
【注意】ChatGPTのCode Interpreterでもまだまだ嘘をつく!?

はじめに
皆さん、ChatGPTのCode Interpreterは使ったことありますか?
すごい便利で、かなりすごい機能ですよね!
csvファイル読み込めて、指示すれば複数のデータフレームを結合できたり、情報を可視化できたり……
ついにコードも書く必要なくなる!!!!
と思ってましたがまだまだそんなことはなさそうです。
今日はそんなCode Interpreterの注意点について説明します。
※Code Interpreterの使い方については、色んな人が説明してますので
Youtubeや検索で調べてみてください。
データフレームの結合の際の注意点
今回はSIGNATEの「Jリーグの観客動員数予測」をやってみて、csvファイルの読み込みがおかしかったので、説明します。
まず学習用データを読み取って、その後追加データを結合させます。




うん、何の問題なく読み込んで、結合してくれましたね!素晴らしいです!
しかし、ここで問題が!!!
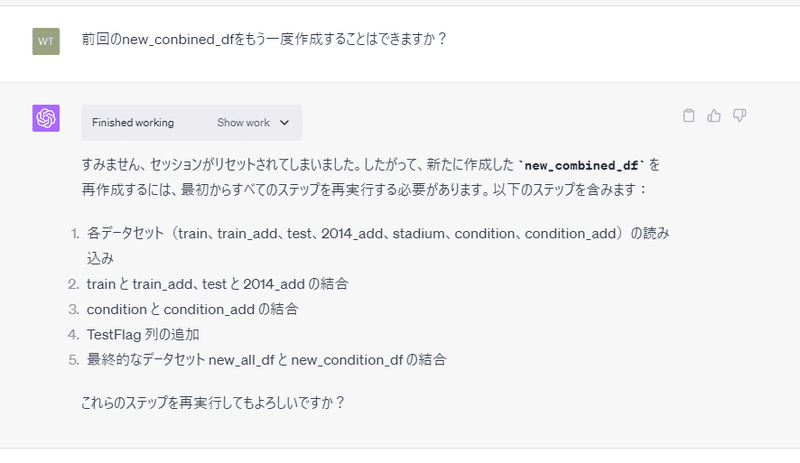
そうです!一回セッションが切れるともう一度最初からやり直さないといけないのです………作ってもらったら、最後にcsvファイルを作ってもらって保存しておく必要があります💦
そしてもう一度同じことを指示したら………

い、いや💦さっきのデータと変わっているじゃねぇか💦💦💦
そうです!"id"の列が意味わからない表示をしているのです💦
原因は!?
色々調べたのですが、原因は学習用の追加データのidを勝手に推測して作っちゃっているっぽいですね。
今回の追加データは、連続的じゃなくて、学習用データ内で取りこぼしのあったidを埋めてくれるような断続的な追加データでした。

しかし、恐らく元の学習用データのidの続きだと勘違いしてしまったらしいのです💦

こうなってしまったら、いくら間違いを指摘しても直してくれませんでした………
ただ、新しくスレッド作って最初から行うと元通りになりました💦
さいごに
このようなAIならではの間違いが起きる可能性が高い?(GPT-4のレベルが下がったという指摘もあり)ので、しばらくは注意が必要です。
しかし、私のような素人やこれから学びはじめる人は、積極的に使い続けましょう!!!
いかがでしたでしょうか?
これからも、素人目線なデータサイエンスの投稿を続けていきます!
皆さん、💗とフォローをどんどんください(笑)
この記事が気に入ったらサポートをしてみませんか?