G検定 SVM / サポートベクターマシン

株式会社リュディアです。今回はサポートベクターマシン (SVM : Support Vector Machine) についてまとめてみたいと思います。
G検定公式テキストにも書かれているように「SVMは高度な数学的理論に支えられ、ディープラーニングが考えられる以前は機械学習で最も人気のある手法の 1 つ」でした。
G検定対策としては以下の内容を理解しておけば 十分です。
各データ点との距離が最大化、つまりマージン(余裕)が最大化されるように境界線を求めることでパタン分類を行う
特にマージン最大化というキーワードが重要です。詳細は不要なのでキーワードだけ、ということであれば上記内容でも良いのですが少し勿体ないと思う方は続きもよんでください。
SVM は教師あり学習の 1 手法で分類や回帰に用いられる手法の 1 つです。具体的な処理内容を見てみましょう。
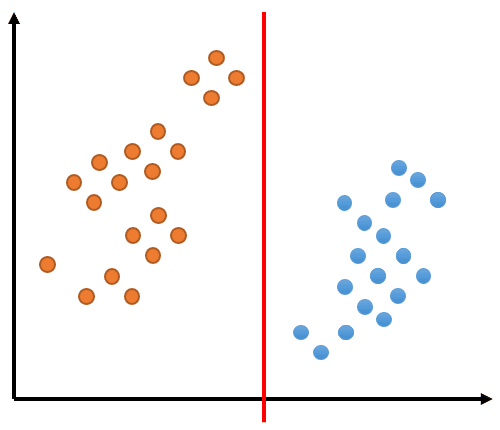
学習データのデータ点を表すオレンジの点と青の点が以下のように分布しているとします。これらを 1 本の直線で分割することで分類を実現するとします。図中の赤い線で分類できることがわかりますね。
次の図をみてください。同じように分類されていますが何が異なるでしょうか?同様に赤い直線でオレンジ色の点と青い点が分類されていますが直線の角度が異なります。
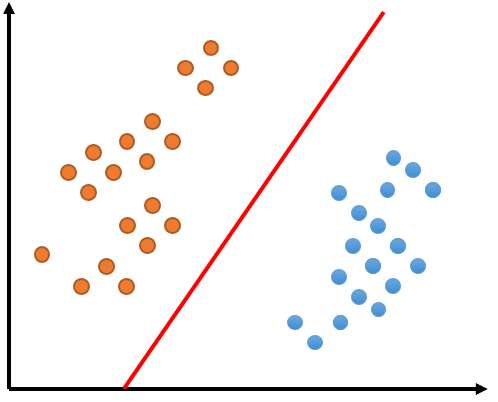
赤い直線と赤い直線の周辺にあるオレンジや青の点との距離の合計が大きくなってる感じがしませんか?ポイントは赤い線の周辺にある点に特化していることです。このように境界付近の分類する際にきわどいデータ点のことをサポートベクトル (Support Vector) と呼びます。このサポートベクトルに着眼して分類する手法がサポートベクターマシン SVM です。
上の 2 つの絵を並べてみましょう。赤い直線とデータ点のうちきわどいデータ、つまりサポートベクトルとの距離を緑で記載しています。左図ではきわどいデータに対する距離が小さく、右図では大きくなっている、つまりマージンが最大化されています。

複数のデータ点がきわどくなる境界部分のマージン最大化した分類が可能な直線を決めることで、実データに含まれるきわどいデータ点の誤判定を少なくする手法が SVM の本質です。また直線と点の距離を扱う数学は高度に洗練されており数学的背景もしっかりしています。少なくとも最小二乗法は知っておいてください。
今回は単純化した SVM についてまとめてみました。G検定の問題に対応するレベルであれば十分だと思います。
では、ごきげんよう。
この記事が気に入ったらサポートをしてみませんか?