
【翻訳】ソルバーの仕組み【セオリー】GTOWブログ.35

GTOソルバーとは、可能な限り最良のポーカー戦略を計算するアルゴリズムである。しかし、これらのソルバーは一体どのように動作するのだろうか?何がその戦略を「最善」にするのだろうか?
この記事では、ソルバーがどのように動作するのか、何を達成するのか、そしてその限界について深く掘り下げていく。
ゴール
その前に、以下の3つの記事から始めてみよう。この記事はソルバーがどのように機能するのかを深く理解するためのもので、基本的な前提知識がないと圧倒されてしまうかもしれない。ソルバーが初めての人は、まずこれらの記事を読んでから、この記事に戻ろう。
GTOの目的は、エクスプロイト不可能なナッシュ均衡戦略を達成することだ。
ナッシュ均衡とは、どのプレイヤーも一方的に戦略を変えることで良い結果を得ることができない状態のことである。つまり、各プレーヤーが戦略を公表すれば、どのプレーヤーも戦略を変更するインセンティブがなくなるということだ。これはしばしばポーカー戦略の「聖杯」と表現される。しかし、これはソルバーが意図するところではない。実際、ソルバーは「ナッシュ均衡」の意味すら知らない。
ソルバーは単にEVを最大化するアルゴリズムである。
ソルバーの各エージェントは1人のプレーヤーを表す。そのプレイヤーのゴールは一つであり、ゴールはただ一つ『お金を最大化すること』だ。問題は、もう一方のエージェントが完璧にプレーしていることだ。これらのエージェントに互いの戦略を対戦させると、互いの戦略をエクスプロイトし合いながら、どちらも改善できない地点に達するまで、行ったり来たりを繰り返す。この点が均衡となる訳である。
GTOは、搾取的なアルゴリズム同士を、どちらもそれ以上向上出来なくなるまで戦わせることで達成される。
GTOの解法
各プレイヤーに一様なランダム戦略を割り当てる(各決定ポイントにおける各アクションの可能性は等しい)。
ゲームツリー全体を通して、各ハンドの失敗した戦略(相手の現在の戦略に対するEV損失)を計算する。
対戦相手の戦略が固定されたままであると仮定して、損失を減らすために1人のプレイヤーの戦略を変更する。
ステップ2に戻って失敗した戦略を再計算し、損失を減らすように相手プレイヤーの戦略を変更する。
これをナッシュまで繰り返す。
これらのサイクルを反復と呼ぶ。必要な反復回数は、ツリーの大きさやサンプリング方法によって、数千回から数十億回まで様々である。
ステップ1)ゲーム空間を定義する
《入力》
直接解くにはポーカーというゲームは複雑すぎる。計算可能にするためには、サブセットと抽象化を使ってゲーム空間を縮小する必要がある。
一般に、ソルバーを実行するには、以下のパラメータを定義する必要がある:
ベッティングツリー。
求められる精度。
開始ポットとスタックサイズ。
スタートレンジ(ポストフロップソルバー)。
ボードカード(ポストフロップソルバー)。
カードバケットやNNsなどのポストフロップカードの抽象化(プリフロップソルバー)。
レーキやICMのような変数の修正。
《ベッティングツリーの複雑さ》
ゲームツリーのサイズを小さくするために、利用可能なベットサイズを定義する必要がある。アルゴリズムの仕組みに入る前に、「ベッティングツリー」がどのようなものか理解する必要がある。ソルバーは提供されたパラメータ内で動作する。ソルバーに非常に単純なゲームツリーを与えると、それほど複雑でない戦略が生まれるが、ソルバーはゲームツリーの制限をエクスプロイトすることに留意して欲しい。
ソルバーは、指定されたベット構造内で可能なすべてのラインを含む「ツリー」を生成する。ツリー全体の各決定ポイントには「ノード」が含まれる。例えば、⅓ポットサイズのベットに直面しているOOPは一つの「ノード」である。ツリー内のノードの数は、ツリーの大きさを定義する。そして、各ノードは最適化される必要がある。
以下の画像のような極めて単純なツリーですら、最適化しなければならない個々のノードが696,613個ある。

GTOウィザードが使用するような、以下のようなより複雑なツリーには87,364,678個のノードが含まれる。

見ての通り、複雑さはツリーを指数関数的に成長させる。上の複雑なツリーは、ノードあたり4~5種類のベットサイズを使用しているが、ノードは125倍も大きく、解くのも難しい。そして、これはまだ真のゲーム空間を大幅に単純化しているのだ!
ソルバーの最も難しい課題の一つは、現在のテクノロジーの制約内で堅固な戦略を生み出すためのベッティングツリーを最適化することだ。ツリーがあまりにも大きくなると、そのサイズのために解決が不可能になる。逆に、ツリーがあまりにも小さくなると、ソルバーがそのツリーの制限を悪用し始める。私たちはポーカーを研究しやすくするために、簡略化されたベッティングツリーを見つけるアルゴリズムに取り組んでいる!これらのソリューションは、各シチュエーションに最適なサイズを見つける。
GTO Wizardには、最大19サイズまでの複雑なソリューションや、数サイズしかないシンプルなソリューションなど、さまざまなタイプのソリューションがある。最終的には、複雑なツリーから始めて、出現頻度の低いラインを削除してより小さく、管理しやすいツリーに整理するのがベストだと考えている。
《ノードロック》
GTO Wizardは、2023年にノードロックとリアルタイムソルバーの追加を計画している!この強力な機能は、探索的な戦略と根本的な因果関係の原則を探るために使用される。
ノードロックは、ゲームツリー内のあるノードで一方のプレイヤーの戦略を固定するプロセスである。これにより、そのプレイヤーに特定のプレイ方法を強制する。ノードロックは一般的に、探索的な戦略を開発するために使用される。たとえば、フロップでのレンジベットを強制すると、相手のプレイヤーはその戦略を最大限にエクスプロイトする。ただし、ノードがロックされる前後で両プレイヤーが戦略を調整するということを覚えておくことは重要である。フロップのノードをロックすることで、ターンとリバーの戦略も変化する。
ソルバーに悪いプレイを強制すると、ダメージを最小限に抑えるために前後のノードを修正する。
単一のノードをロックし、ソルバーがその不足を補うように作業するプロセスは「最小限のエクスプロイト戦略」として知られている。全体のツリーにわたる何らかの欠陥をモデリングしているのではなく、特定のツリーのポイントだけを考慮している。
より複雑なノードロックも可能である。たとえば、特定のコンボの戦略だけを1つのノードでロックできるソルバーもる(他のコンボは戦略を調整できる)。多くのノードをロックして、相手の戦略の大きな傾向を再現しエクスプロイトすることも可能だが、現代のツールは効果的にマルチストリートのノードロックに対応していない。
ステップ2)ツリーを解く
さて、ゲームツリーを定義した。次はそれを解く番だ!まず、ソルバーがどのように戦略の期待値を計算するのかを理解する必要がある。
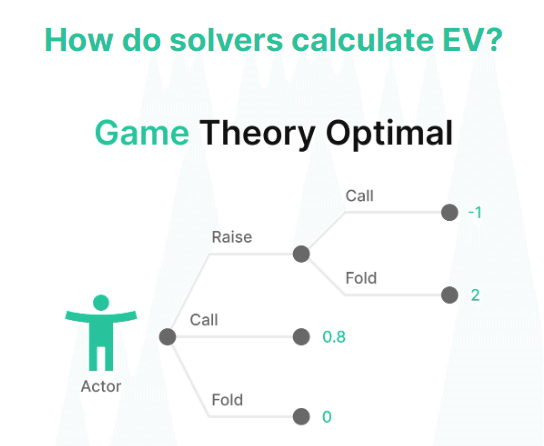
上のゲームツリーを思い浮かべてみよう。それぞれの点はノードまたは決定点を表す。各ノードで各ハンドがどれだけのEVを生み出すかを知るにはどうすればよいだろうか?
そのプロセスは(コンピュータにとっては)簡単だ。まず、ターミナルノード(別名リーフノード)を定義する。これは、誰かがフォールドしたり、ハンドがショーダウンになったりして、ハンドが終了したポイントである。
各ターミナルノードには確率(p)と値(x)が割り当てられる。レンジ内の各ハンド(i)は、各ターミナルノードに到達する確率とその確率で生成される値を別々に持つ。各ターミナル・ノードの値と確率を掛け合わせ、それらを合計して合計期待値を求める。各ノードのEVは、勝ったポットの合計から、そのポットに投資した金額を引いたものとして定義される。
戦略のペアから始める。
我々の戦略と対戦相手の戦略に基づき、我々のハンドが各ターミナルノードに到達する頻度(p)を計算する。
各ターミナルノードの値をxとする。
各ターミナルノードのx*pの合計が期待値(EV)になる。
この計算を、すべてのノードにおけるすべてのハンドについて行う。

ソルバーはこの計算をほとんど瞬時に行うことができる。ソルバーが登場する前は、CREVのようなプログラムがEVの計算に使われていた。その限界は、ユーザーが各ノードで戦略を定義しなければならなかったことだ。そのため、通常、後のノードを純粋なエクイティ計算に簡略化していたが、これは極めて不正確だった。
GTOウィザードの各ポイントで、すべてのハンドのEVを観察することが出来る。例えば、これはNL50キャッシュゲームでのBTN対BB SRPである。各ハンドの全体的な期待値を見ることができ、個々のハンドの上にカーソルを置くと、取り得る様々なアクションのEVが表示される

Regret(後悔)
まず、対戦相手の戦略が固定(不変)であると仮定することから始める。その後、ゲームツリー全体で可能なアクションごとに上記で説明した期待値(EV)計算を実行する。そして、各ポイントで最も高いEVの決定を選択し、ターミナルノードから逆算して最初の意思決定ポイントからのさまざまなアクションのEVを計算する。
さて、各ノードでの各ハンドの価値はわかった。では、どうすれば戦略を改善できるだろうか?ここで「regret(後悔)」の概念が登場する。regretを最小化することは、すべてのGTO(ゲーム理論最適)アルゴリズムの基礎である。最もよく知られているアルゴリズムの1つは「CFR(counterfactual regret minimization)」である。Counterfactual regretとは、ある戦略をプレイしなかったことをどの程度regretするかの指標である。例えば、フォールドした後で、コールした方がずっと良い戦略だったとわかった場合、コールしなかったことを「後悔」することになる。数学的には、ある行動をとることによる利得または損失を、そのハンドにおけるその決定ポイントでの総合的な戦略と比較して測定する。
Regret = Action EV – Strategy EV
たとえば、現在の手札の戦略が1/3の確率でフォールド、コール、およびAIすることであり、それぞれのアクションの期待値(EV)が(フォールド = 0bb、コール = 7bb、ショーブ = 5bb)であるとしよう。その場合、現在の戦略の期待値は以下の通りだ:
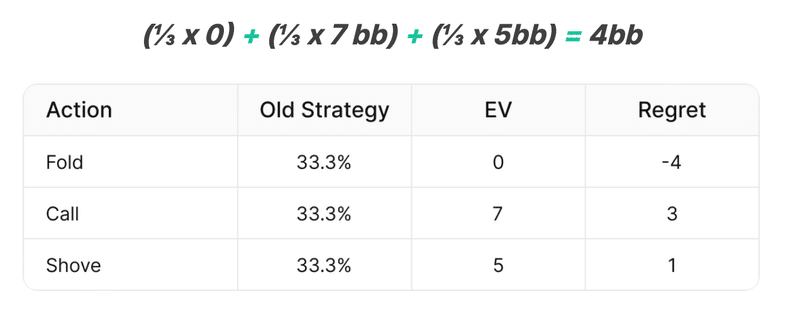
フォールドのregretはマイナスであり、平均的な戦略よりも損をすることを意味する。
コールとAIのregretはプラスであり、現在の戦略よりも優れていることを意味する。
次のステップは、regretを最小にするように戦略を変えることである。
最も明白なアプローチは、すべてのハンドで、各決定ポイントで最もEVの高いアクションを単純に選択することである(別名、最大搾取戦略)。上記の例では、常にコールすることになる。問題は、相手が戦略を変える可能性があることで、ループに陥る可能性がある。
例えば、プレイヤーAがリバーでアンダーブラフをかけ、プレイヤーBがブラフキャッチャーを全部フォールドすると、プレイヤーAがずっとリバーブラフをかけるようになり、それに対してプレイヤーBが全部コールすると、プレイヤーAがリバーブラフをやめる、というサイクルが繰り返されるかもしれない。各プレイヤーは、各反復で最善の対応策に全面的に切り替えるのではなく、その方向に一歩ずつ穏やかに戦略を調整することができる。これにより、ループにはまる問題が解決され、戦略ペアが均衡に近い場合にはよりスムーズに収束する。
代わりに、CFR(Counterfactual Regret Minimization)を使って戦略を更新する事が出来る。前の例に戻ろう。ネガティブなregretを持つアクションはプレイされなくなる。ポジティブなregretを持つアクションは次の式を使用する:
New strategy = Action Regret / Sum of positive regrets
この例では、コール→3/(3+1)=75%、オールイン→1/(3+1)=25%となり、フォールドは負のregretがあるため0%となる。

これは1回の反復に過ぎないことに注意。このプロセスを何度も繰り返すうちに、戦略はどちらのプレイヤーも改善できない点に近づき、ナッシュ均衡が達成される。
Accuracy(正確さ)
解の正確さはナッシュ距離で測られる。まず、ひとつの疑問から始めよう:
プレーヤーBの現在の戦略を最大限エクスプロイトした場合、プレーヤーAはどれだけ勝てるだろうか?
コンピュータはすでにregretを知っているので、これは簡単に計算できる。プレーヤーAの現在の戦略のEVと、彼らの最大搾取戦略のEVの差は、彼らのナッシュ距離を表す。この数値が小さければ小さいほど、搾取されにくく、正確な戦略であることを意味する。
ソリューションの正確さを知るために、すべてのプレイヤーのナッシュ距離の平均を取る。
これらの正確なナッシュ距離の測定は、各反復で戦略全体を列挙する場合にのみ機能する。ほとんどのプリフロップのソルバーは抽象化やサンプリング手法を使用しており、これらの計算は実用的でなく不正確になる。HRCやMonkerのようなソルバーは、戦略やregretが各反復でどれだけ変化するかを測定して収束を推定する。
GTO(Game Theory Optimal)戦略は、ナッシュ距離がポットの1%以下になると収束し始める。この閾値を超えると、戦略は非常に混合し、信頼性が低くなる。ほとんどのプロは、ポット0.5%未満よりも精度が低いソリューションを受け入れがたいと考えている。
GTOウィザードは、ソリューションの種類にもよるが、開始ポットの0.1%から0.3%の精度で解く。ゲームツリーが複雑になればなるほど、似たようなベットサイズを区別するために、より高い精度が要求される。似たようなベットサイズは似たようなペイオフになるため、ベットサイズが多く複雑なゲームツリーほど、収束させるために高い精度が要求される。
Convex(凸型)ペイオフ空間
この反復的なアプローチが機能するかどうか、また局所的な最大値にはまる可能性があるかどうかをどのように知るのかについて、ポーカー全般に関しては「双線形サドルポイント問題」(bilinear saddle point problem)として説明されることがある。ペイオフ空間は以下のようなものに見えることがある:

x軸とy軸の各ポイントは戦略ペアを表す。各戦略ペアには、両プレーヤーがすべてのランアウトにわたるスポットでレンジ全体をどのようにプレーするかについての情報が含まれている。
高さ(z軸)は戦略ペアの期待値を表し、ポイントが高いほど一方のプレーヤーにとってEVが有利であり、ポイントが低いほど他方のプレーヤーにとって有利であることを表す。
ほとんどのソルバーは、Counterfactual Regret Minimization (CFR)と呼ばれるプロセスを使用する。このアルゴリズムは、2007年にアルバータ大学のMartin Zinkevichによって発表された論文で初めて発表された。その論文では、CFRアルゴリズムがある局所的な最大値で行き詰まることはなく、十分な時間があれば均衡に達することを証明している。
このサドルの中心はナッシュ均衡を表している。このグラフ上で、曲率のない点は、どちらのプレイヤーも戦略を変更してペイオフを向上させることができない点を示している。
さらに詳しく知る
以下は、ポーカーにおけるCFRについてさらに詳しく学ぶためのおすすめの資料である
この記事を読むことを強くお勧めする。: ポーカーにおけるCFRについての詳細な情報が得られる。
このウェブサイトは、シンプルなCFRアルゴリズムを構築するための素晴らしいチュートリアルとステップバイステップの手順を提供している。
Deep CFR(Deep Counterfactual Regret Minimization): ニューラルネットワークを使用してCFR計算を高速化するアプローチ。
Discounted regretの最小化によるオリジナルのCFRアルゴリズムの改良。
結論
ふぅ、たくさんの情報だった!ソルバーが実際にどのように機能するのか、だいぶ理解できたのではないだろうか。主なポイントをまとめてみよう:
すべての実用的な目的のため持ち帰るべき収穫は、ソルバーが私たちが提供するゲームツリーを利用するEV最大化アルゴリズムであるということである。
ソルバーアルゴリズムは最大エクスプロイト戦略を生成する。これらのアルゴリズム同士を対戦させると、エクスプロイト不可能な均衡戦略が生成される。
戦略のペアの期待値を計算するのは(コンピュータにとっては)簡単なことである。戦略を正しい方向に微調整し、このプロセスを何度も反復させる事が難しい部分である。
ポーカーは直接解くには複雑過ぎるので、ベットサイズを限定するなどの抽象化技術を使ってゲーム空間を単純化する。
ソルバーは、あなたが与えた抽象的なゲームと同じ精度しか無い。複雑すぎると解くことが不可能になり、人間がそこから学ぶことも難しくなる。単純すぎると、ソルバーがゲームツリーの限界をエクスプロイトすることになる。
・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・
記事は以上になります。最後まで読んでいただきありがとうございました。
この記事を読んで良いと感じて頂けましたら、noteのスキ、やSNSでの拡散、Twitterのフォローやサポートをして下さりますと本当に執筆の励みになります!
この記事が気に入ったらサポートをしてみませんか?