
【生成AIと著作権】生成AIを活用した検索サービスによる著作権侵害!?

本稿のねらい
2024年7月17日、一般社団法人日本新聞協会は、「生成AIにおける報道コンテンツの無断利用等に関する声明」(本声明)と題する主張と要求を公開した。
本稿は、本声明の内容を整理し、本声明の主張や要求について是非を述べるというのではなく、本声明を題材にして、特に生成AIを活用した検索と著作権の論点に焦点を当てて筆者なりの考え方を示すことを目的とする。
本声明の整理
本声明が問題視しているのは次のとおり大きく2点であり、1つは著作権侵害、もう1つは競争法上の懸念についてである。(//以下は筆者の独り言)
なお、1点目の著作権侵害の点については、概ね著作権法第47条の5に関するものであると思われるが(整理が不十分な気がする)、一般社団法人日本新聞協会が、文化審議会著作権分科会法制度小委員会(第3回)に提出した資料や文化審議会著作権分科会法制度小委員会「AIと著作権に関する考え方について(素案)」に対して出したパブリックコメントを参考にすると、なんとなくいわんとすることはわかる気がする。著作権法第30条の4に関する主張は取り下げ、同法第47条の5を主戦場とするようである。
①著作権侵害
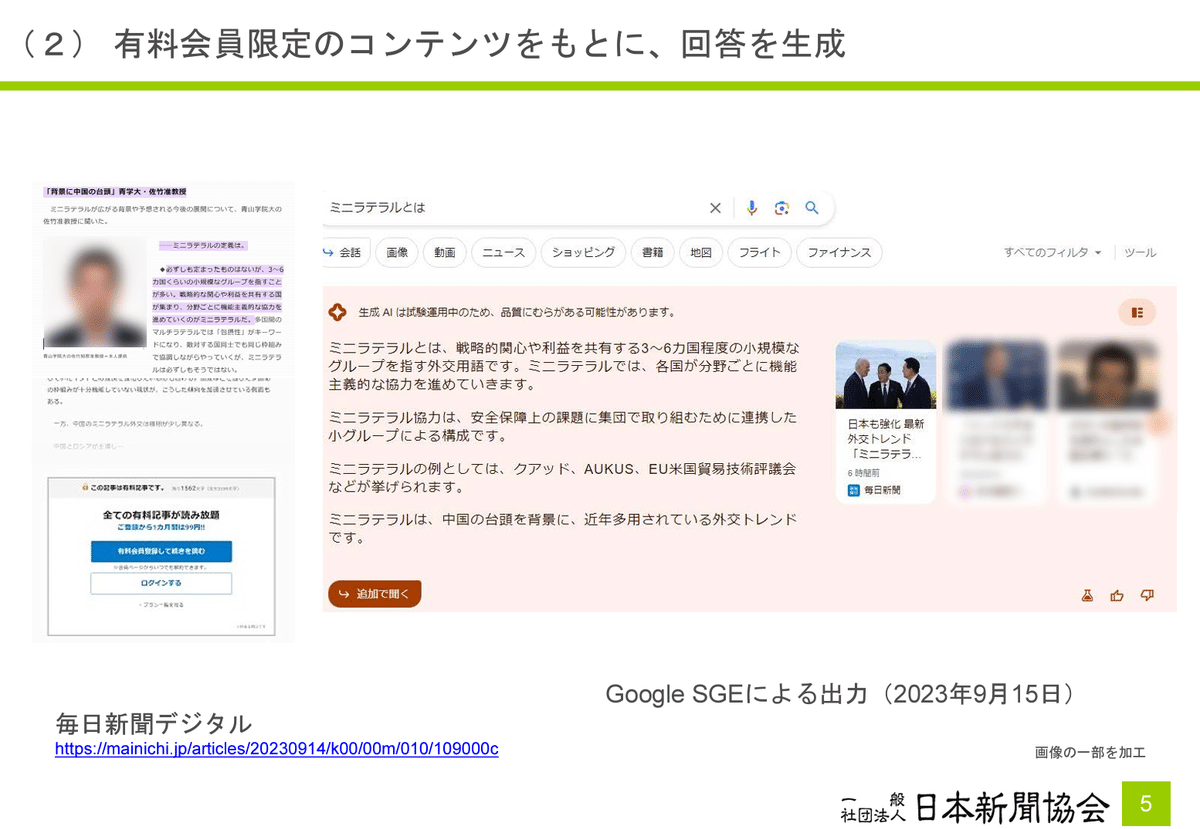
MicrosoftやGoogle等のウェブ上の検索に連動させてAIが回答を生成するサービス(検索連動型の生成AIサービス、検索拡張生成=RAG)が「報道コンテンツ」を無断で利用
//「報道コンテンツ」に著作権等知的財産権があることは前提(なお、著作権法第10条第2項)
//misappropriation理論?
//無断で利用すること自体が直ちに違法(著作権侵害)を構成しない
検索連動型の生成AIサービスが報道コンテンツの記事に類似した回答を表示することが多い
//生成物による報道コンテンツの著作権侵害(類似性・依拠性)が論点か
検索連動型の生成AIサービスが報道コンテンツの記事を不適切に転用・加工し事実関係に誤りのある回答を生成する
//著作者人格権の1つである同一性保持権(著作権法第20条)の論点か
//生成AIのような機械は創作的要素を必要とする「翻案」は行い得ない
//報道機関の「信頼」は知的財産法では保護されないだろう
参照元の複数の記事の"本質的な特徴"を含んだ「軽微な利用」とは到底言えない長文の回答を生成、提供するケースが多数みられる
//著作権法第47条の5第1項の「軽微利用」の論点か
//"本質的な特徴"は何に影響する?
多くのユーザーが生成された回答で満足し、参照元のウェブサイトを訪れない「ゼロクリックサーチ」が増え、報道機関に著しい不利益が生じることは容易に推測できる
無許諾での検索連動型の生成AIサービスは無料記事サイクル(無料記事の閲覧に応じた広告収入やニュースポータルからの収入が別の記事の再生産に投資されるサイクル)を破壊する
//著作権法第47条の5が権利制限根拠とする本来的な販売市場等への影響の問題か(軽微性又は同条第1項但書の論点か)
【参考】著作権侵害?

※思い切り誘導してる

【参考】検索連動型の生成AIサービスとして念頭に置かれているもの
【参考】パブコメでの意見
素案は、こうした技術的な措置が講じられ、情報解析に活用できるデータベースの著作物が将来販売される予定があることが推認される場合には、この措置を回避して当該サイトからAI学習のための複製等をする行為は、データベースの著作物の将来における潜在的販路を阻害するとして、法第30条の4における権利制限の対象にならないことが考えられるとの見解を示した。条件付きながら、新聞社等のサイトから、AIの開発事業者やサービス提供事業者がデータを許諾なく収集することに一定の歯止めをかける解釈を示したものと理解しており、その点は評価できる。
※ただし、この「評価」は誤解というか自らに都合よく考えすぎた独自解釈であり、事務局(文化庁著作権課)により「本考え方は、単に販売予定である場合ではなく、AI学習のための著作物の複製等を防止する技術的な措置が講じられており、かつ、このような措置が講じられていることや、過去の実績(情報解析に活用できる形で整理したデータベースの著作物の作成実績や、そのライセンス取引に関する実績等)といった事実から、当該ウェブサイト内のデータを含み、情報解析に活用できる形で整理したデータベースの著作物が将来販売される予定があることが一定の蓋然性をもって推認される場合について記載しているものです」と訂正されている。
RAGによるサービスが大手プラットフォーム事業者を中心に広がる中で、実際にRAGによる生成物で軽微利用の程度を超えるような事例が多発していることは、看過できない。生成AIの開発事業者やサービス提供事業者は問題を放置せず、事態の改善を急がねばならない。
②競争法上の懸念(優越的地位の濫用)
検索サービスの市場がほぼ独占状態にある
この状態を前提として、生成AI事業者が報道機関の許諾を得ないまま報道コンテンツを利用することは独禁法に抵触する可能性がある
//優越的地位の濫用?
//著作権云々よりは競争法を主戦場にした方が筋が通る気がする
RAG
RAGとは
RAGとは、Retreval Augmented Generationの略であり、大規模言語モデル(LLM)に検索システムを組み合わせることでLLMの機能を拡張しパフォーマンスの高い生成を可能にする仕組みをいう。

RAGは、上記のとおりLLMの機能を拡張し補完するものであり、生成AI(LLM)の弱点・課題を解決することに資する。
つまり、生成AIは、膨大な数のデータにより学習したLLMを用いてテキスト等を生成する優れた能力をもち、大抵の場合、ユーザーからの質問(クエリ)に対し高速で的確かつ流暢な回答を生成することが可能であるが、次の2つの弱点・課題が存在する。
回答を生成するために使用される情報は、LLMを訓練するために使用された情報に限定され、(a)データが相当程度古く更新されない可能性があることに加え、(b)LLMを利用するユーザーが必要とする個別具体的な情報が含まれていない
あくまで学習済みのデータの中から、提示されたプロンプトに応じ、ある言葉の次に続く可能性の高い言葉を予測・分析して並べ、文章を作成しているに過ぎない(NTT東日本「RAGとは?仕組みと導入メリット、使用の注意点をわかりやすく解説」)
これら2つの弱点・課題により、ユーザーからのクエリに対して文脈を無視するような不適当な回答やハルシネーション(hallucinations)のような不正確な回答を生成してしまうリスク(⇛生成AIへの信頼性を毀損するリスク)を抱えている。
RAGは、モデル自体に変更を加えず、クエリへの回答のために必要となる情報(のみ)を用いてLLMのアウトプットを最適化することに資する。RAGの対象となる情報には、最新のものや特定の組織・業界に特化したものなど、質・量ともに正確性の高い回答を得るための情報を含めることができる。
これにより、生成AI(LLM)は、ユーザーからのクエリに対し、よりコンテキストに適した回答を提供できることになることが期待されている。
【参考】RAGの定義について
RAGの仕組み
次のRAGの仕組みの説明は、NTT東日本「RAGとは?仕組みと導入メリット、使用の注意点をわかりやすく解説」や、Elastic「検索拡張生成(RAG)とは?」を参考としている。
RAGは、上記のとおりクエリに対する回答を生成するLLMに検索システムを組み合わせたものであるから、次のとおり検索と生成という2要素(2段階)の仕組みにより構成されている。
検索フェーズ
① ユーザーが生成AIに質問(クエリ)を入力
② 生成AIが外部情報を検索し、適したデータを収集
③ 検索結果データを取得しベクトル化等処理
④ クエリとの関連性に基づき検索結果データにランク付け
検索フェーズでは、ユーザーの質問に対して最適な回答ができるよう、ウェブページ・ナレッジベース・データベース等の外部情報を検索してデータを収集する。
この際の検索システムについては、セマンティック検索(ベクトル検索)やハイブリッド検索(ベクトル検索&キーワード検索)が用いられる。
【参考】RAGにおける検索システムについて

生成フェーズ
⑤ ユーザーのクエリと④で取得した検索結果データを組み合わせる
⑥ ⑤をもとに生成AIがプロンプトを入力
⑦ ⑥で入力されたデータをもとにLLMが回答を生成
⑧ 生成AIが、LLMから取得した回答をユーザーに出力

本声明は「ウェブ上の検索に連動させてAIが回答を生成するサービス」を「検索連動型の生成AIサービス」と呼称しているが、検索に連動するのはすべてのRAGに共通する特性であり、本稿では生成AIウェブ検索サービスと呼称する。
ともあれ、生成AIウェブ検索サービスは、上記RAGの仕組み「検索フェーズ」における②「生成AIが外部情報を検索し、適したデータを収集」というプロセスにおける検索対象がパブリック/オープンなウェブページであり、その検索に連動させて生成AI(LLM)が回答を生成するサービスを意味する。
他方、上記RAGの仕組み「検索フェーズ」②の「生成AIが外部情報を検索し、適したデータを収集」というプロセスにおける検索対象がプライベート/クローズドなデータベースであり、その検索に連動させて生成AI(LLM)が回答を生成するサービスもある。
両者をあわせて「RAG活用生成AIサービス」と呼ぶ。
【参考】RAGの仕組みについて


【参考】生成AIウェブ検索サービスの例
Perplexityは、インターネット上の情報を迅速に見つけて要約することができる賢い友達のようなものです。質問をすると、通常の検索エンジンのように整理するためのリンクのリストを提供する代わりに、高度な人工知能を使用して正確に質問内容を理解します。
その後、たくさんのウェブページや記事を検索して、最も関連性のある情報を抜粋します。しかし、本当に素晴らしいことはここにあります - Perplexityはその情報をすべてまとめて、まるであなたと会話をしているかのように平易な言葉でわかりやすく答えてくれます。
RAG活用生成AIの著作権法上の整理
RAG活用生成AIサービスを含む生成AI(LLM)については、次のとおり、データベースの開発・学習段階の論点と生成・利用段階の論点があり、生成AIと著作権という文脈ではお馴染みである。

ただし、生成・利用段階の目的から逆算し、開発・学習段階における非享受目的が否定されるという謎現象(*)が生じ得ることからすれば、開発・学習段階と生成・利用段階を区別する論理的な必然性はなく、便宜上の区別に過ぎないともいえる。
*一応、「事実認定において、生成・利用段階における事情が、開発・学習段階においてAI学習のための複製を行う者の享受目的の有無を認定する上での間接事実として考慮されうることをお示ししたもの」とされているが(「AIと著作権に関する考え方について(素案)」に関するパブリックコメントの結果についてNo.156)、説得的ではない。

なお、Microsoft Copilot(旧Bing AI)、Google SGE、perplexityのような、生成AIウェブ検索サービスの場合、クエリに応じてウェブページの検索を行い、その中からLLMがアウトプットを生成することになると思われ、この場合、生成AIウェブ検索サービス(特にperplexity)はMicrosoftやGoogleの検索システム(これ自体は著作権法第47条の5第1項第1号・第2項により適法)を利用し、RAG用のデータベースは作成していないことになると思われ、開発・学習段階の論点は原則として生じない。
Perplexity AI is an AI-powered 'answer engine' that aims to deliver precise, contextually relevant, reliable and helpful information in response to user questions.
Launched in 2022, the free version draws on OpenAI's GPT-3.5 and Microsoft's Bing search engine to find relevant information to a question, and uses advanced natural language processing (NLP) techniques to understand and generate an answer.
The paid version, Perplexity Pro, asks the user clarifying questions to refine queries and provides access to GPT-4, Claude 3.5, Mistral Large and Llama 3.
In May 2024, Perplexity launched Pages, which generates a customisable webpage based on user prompts. Pages uses Perplexity’s AI search models to gather information and create a Wikipedia-type page that can be published and shared with others.
ご指摘の箇所については、生成AIと著作権の関係で、開発・学習段階においては、学習済みモデルの作成のためのAI学習(事前学習又は追加的な学習)の場面とは別に著作物が用いられる場面として、昨今、RAG等において生成AIに入力するためのデータベースを作成するために既存の著作物の複製等が生じる事例が見られることから、生成AIと著作権の関係を網羅的に検討するために取り上げているものです。
こういった事情もあり、本声明は著作権法第30条の4ではなく、同法第47条の5を主戦場としているのだろう。
開発・学習段階
一般的には、AI(学習済みモデル)作成のための学習や、生成AIを用いたソフトウェアやサービスの開発に際して、次のような著作物の利用行為が生じる(AI と著作権に関する考え方について(令和6年3月15日)18頁)。
AI学習用データセット構築のための学習データの収集・加工【複製】
基盤モデル作成に向けた事前学習【複製】
既存の学習済みモデルに対する追加的な学習【複製】
検索拡張生成(RAG)等において、生成AIへの指示・入力に用いるためのデータベースの作成【複製】

この点、AIが学習用データを学習するなど上記利用行為は、「情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うこと)」(著作権法第30条の4第2号)に該当し(デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方10頁)、「当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合」(いわゆる非享受目的)(同条柱書)に該当するとされている(AI と著作権に関する考え方について(令和6年3月15日)19頁)。
なお、著作権法第30条の4の規定振りは、権利制限の対象となる行為について柱書において明確に規定した上、各号において「法の安定性を確保する観点や予測可能性をより高める観点から、当該行為に該当する典型的な場合を例として掲げている」(デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方17頁)のであって(「次に掲げる場合その他の」という規定から明らか)、例示列挙の一項目に過ぎない「情報解析」に該当するかどうかが重要なのではなく、非享受目的に該当するかどうかが重要である(同8頁参照)。
また、著作権法第30条の4の文理解釈上(「当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない…」)、享受目的が併存している場合には権利制限の対象とはならない。
上記利用行為は、いずれも基本的には非享受目的のみで享受目的が併存することはないが、RAGに関して「既存のデータベースやインターネット上に掲載されたデータに含まれる著作物の創作的表現の全部又は一部を、生成AIを用いて出力させることを目的として、これに用いるため著作物の内容をベクトルに変換したデータベースを作成する等の、著作物の複製等を行う場合」は享受目的が併存すると評価され得る(AI と著作権に関する考え方について(令和6年3月15日)20頁)。
仮に一定の利用行為に享受目的が併存すると評価される場合、当該利用行為は著作権法第30条の4による権利制限の対象とはならないが、同法第47条の5の軽微利用による権利制限の対象となる余地は残されている。
【参考】作風や画風を真似る生成AI?
AI と著作権に関する考え方について(令和6年3月15日)によれば、「生成AIの開発・学習段階においては、このような特定のクリエイターの作品である少量の著作物のみからなる作品群は、表現に至らないアイデアのレベルにおいて、当該クリエイターのいわゆる「作風」を共通して有しているにとどまらず、創作的表現が共通する作品群となっている場合」もあり、「このような場合に、意図的に、当該創作的表現の全部又は一部を生成AIによって出力させることを目的とした追加的な学習を行うため、当該作品群の複製等を行うような場合は、享受目的が併存する」とされているが(同21頁)、開発・学習段階でのいわば事前規制をかける必要はあるのだろうか。
当該開発・学習により作成された生成AIから生成・利用される生成物について、著作権侵害を考えればいいのではないだろうか。
例えば,著名な画家の画風を真似るAIを開発するために,著名な画家の作品を機械学習する行為は,当該画家の作品という多数の著作物からそれらを構成する視覚的表現の特徴を抽出して,調べるものであり,「情報解析」に当たる.
(Ⅰ) 著作権者第30条の4該当性
著作物利用の目的
次の記載にあるように、RAGに利用するためのデータベースを作成するための、既存のデータベースやインターネット上に掲載されたデータに含まれる著作物の内容をベクトルに変換する行為に伴い、著作物の複製等が生じ得るところ、これが著作権法第30条の4の権利制限の対象となるかどうかは、当該データベースの作成に用いられた既存の著作物の創作的表現を出力することを目的とするかどうかによる。
検索拡張生成(RAG)その他の、生成AIによって著作物を含む対象データを検索し、その結果の要約等を行って回答を生成する手法(以下「RAG等」という。)については、これを実装しようとする場合、開発・学習段階において、生成AI自体の開発に伴う学習のための著作物の複製等のほかに、既存のデータベースやインターネット上に掲載されたデータに含まれる著作物の内容をベクトルに変換したデータベースを作成する等の行為に伴う著作物の複製等が生じ得る(中略)
既存のデータベースやインターネット上に掲載されたデータに著作物が含まれる場合でも、RAG等に用いられるデータベースを作成する等の行為に伴う著作物の複製等が、回答の生成に際して、当該データベースの作成に用いられた既存の著作物の創作的表現を出力することを目的としないものである場合は、当該複製等について、非享受目的の利用行為として法第30条の4が適用され得ると考えられる。
既存のデータベースやインターネット上に掲載されたデータに著作物が含まれる場合であって、著作物の内容をベクトルに変換したデータベースの作成等に伴う著作物の複製等が、生成に際して、当該複製等に用いられた著作物の創作的表現の全部又は一部を出力することを目的としたものである場合には、当該複製等は、非享受目的の利用行為とはいえず、法第30条の4は適用されないと考えられる。
この点、RAG活用生成AIサービスは、まさにLLMの弱点・課題であるユーザーのクエリへの回答に必要な情報を増やし回答の「正確性」(*)を高めることを意図するものであり、そのため、ユーザーは、特定の既存著作物の創作的表現を出力することを意図するかどうかは別論、特定の既存著作物に含まれる情報を参照した出力することを求めているし、かつ、それを出典等ソースを併記することで示して欲しいとすら思っている。
*「正確性」といっても、当該追加された情報をもとに回答されること(エビデンスベースであること)を一定担保しているだけであり、当該追加された情報自体の正確性(客観的正確性)は何ら担保されない。
したがって、RAG活用生成AIサービスにおいて享受目的を否定するのは骨が折れそうではあるものの、場合を分ける必要があると考える。
つまり、繰り返し説明しているとおり、RAGの目的は、次のリスクを回避するためクエリへの回答のために必要となる情報をLLMに与えて「正確性」を高めるところにある。
ユーザーからのクエリに対して文脈を無視するような不適当な回答を生成してしまうリスク
ハルシネーション(hallucinations)のような不正確な回答を生成してしまうリスク
このような「正確性」を追求するニーズが特に強い分野に関するRAGと、必ずしもそうではないRAGに二分し、前者についえては享受目的がないとすることはできないだろうか。
前者は、上記のとおり特定の既存著作物の創作的表現に興味関心はなく、特定の既存著作物に含まれる事実的な情報を参照した出力を求めているのに対し、後者については、特定の既存著作物の創作的表現に興味関心があり、特定の既存著作物の創作的表現の影響下にある出力を求めている、と言い換えてもよい。
前者は、ふわっとしているが、一般事業会社における通常のビジネス場面で活用されるようなものをイメージしている。
後者は、極端な例ではあるが、上記「作風や画風を真似る生成AI」のように、LLM自体の設計はそうではないとしても、RAG活用により作風や画風を模倣する生成AIにカスタマイズするような場合を想定している。
なお、著作権法第30条の4の目的については、「行為者の主観と客観の各事情を総合的に勘案して判断される」ところ、「例えば、RAG等による出力に際して、生成AIへの指示・入力に用いられたデータに含まれる著作物と共通した創作的表現が出力されないようフィルタリングする技術的措置が取られている場合、享受目的を否定する要素となり得る」とされている(「AIと著作権に関する考え方について(素案)」に関するパブリックコメントの結果についてNo.145)。
著作権者の利益を不当に害するか
この点、著作権法第30条の4が著作物に表現された思想又は感情の享受を目的としない行為を広く権利制限の対象としたのは、次の理由による。
著作物に表現された思想又は感情の享受を目的としない行為については,著作物の表現の価値を享受して自己の知的又は精神的欲求を満たすという効用を得ようとする者からの対価回収の機会を損なうものではなく,著作権法が保護しようとしている著作権者の利益を通常害するものではないと考えられるため,当該行為については原則として権利制限の対象とすることが正当化できるものと考えられる。
裏を返せば、非享受目的とはいえ著作物の利用が「著作権者の著作物の利用市場と衝突するか、あるいは将来における著作物の潜在的市場を阻害する」場合には、権利制限の対象とすることが正当化されない(デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方9頁)。
そこで、著作権法第30条の4但書において「当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない」とされている。
典型例は、大量の情報を容易に情報解析に活用できる形で整理したデータベースの著作物が販売されている場合に、当該データベースを情報解析目的で複製等する行為であり、これは当該データベースの販売に関する市場と衝突し、データベースの著作権者の利益を不当に害することになるとされている(デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方9頁)。
このほか、文化審議会著作権分科会法制度小委員会は次のようなものを挙げている(AI と著作権に関する考え方について(令和6年3月15日)23−29頁)。
アイデア等が類似するにとどまるものが大量に生成される場合
情報解析に活用できる形で整理したデータベースの場合
インターネット上のウェブサイトで、ユーザーの閲覧に供するため記事等が提供されているのに加え、データベースの著作物から容易に情報解析に活用できる形で整理されたデータを取得できるAPIが有償で提供されている場合において、当該APIを有償で利用することなく、当該ウェブサイトに閲覧用に掲載された記事等のデータから、当該データベースの著作物の創作的表現が認められる一定の情報のまとまりを情報解析目的で複製する行為は、本ただし書に該当し、同条による権利制限の対象とはならない場合があり得る(「AIと著作権に関する考え方について(素案)」に関するパブリックコメントの結果についてNo.205参照)
学習のための複製等を防止する技術的な措置が施されている場合
学習のための複製等を防止する技術的な措置は、あるウェブサイト内に掲載されている多数のデータを集積して、情報解析に活用できる形で整理したデータベースの著作物として販売する際に、当該データベースの販売市場との競合を生じさせないために講じられていると評価し得る例がある(データベースの販売に伴う措置、又は販売の準備行為としての措置)⇛The New York Times等
(技術的措置例①)ウェブサイト内のファイル”robots.txt”への記述によって、AI学習のための複製を行うクローラによるウェブサイト内へのアクセスを制限する措置
(技術的措置例②)ID・パスワード等を用いた認証によって、AI学習のための複製を行うクローラによるウェブサイト内へのアクセスを制限する措置
海賊版等の権利侵害複製物をAI学習のため複製する場合
ウェブサイトが海賊版等の権利侵害複製物を掲載していることを知りながら、当該ウェブサイトから学習データの収集を行うといった行為は、厳にこれを慎むべきものである
(Ⅱ) 著作権法第47条の5該当性
RAG活用生成AIサービスにおいて、何らかの事情によりデータベースの作成に用いられた既存著作物の創作的表現を出力することを目的としていると評価される場合、つまり享受目的が併存する場合、著作権法第47条の5の軽微利用による権利制限が論点となる。
法第30条の4が適用されない場合でも、RAG等による回答の生成に際して既存の著作物を利用することについては、法第47条の5第1項第1号又は第2号の適用があることが考えられる。
ただし、この点に関しては、法第47条の5第1項に基づく既存の著作物の利用は、当該著作物の「利用に供される部分の占める割合、その利用に供される部分の量、その利用に供される際の表示の精度その他の要素に照らし軽微なもの」(軽微利用)に限って認められることに留意する必要がある。
また、同項に基づく既存の著作物の利用は、同項各号に掲げる行為に「付随して」行われるものであることが必要とされているように、既存の著作物の創作的表現の提供を主たる目的とする場合は同項に基づく権利制限の対象となるものではない、ということにも留意する必要がある。
そのため、RAG等による生成に際して、「軽微利用」の程度を超えて既存の著作物を利用するような場合は、法第47条の5第1項は適用されず、原則として著作権者の許諾を得て利用する必要があると考えられる。
RAG活用生成AIサービスにより行われる行為が著作権法第47条の5第1項の軽微利用であれば、その準備のために必要な範囲で複製や公衆送信(*)を行うことができる(同条第2項)。
*著作権法第47条の6第1項第1号において、翻訳・変形・編曲・翻案も権利制限の対象となっている。
軽微利用として認められ得る行為は、①所在検索(著作権法第47条の5第1項第1号)と②情報解析(同項第2号)の2つである(同法第30条の4とは異なり限定列挙である)。
これらの行為を行う者(*)は、当該行為の目的上必要と認められる限度において、当該行為に付随して軽微利用を行うことができる。つまり、必要性・付随性・軽微性があわせて要求される。
*著作権法施行令第7条の4の基準や同法施行規則第4条の4の措置を充足する者に限る(同法第47条の5第1項柱書括弧書)。
これらの要件が求められるのは、この軽微利用は著作権法第30条の4とは異なり著作物の創作的表現の享受目的があるため、権利者に一定の不利益を及ぼし得ることが想定されるものの、「電子計算機による情報処理により新たな知見又は情報を提供する点において社会的意義が認められるとともに、これらのサービスで行われる著作物の利用は、サービスの主目的である新たな知見又は情報の提供に付随して行われるものであり、著作物の利用を軽微な範囲にとどめれば、基本的に著作権者が当該著作物を通じて対価の獲得を期待している本来的な販売市場等に影響を与えず、ライセンス使用料に係る不利益についても、その度合いは小さなものに留まるものと考えられる」として権利制限を行うためである(デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方19頁)。
なお、形式的には所在検索や情報解析などの結果とともに著作物が表示されるサービスでも、その表示が一般的にユーザーのもつ当該著作物の視聴等にかかわる欲求を充足することになり、当該オリジナルの著作物の視聴等にかかる市場に悪影響が及ぶような場合、いわば「コンテンツ提供サービス」と評されるような場合、権利制限の対象とはならない(デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方52頁)。
所在検索
一 電子計算機を用いて、検索により求める情報(以下この号において「検索情報」という。)が記録された著作物の題号又は著作者名、送信可能化された検索情報に係る送信元識別符号(自動公衆送信の送信元を識別するための文字、番号、記号その他の符号をいう。中略)その他の検索情報の特定又は所在に関する情報を検索し、及びその結果を提供すること。
ここでいう「検索情報」とは、検索を行う者が検索により得たいと考える情報であり、キーワードに直接又は間接に関連するWebページや画像等がこれに当たり、当該Webページや画像等のURLは「検索情報の特定又は所在に関する情報」に当たる(松田政行ほか「著作権法コンメンタール別冊平成30年・令和2年改正解説」85頁)。
例えば,利用者が入力したキーワードに関連する情報(検索情報)が掲載された書籍の題号や著作者名,検索情報が掲載されたウェブページのURLを検索し,その結果(書籍の題号や著作者名,ウェブページのURL)を提供するサービスが想定され,当該検索結果の提供に付随して,当該検索結果の確認の便宜のために書籍やウェブサイト中でキーワードが用いられている本文の一部分を提供する形で著作物を利用することが権利制限の対象となる。
具体的には,インターネット情報検索サービスにおいては,検索結果としてウェブサイトのタイトルやURLとともに,そのウェブサイト内の文章の数行程度(スニペット)を表示したり,小さなサイズに縮小された画像(サムネイル)を表示したりすることが慣行として行われていたところ,サービスの目的が著作物の提供自体ではなく,利用者に著作物の所在情報を提供することによってオリジナルのウェブサイトへと誘導すること(著作物の利用は,あくまでそれに付随するもの)であるとともに,同サービスのために必要な限度で行われる著作物の表示は軽微なものに留まることから,著作権者の利益に悪影響を及ぼさないと判断し,権利制限を行ったものであると考えられる。
当該サービスにおいてURLの提供とともにウェブページ等の一部分を利用する行為は,当該ウェブページ等がユーザーの求める情報かであるか否か容易に確認することができるようにするために提供されるものであり,通常は,結果の提供に「付随」するものと考えられる。
このため,その検索結果の提供とともに著作物の一部分を提供する行為は,軽微性など,同条に規定する他の要件を充足する場合には,第47条の5による権利制限の対象となるものと考えられる。
必要性
必要性は、著作権法第47条の5第1項柱書に「当該各号に掲げる行為の目的上必要と認められる限度において」とあるため要件の1つではあるものの、「デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方」等において個別の説明はなく、高度な必要性までは要求されていない。
当該著作物の利用により検索結果・解析結果をより分かりやすく理解できるようになるなど各号に掲げる行為の質が高まるという程度の必要性で足りるものと考えられる.例えば,インターネット情報検索サービスにおいて,情報処理の結果(検索結果として表示されるウェブページのURL)が自己の関心に沿うものであるか否かを確認できるようにする目的で著作物を利用する場合(ウェブページの本文の一部分をスニペット表示)…「各号に掲げる行為の目的上必要と認められる限度において」に当たると考える.
付随性
著作権法第47条の5第1項柱書の文理解釈上、次の①と②を区別したとき、あくまで前者が主たるもので後者が従たるものである必要があり、その関係が成り立つ場合、②が①に付随している(=付随性がある)といえる。
①情報処理の結果の提供に係る各号の行為【主】
(例:検索結果としてのURLの提供)
②著作物を軽微な範囲で利用する行為【従】
(例:スニペットやサムネイルの提供)
他方、情報処理の結果の提供が著作物そのものの提供である場合、当該行為と著作物の利用が一体化し、当該行為に「付随して」著作物を利用するものとは評価できない。
情報処理の結果の提供に係る行為が著作物そのものを提供するものである場合には、当該行為と著作物を軽微な範囲で提供する行為が一体化していることから、「付随」するものとは評価できないものと考えられる。
なお、ここでいう「著作物そのものの提供」について言及しているものは見当たらず、当該著作物全体を提供という趣旨なのか、当該著作物の大部分(5割以上?)を提供という趣旨なのかは不明であるが、このあたりは後記「軽微性」の論点でもある気がするため、一旦スルーする。
軽微性
軽微性については、著作権法第47条の5第1項本文において「当該公衆提供等著作物のうちその利用に供される部分の占める割合、その利用に供される部分の量、その利用に供される際の表示の精度その他の要素に照らし軽微なものに限る」とされている。
著作権法第47条の5の立法趣旨に照らせば、同条に基づく著作物の利用が当該著作物の本来的な市場に影響を与えないものにとどまることが必要であり、軽微性の要件は権利者に及び得る不利益が軽微なものに留まることを担保するための要件である。
そのため、専ら著作物の利用に係る外形的な要素を総合的かつ類型的に判断されるべきものであり、利用目的の公共性等の要素が考慮されるものではないとされている(松田政行ほか「著作権法コンメンタール別冊平成30年・令和2年改正解説」105頁)。
漫画,小説,論文,映画など一定の分量があって流れ(ストーリー)のある著作物については,通常,著作物全体のうちどの程度の割合および量が利用されているかが軽微性に与える影響が大き〔い〕
総合考慮ではあるものの,割合および量の影響が大きいと考えられる著作物については,50%を超える割合で利用している場合に,著作権者の市場に影響を与える可能性が類型的に低いとは言い難く,軽微性要件を満たす可能性は低い
ではRAGデータベースの作成についてはどうか
(以下はかなり悩みながら考えた試案である)
まず、軽微利用の準備のために必要と想定される検索用データベースの作成にかかる複製等の行為は幅広く権利制限の対象とされている(著作権法第47条の5第2項)。なお、この権利制限は、あくまで所在検索や情報解析にかかるサービス提供の準備段階でのデータベースの作成等のための内部的な著作物利用を念頭においたものであり、その目的を超えて著作物を視聴等に供したり一般公衆への提供・提示したりするものではないことから、同条第1項とは異なり、その利用につき軽微性は要求されていない(デジタル化・ネットワーク化の進展に対応した柔軟な権利制限規定に関する基本的な考え方24頁)。
ここでも生成・利用段階の論点と開発・学習段階の論点が融合することになる。つまり、実際にRAG活用生成AIサービスを用いて何らかのものが生成・利用される段階を見越して、それが著作権法第47条の5第1項の要件を満たすなら、そのために必要なデータベースの作成等にかかる開発・学習は同条第2項により正当化される。
これまでの所在検索サービスが、検索結果としてのURL情報に加え、ユーザーの求める情報かであるか否か容易に確認することができるように、一定分量のスニペットやサムネイルを表示することが著作権法第47条の5第1項における軽微利用として認められてきたことを踏まえると、RAG活用生成AIサービスが同様に著作物のスニペットやサムネイルを表示すること自体は認められる。
問題は、それを超えて、RAG活用生成AIサービスが著作物の内容を要約等(*)することにより、ユーザーがその表示を受けて満足し、検索されたオリジナルの著作物に辿り着かず、権利者が当該著作物を通じて対価の獲得を期待している本来的な販売市場等に影響を与える「コンテンツ提供サービス」になってしまい、著作権法第47条の5の権利制限を受けられないのかどうかである。
*ちなみに、RAG活用生成AIサービスによる要約等が複製に該当する可能性はあるにせよ翻案には該当しない。
「翻案」という行為が著作物の作成行為である以上,「翻案」に当たるためには人間による創作行為が必要になる.つまり,コンピュータによって作成されるものは著作物ではないのである.
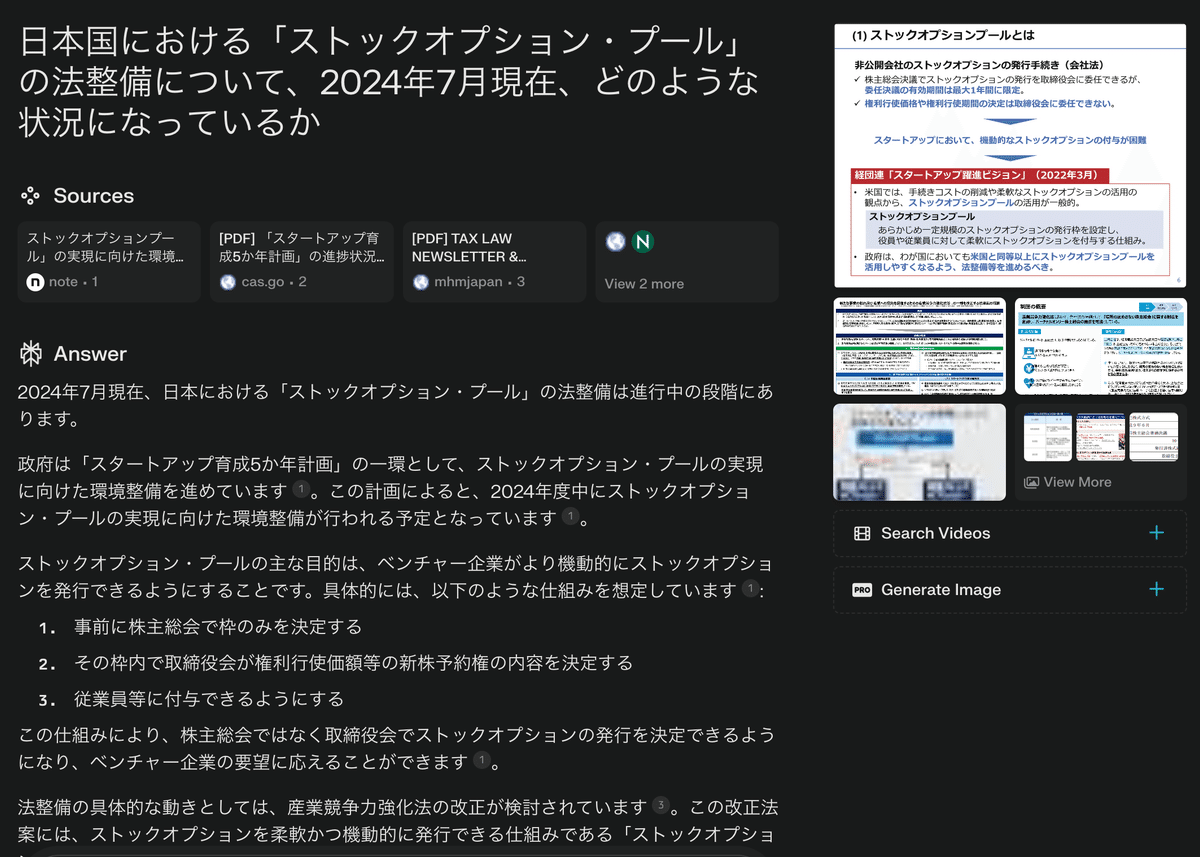
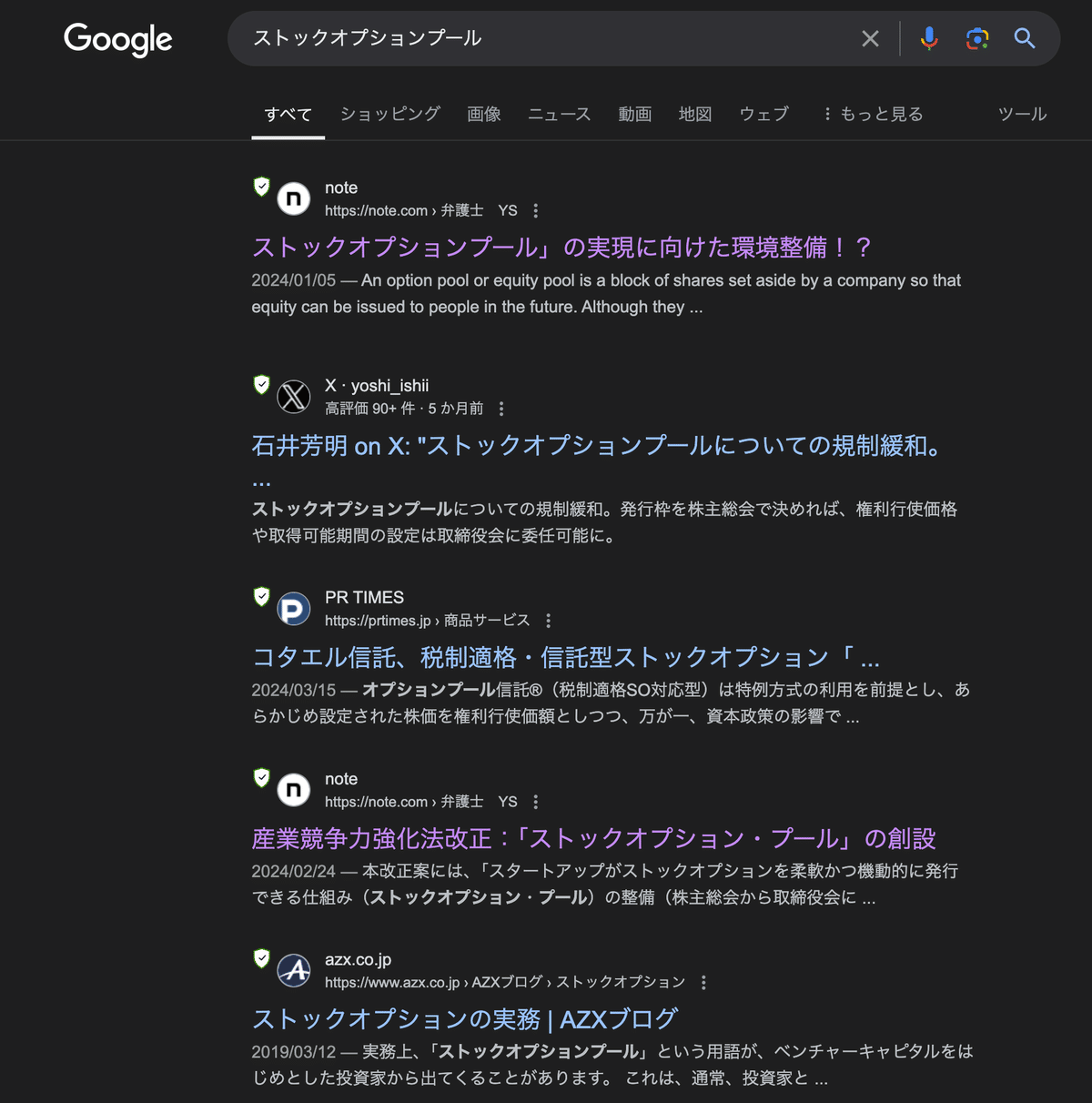
確かに、上記のとおり、単に「ストックオプションプール」というキーワードでもってGoogle検索した場合よりは、知りたい内容を文章にして打ち込んでperplexityで検索した場合の方が、ユーザーとして直感的で検索しやすく、出力される情報量が多く、また検索結果の関連性も高い。
このように、上記キーワード検索結果の例においてわかるように、キーワード検索は、その結果が示す数行のスニペット表示では、どのウェブページにユーザーが知りたい必要な情報が含まれているのか不明であることから、生成AIウェブ検索サービスがある今となっては非常に使い勝手が悪い非効率なリサーチ方法となっている。
つまり、従前、Google検索において、ちまちま1つずつウェブページを開いては閉じていた「苦行」をperplexityのような生成AIウェブ検索サービスは打破し、ユーザーが知りたい内容と関連性の高いいくつかの検索結果を吟味し、当該ウェブページに遷移することを可能とする。
生成AIウェブ検索サービスにより出力される情報量が多いといっても、従前の何ら役に立たない数行のスニペットよりは情報量が多いという程度であって、あくまで出典等ソースの要約に過ぎない。
perplexityのような生成AIウェブ検索サービスは、ユーザーがソースとなるウェブページを訪れない「ゼロクリックサーチ」を増やし、これまで検索システムの不完全性・不十分性により、ユーザーの「苦行」と引き換えに稼いできたトラフィックやコンバージョン(マーケティング機会)、広告収入やニュースポータルからの収入を減少させ、ウェブページの設置者に不利益を生じさせるように見えるかもしれない。
しかし、いわゆる「セロクリックサーチ」が問題となり始めたのは2019年頃のようであり(https://ferret-plus.com/14134)、その背景は、ナレッジパネルや強調スニペットなど検索結果ページ(SERP)上で直接情報を提供するGoogleの機能が充実したことやユーザーのモバイル端末での検索行動への変容などが挙げられており(https://partita.co.jp/meocolumn/zero-click-search/)、生成AIウェブ検索サービスのみが原因ではない。
ユーザーにウェブページを見てもらうためには事実上検索システムの利用が促進されなければならず(やはり競争法が主戦場なのではないか)、そのためにはユーザーが検索システムを利用する際のペインを可能な限り排除することが必要である以上、生成AIウェブ検索サービスは必然的な進化・発展であると思われる。
従前の検索行動では閲覧すらされなかったウェブページも、生成AIウェブ検索サービスにより関連性が高いものとして要約・引用されることにより、ユーザーが当該ウェブページを訪れる確率は高まる。
長文の要約・引用が生成されるケースも特段問題視するべきではなく、生成AIウェブ検索サービスによりクエリとの関連性が高いと判断されていることの証左でもあるため、ユーザーが当該ウェブページを訪れる確率は高まると思われる。
したがって、数行のスニペット表示に限らず、オリジナルのウェブページへと誘導するとは到底いえないような全文表示又は全文表示に極めて近い部分表示以外の要約・引用であれば、「軽微利用」として許容してよいと考える。
【参考】報道記事と軽微利用の考え方(別に参考にはならないか)
Q. 報道記事は、時間の経過に伴い、1つの事象について複数の記事が作成・公開されることになるが、RAGによる検索結果として複数ある記事を用いた要約を生成するケースが想定される。この場合、参照する記事の数が増えれば増えるほど、生成された要約に対する1つ1つの記事の影響は薄くなるという関係になるが、参照記事を増やすことで、1つ1つの記事との関係では著作権法47条の5第1項にいう「軽微利用」に留まるという理解は可能か。
A. 「軽微」であるか否かは、利用に供される部分の占める割合、その利用に供される部分の量、その利用に供される際の表示の精度などの外形的な要素に照らして最終的には司法の場で具体的に判断されることとなります(「基本的な考え方」23頁)。
生成・利用段階
非常に奇妙な感じではあるが、生成・利用段階における著作権法第47条の5第1項の論点は、上記のとおりであり、既に述べている。
法第30条の4が適用されない場合でも、RAG等による回答の生成に際して既存の著作物を利用することについては、法第47条の5第1項第1号又は第2号の適用があることが考えられる。
ただし、この点に関しては、法第47条の5第1項に基づく既存の著作物の利用は、当該著作物の「利用に供される部分の占める割合、その利用に供される部分の量、その利用に供される際の表示の精度その他の要素に照らし軽微なもの」(軽微利用)に限って認められることに留意する必要がある。
また、同項に基づく既存の著作物の利用は、同項各号に掲げる行為に「付随して」行われるものであることが必要とされているように、既存の著作物の創作的表現の提供を主たる目的とする場合は同項に基づく権利制限の対象となるものではない、ということにも留意する必要がある。
そのため、RAG等による生成に際して、「軽微利用」の程度を超えて既存の著作物を利用するような場合は、法第47条の5第1項は適用されず、原則として著作権者の許諾を得て利用する必要があると考えられる。
以上
この記事が気に入ったらサポートをしてみませんか?