「圧縮」ではなく「次元削減」と言うと思いますが、今はわかりやすさのために「圧縮」と呼んでいます。
*6: 広くなるだけでなく、スパースになることも問題です。
*7: 次元数はモデルによってバリエーションがあり、数百次元のものもよく見ますし、今回のOpenAIのembeddingの場合は、約3000次元のものを使用しています。
*8: 実際はテキストではなく、まず単語を1000次元くらいで表現してからその単語ベクトル情報に基づいてテキストを表現しています。
*9: 実際にTTTCにおいては点はテキスト本体ではなく、テキストから抽出した文意・主張などです。一つのテキストから複数の文意・主張が抽出されること(もしくは一つもされないこと)はありえます。
*10: 実際は可視化のために、1000次元ほど(今回は3000次元)のベクトルを、2次元にさらに圧縮しています。
*11: 例えば複雑な文章におけるポジネガ分析をより精緻にする試みとしてAspect-based sentiment analysisなどの技術が研究されてきておりますが、筆者の知る限り、高い精度には届いていないという印象です。
*12: バッチ処理による高速化で改善の余地はあるかもしれません。