
日本語Alpacaデータを用いてJapanese-Alpaca-LoRAを作ったので公開します【期間限定デモページあり】

⚠️注意
今回公開するのはLoRAを用いて作成したLLaMAの日本語化Adapterでありモデル自体ではありません。
LoRAをマージするベースのLLaMAは商用不可であり、今回公開するAdapterで日本語化したモデルも商用利用はできません。
OpneAIの利用規約で、OpenAIサービス、ChatGPTの出力結果を競合モデル開発用途に利用することは
できませんコンテンツ生成者はできません。 詳細は記事後半で述べていますが利用規約が適用されるのはコンテンツ生成者までです。
概要
2022年の11月末にOpenAIからChatGPTが発表されてから、それに追随するようにGoogleからBard、MetaからLLaMAなど大規模言語モデル(LLM)が発表されました。さらにLLaMA 7Bを「text-davinci-003」を用いて「Self-Instruct」で作成された52Kのデータセット(以下、Alpacaデータ)を用いてファインチューニングしたStanford Alpacaがスタンフォード大学より発表されました。
このAlpacaはスタンフォード大学がSelf-Instructで作成した英語データセット(alpaca_data.json)でファインチューニングされているため、日本語で会話することはできません。しかし、先日、LoRAという省メモリ、省時間でファインチューニングする手法とスタンフォード大学が公開しているAlpacaデータを用いてStanford AlapacaをReproductできるリポジトリが海外の有志の方から公開されました。
今回、このリポジトリの方法と独自に日本語に翻訳した日本語Alpacaデータを用いて日本語での会話が可能な「Japanese-Alapaca-LoRA 7B, 13B, 30B, 65B」を作成、公開したので紹介します(※ 公開するLoRAはあくまでもβ版という位置付けです)。
モチベーション
LLMがChatGPTを皮切りに、目まぐるしく進歩している分野であり純粋に興味があり、個人でLLMをファインチューニングできる技術が出てきたので触ってみたいと思った。
ローカルで自由に触れて、自由にカスタマイズできるLLMが今後必要になると思っていることや、現状、国産LLMが少ないことに対する漠然とした危機感からこの分野の技術をキャッチアップしてみたいと思った。
Alpaca, Alpaca-LoRA, 日本語ファインチューニングについて
それぞれを私のほうで説明しても良いのですがこれらについて丁寧に解説してくれている記事がすでにあるのでここではその記事のリンクのみを紹介させていただきます。
Alpaca, Alpaca-LoRA
いつも最先端技術についていち早く解説、実装方法を紹介してくれるnpakaさんの記事になります。
日本語ファインチューニング
私と同様に日本語Alpacaデータでファインチューニングを実施している方がいました。こちらの方との差分としてはこの方はAlpacaデータをChatGPTにて日本語翻訳したのに対し私のほうではDeepL APIを用いて日本語翻訳を実施している点です。翻訳方法の違いによる翻訳精度の違いはありそうです。
また、livedoorニュースコーパスを用いてファインチューニングを試している方もいました。
日本語Alpacaデータの作成
スタンフォード大学が公開しているAlpacaデータの日本語翻訳はDeepL APIを用いて行いました。私のほうでも最初はChatGPT APIでの翻訳を試しましたがChatGPT APIに翻訳指示をすると箇条書きで3案くらい翻訳結果を出力したり、翻訳前の文章の原文も一緒に出力することがあり、安定した翻訳結果を得ることができないと感じました。「回答は1個だけにすること、原文は出力しないこと」と指示することもできますが指示の条件を増やすことでトークン数が多くなりAPI料金の増加につながりそうだと思い、最終的にDeepL APIを利用しました。
参考ですがDeepL APIでAlpacaデータを翻訳した場合の料金はだいたい4万5千円程度、文字数は全部で約1800万文字でした(嫁さんにばれたら怒られるやつです)。

ファインチューニングの実施
今回はMetaのLLaMA 7B , 13B, 30B, 65Bに対してファインチューニングを実施しました。30Bのモデルサイズは80GB、65Bについては130GBとかなり大規模なので、「エポックごとにこの130GBがストレージに保存されていくのか…」と思っていましたがLoRAでのファインチューニングでは、モデルに追加するAdaptation層の重みファイル、数十MBがエポックごとに保存されるのみでした。また、省メモリなLoRA & VRAM 80GB環境でバッチサイズをたくさん上げることで65Bでも3epoch 15時間で終わる感じで、LoRAが非常に優秀でした。
7B, 13B, 30B, 65BのそれぞれのValidation Lossは以下のようになりました。
65BだとさすがにLossも低くなるなと感じる反面、30Bとの差が0.03程度なので30Bでエポック数を増やしたり、トークン長(現在はすべて128で学習)を増やしたほうが時間やコストのパフォーマンスが良いような気はしています(30Bの学習時間は3epoch 6時間であり65Bの15時間の半分以下)。

ちなみに学習コストは30Bと65BについてはクラウドでRAM 80GBのGPUを22時間ほどスポットレンタルして1万円程度でした。7Bと13BはGoogle Colab Pro+(約6千円/月)を使用しました。
モデルごとの出力例
参考に今回ファインチューニングをした4つのモデルでの出力例の違いを載せておきます(65Bは後追いで載せます)。
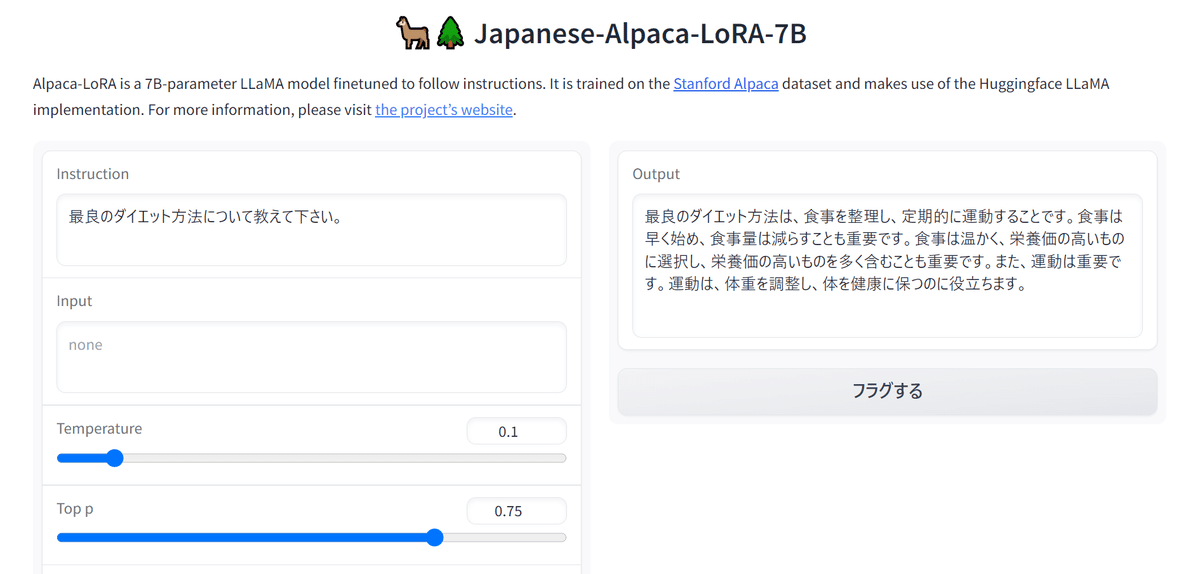
7Bモデル
ちゃんと流暢に回答してくれていますが、回答内容が少し適当な気がします(「サッカーサーフ」?)

13Bモデル
13Bの1個目の画像では途中から同じ回答を繰り返してしまっていますが、命令を工夫することで2枚目では解消しています。ただし、この現象は生成時のパラメータを工夫することで解消することが可能でした(サンプルのColabコードではこういった繰り返し減少は発生しないです)。


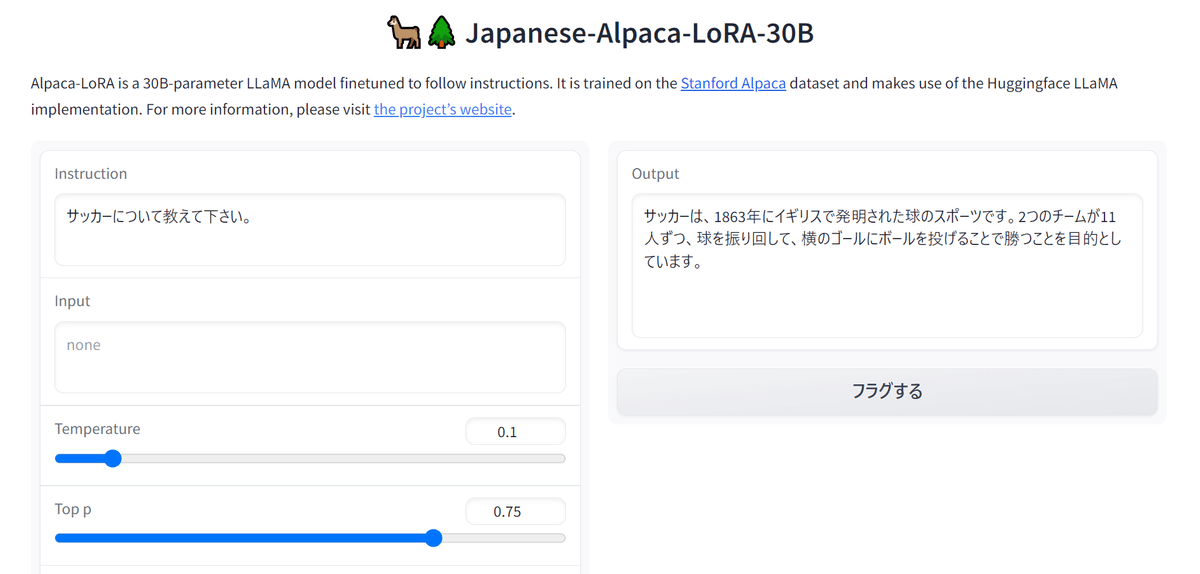
30Bモデル

65Bモデル
後追いで掲載します。
Japanese-Alpaca-LoRA
あくまでもβ版という位置づけですが今回作成したモデルを公開します(正確にはモデルではなくAdapterの重み)。自由に触ってもらえると幸いです。
デモページ
Japanese-Alpaca-LoRA-7Bを触れるWeb UIを用意しました。Hugging Face上でGPUを有料レンタル(3,500円/日)して稼働させている関係で24時間限定ですがいろいろと自由に質問してみて下さい!(もしnoteでサポートが集まれば延長も検討したいです)。また、アクセスが集中すると動作が遅くなるかもしれません。回答が不器用なところもありますが温かい目でしゃべりかけてあげて下さい。
【公開期間 2023/3/26 12:00 ~ 2023/3/27 29 21:00】
※ サポートいただいたので期間を延長します。ありがとうございます!!
デモ公開期間は終了しましたが @_kaiinui 様のマシンにホスティングしていただき提供を再開いたしました。ご厚意に感謝いたします。
Github
Japanese-Alpaca-LoRAのリポジトリページになります。リポジトリ内にデモページのリンク以外にもColab上で実行できるコードを格納しています。デモページでは7Bモデルを触ることができますが、13B, 30B, 65Bモデルを触ってみたいという方はColabコードで実行することができます(30B、65BはProプラン以上でGPUがA100でないと動かないかもしれないです)。
Hugging Face
あくまでもβ版ですが、今回作成したモデルをHugging Face経由で利用することができます。モデルは改善しだい随時更新いたします。なお、30BモデルのみMax_tokensを128以外にするとエラーが起こることがあります。
OpenAIの利用規約について
参考になりますが、OpenAIサービス、ChatGPTの出力結果で競合モデルを作成することは利用規約(2-c-iii)で禁止されています。そのため、text-davinci-003でSelf-Instructにより作成されたAlpacaデータを商用モデルの作成に利用することはできません。 こちらSNS上でも指摘を受けましたが、利用規約が適用されるのはそのサービスを利用したユーザーまでであるため、ユーザーが配布したものを第3者が使う分には利用規約は適用されない、サービスを利用していない人が利用規約違反になることはない、とのことです(契約していないのに契約違反になることはないのと同じです)。何だか字に起こすと至極当たり前のことを言ってますが…。
日本語Alpacaデータについて
前述の通り私はAlpacaデータの生成者本人でないため、私が利用規約違反になることはないですが、データセットを配布することによるリスクがゼロである確証が持てないため、現時点では今回翻訳したデータセットの配布は考えておりません。
今後やりたいこと
・商用可のJapanese-Alpacoomの作成
前述の通り、日本語AlpacaデータでBLOOMに知識蒸留し商用可のモデルを作成しても規約違反にはならないと思いますが、倫理的には微妙だと思っています(少なくとも企業がこれをやるのは多少のレピュテーションリスクを伴う気がします)。そのため、ChatGPTの出力結果を使わない方法でAlpacaデータライクなデータセット(クリーンAlpacaデータ的な)を作れないか検討したいと思っています(アイディアは絶賛検討中です爆)。
【追記】以下の記事でクリーンデータセット作成の取り組みを始めました
・日本語Alpacaデータへの特定ドメインデータの付加
今回作成したモデルは一般的な日本語データを学習させたものなので、ここに特定ドメインのデータを加えてファインチューニングしたらどうなるかは非常に興味があります。
まとめ
今回はスタンフォード大学が公開しているAlpacaデータを日本語翻訳したデータセットでJapanese-Alpaca-LoRAを作成し、公開しました。LLaMA 7B, 13B, 30B, 65Bすべてのモデルを日本語でファインチューニングすることができ晴れて Meta山脈を制覇した気分です!今後は商用可のJapanese-Alpacoomの作成を目指して、まずはChatGPTの出力結果を用いないクリーンなAlpacaデータセットを作りたいと思います。

(過去にマッターホルンをイメージしてAIで生成した画像)
最後になりますが、noteでのサポートも絶賛受け付けています!!🙇 (デモページの延長、クラウドGPUレンタルなどの実験代に充てたいです)