
【SIGNATE】携帯電話の機能データからの価格帯分類

こんにちは!5月の「SIGNATEビギナーズコンペ」に参加しました!内容は携帯電話の機能データからの価格帯分類でした。公開できない情報があるので、全部の報告はできませんが、一部について報告します。
今回は、携帯電話の価格帯を(安い)0 , 1, 2, 3(高い)に分類する分類問題です。その予測モデルを作成し、未知のデータを分類して、事務局が持っている正解データと比較して、数値を比較します。
ちなみに閾値は、F1macro=0.462885であり、この敷地を超えれば、Intermediateの称号を手に入れることができます。私はギリギリ手に入れられましたwww
特徴量エンジニアリング
数値の正規化
まずは、数値の正規化を行いました。
from sklearn.preprocessing import StandardScaler
# Create a StandardScaler instance
scaler = StandardScaler()
# List of columns that you want to scale
scale_columns = ["battery_power", "ram", "int_memory", "mobile_wt"]
# Fit the scaler to the columns of the dataframe and transform
train_df[scale_columns] = scaler.fit_transform(train_df[scale_columns])
display(train_df)正規化とは、各特徴量の平均を0、標準偏差を1にするように値を変換することで、異なる尺度で測定されたデータを比較可能にします。
上記カラムの数値の尺度が、バラバラになっていたため、このような処理を行いました。
特徴量の重要度の可視化
ここでは次のようなコードを書きました。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
# 目的変数と説明変数の定義
y = train_df['price_range']
X = train_df.drop('price_range', axis=1)
# データの分割
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=0)
# ランダムフォレスト分類器のインスタンス化
clf = RandomForestClassifier(random_state=4)
# モデルの訓練
clf.fit(X_train, y_train)
# 検証データでの予測
y_pred_val = clf.predict(X_val)
# F1スコアの計算
f1 = f1_score(y_val, y_pred_val, average='macro')
print("F1 Score: ", f1)
# 特徴量の重要度を取得
importances = clf.feature_importances_
# 特徴量の名前と重要度を結びつける
features = pd.DataFrame({'Feature': X_train.columns, 'Importance': importances})
# 重要度の高い順にソート
features.sort_values(by='Importance', ascending=False, inplace=True)
# 重要度の表示
print(features)
# 重要度の可視化
plt.figure(figsize=(10,8))
plt.title('Feature Importances')
plt.barh(range(len(features)), features['Importance'], color='b', align='center')
plt.yticks(range(len(features)), features['Feature'])
plt.xlabel('Relative Importance')
plt.show()このコードにより、ランダムフォレストの機械学習の際に、重要度の高い特徴量(カラム)と重要度が低い特徴量(カラム)を算出することができます。
ちなみに今回は未知のテストデータの価格帯("prince_range")を予測するので、訓練データをtrain_test_splitで訓練とテストに分けて、予測モデルを作成してます。
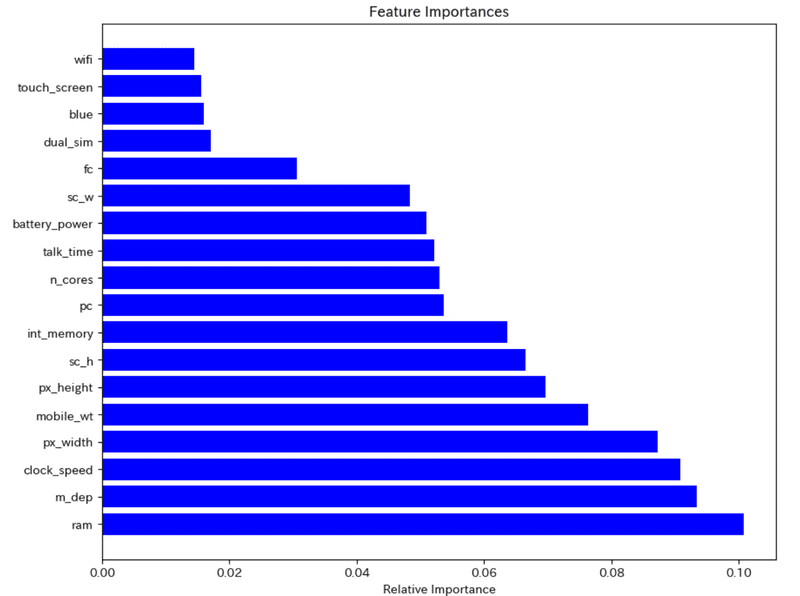
こんな感じになりました。そんなに重要度が高いものはありませんが
"wifi", "touch_screen", "blue", "dual_sim"などは影響力が低いことが伺えます。重要度の低い特徴量は消してしまってもよさそうです。
逆効果な特徴量エンジニアリング
さて、今回やってみて、逆効果たっだ特徴量エンジニアリングですが
携帯電話の高さと幅と深さを掛けて、体積にしたり面積にしたりしてまとめると、めちゃくちゃ逆効果でしたw
また、スクリーンの大きさも面積にして、検討を行いましたが
全くと言っていいほど、スコアを上げることができませんでした。
理由はわかりませんが。。。。。
予測モデル
使用した予測モデルは、ランダムフォレストのハイパーパラメーターチューニングを行ったものです。以下のコードです。
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
# 目的変数と説明変数の定義
y = train_df['price_range']
X = train_df.drop('price_range', axis=1)
# データの分割
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=0)
# ランダムフォレスト分類器のインスタンス化
clf = RandomForestClassifier(random_state=3)
# ハイパーパラメータの候補
param_grid = {
'n_estimators': [100, 200, 300, 400, 500],
'max_depth': [None, 5, 10, 20, 50, 100]
}
# グリッドサーチの設定
grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='f1_macro')
# モデルの訓練とハイパーパラメータのチューニング
grid_search.fit(X_train, y_train)
# 最適なパラメータの表示
print("Best Parameters: ", grid_search.best_params_)
# 最適なパラメータを用いたモデルの訓練
clf_best = RandomForestClassifier(**grid_search.best_params_, random_state=0)
clf_best.fit(X_train, y_train)
# 検証データでの予測
y_pred_val = clf_best.predict(X_val)
# F1スコアの計算
f1 = f1_score(y_val, y_pred_val, average='macro')
print("F1 Score: ", f1)このコードで、訓練データの中のテストデータのF1スコアは0.52を超えました。
しかし、多少過学習気味なのか、実際のテストデータのスコアは0.463台でした。。。
何とか閾値を超えたので、良しとしましょうw
ちなみに上記コードのrandom_stateの数値を変えると、多少結果が変わりますので、惜しいスコアを出した場合、微調整できます。
いかがでしたでしょうか。
私はビギナーでしたので、今回はビギナーズ限定コンペにさんかしましたが
今後は、ハイレベルなコンペにも挑戦していきます。
同じようにデータサイエンスに挑戦している人のお役に立てれば光栄です^^
これからもよろしくです!
この記事が気に入ったらサポートをしてみませんか?