
コマンドラインのすすめ(ファイルをサクサク処理したい)

Windowsでターミナルを開くことはあまりないのですが、ファイルをサクッと処理したかったので久しぶりに開きました。真っ黒で小さなコンソール画面でコマンド打っていると、独特の静けさを感じます。
Windowsでコマンドラインを使うときはWSL2を使っています。
WSL2はWindows上でLinux(Ubuntu)を動かせる仕組みで、普段はDockerを動かすために使っています。今回はbashのコマンドでサクサクやりたいことがあったので立ち上げました。
やりたいことは、複数のテキストファイルを1ファイルにまとめるというものでした。実に単純な作業なのですが、ファイルが多いと面倒ですよね。
例えば、100個のテキストファイルがあって、それを一つのファイルにまとめてといわれたらどうでしょう。一様に並んだ無機質なアイコンを見た瞬間に手が止まりそうです。(以下は記事のために適当に作ったファイルです)
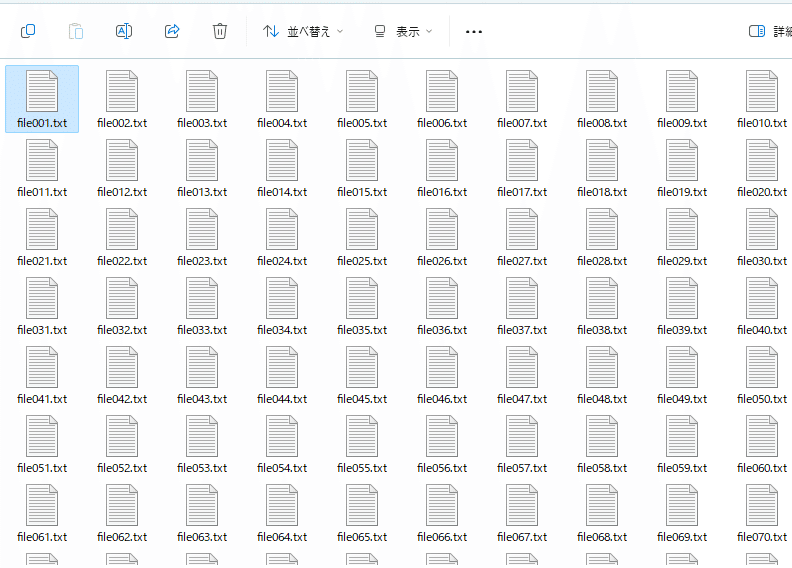
メモ帳を開いてコピペすればできなくはないのですが、ちょっとウンザリしますね。それに、100回コピペしているうちに手が滑りそうです。
コマンドでテキストファイルをマージする
こんなとき、コマンドでファイル操作をすると楽に処理できます。
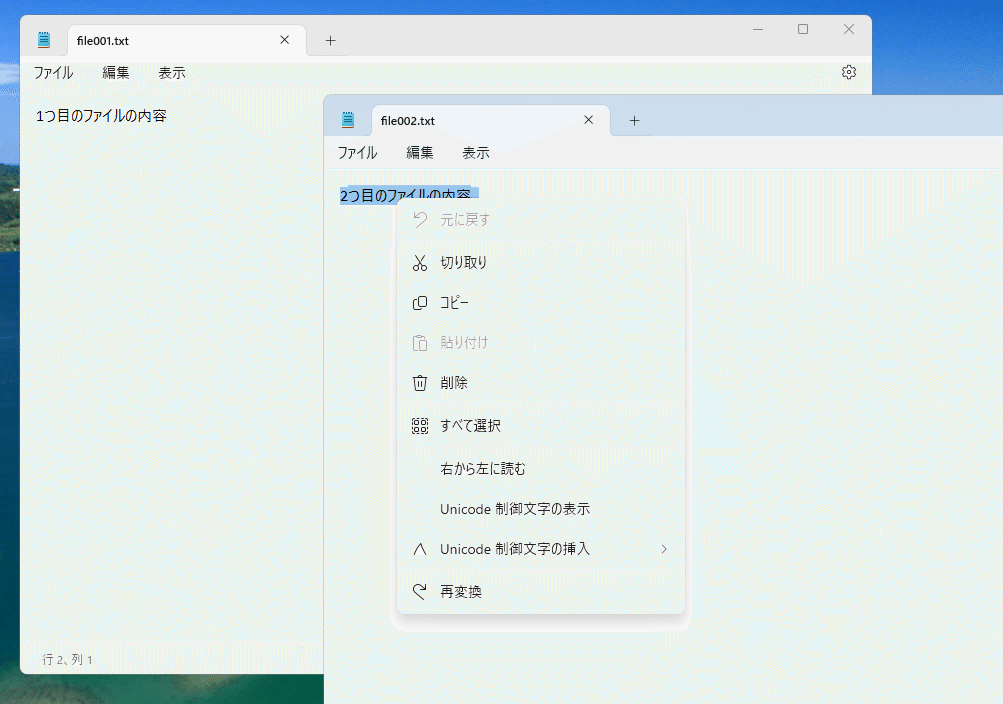
例えば、Linuxでよく使われているシェル(sh, bashなど)では、以下のように打てばファイルを連結してくれます。素敵。
$ cat file*.txt > file_all.txt新しくできたファイルの中身を見ると以下のような感じになっています。確かに全部マージできていますね。単純に縦に連結するだけなら簡単にできます。

ファイルの並び順に依存してマージされるので少し注意は必要です。しかし、フォーマットが同じファイルを統合したいという場合はこれで十分でしょう。このような作業をPythonでやるとするとおそらく5-6行程度書くことになるので、コマンドラインでサクッとはいかなさそうです。
コマンドがうまくいくか気になるときは、ファイルに出力しないでページャーで受け取って表示させることもできます。
$ cat file*.txt | more
1つ目のファイルの内容
2つ目のファイルの内容
3つ目のファイルの内容
4つ目のファイルの内容
5つ目のファイルの内容
6つ目のファイルの内容
7つ目のファイルの内容
8つ目のファイルの内容
9つ目のファイルの内容
10つ目のファイルの内容
11つ目のファイルの内容
12つ目のファイルの内容
13つ目のファイルの内容
14つ目のファイルの内容
15つ目のファイルの内容
16つ目のファイルの内容
17つ目のファイルの内容
--More--ページャーというのはファイルを1画面ずつ見るソフトウェアのことで、中身を読むことに特化しています。moreやlessが有名でしょうか。
テキストエディタやExcelで開くことすら難しいほどの巨大なファイルでも、スイスイ見ることができます。ページャーでも重たい場合は、headやtailをコマンドでファイルの頭と最後をちょこっと見ることもできます。
$ head file_all.txt
1つ目のファイルの内容
2つ目のファイルの内容
3つ目のファイルの内容
4つ目のファイルの内容
5つ目のファイルの内容
6つ目のファイルの内容
7つ目のファイルの内容
8つ目のファイルの内容
9つ目のファイルの内容
10つ目のファイルの内容$ tail file_all.txt
91つ目のファイルの内容
92つ目のファイルの内容
93つ目のファイルの内容
94つ目のファイルの内容
95つ目のファイルの内容
96つ目のファイルの内容
97つ目のファイルの内容
98つ目のファイルの内容
99つ目のファイルの内容
100つ目のファイルの内容フォーマットが同じCSVファイルのマージ
もし、マージしたいファイルがヘッダ付きのCSVファイルであった場合は、もうひと工夫必要です。ヘッダー部分とデータ部分を個別に作ってマージすると上手くいきます。
$ head -n 1 file001.txt > header
$ for f in `ls file*txt`; do tail -n +2 ${f} >> body ; done
$ cat header body > file_all.txtこの方法がワークするには、①ヘッダーが共通であることと、②ファイルの途中にヘッダーが紛れ込んでいないことが前提となります。
これをチェックするため、まずは各ファイルの1行目に含まれるヘッダーの多様性を確かめます。headコマンドでいけそうなのですが、普通にやるとファイル名まで出力されて不便です(この場合は)。
$ head -n 1 file*.txt | more
==> file001.txt <==
ヘッダー行
==> file002.txt <==
ヘッダー行
==> file003.txt <==
ヘッダー行そこで、-qオプションを付けて出力すると、すべてのファイルのヘッダーを一気に見ることができます。
$ head -n 1 -q file*.txt | more
ヘッダー行
ヘッダー行
ヘッダー行
ヘッダー行
ヘッダー行
ヘッダー行
ヘッダー行
ヘッダー行
ヘッダー行
ヘッダー行これでもいいのですが、人の目で見ると間違ってしまうかもしれません。なので、重複行を削減してみると楽に確認できます。これで1行しか表示されなければ①は問題ないというわけですね。
$ head -n 1 -q file*.txt | sort | uniq
ヘッダー行②を確かめるには、ちょっとものぐさな方法ではありますが、ヘッダー行の冒頭の文字列を使ってgrepをかけてみるといいでしょう。以下の例では、正規表現を使って文字列"ヘッダー行"から始まる行を探しています。この結果、1行目以外が引っかかったら、おやおやおかしいぞ?ということになります。
$ grep -n "^ヘッダー行" file*txt
file001.txt:1:ヘッダー行
file002.txt:1:ヘッダー行
file003.txt:1:ヘッダー行
file004.txt:1:ヘッダー行
file005.txt:1:ヘッダー行
file006.txt:1:ヘッダー行もっと楽に!ということで、grepのファイル名・行番号の出力を止めて重複行を数えてみると、ざっくりと分かります。もし重複行がファイル数よりも多かったら変だなと分かります。sort | uniq にはよくお世話になりました。
$ grep -h "^ヘッダー行" file*txt | sort | uniq -c
100 ヘッダー行コマンドっていいですよね
ちなみに、記事を書くために準備したファイル100個もファイルもコマンド一発で作りました。これは一行だと無理がありますね。
$ for i in {1..100};do s=$(printf "%03d" "${i}") ; echo "${i}つ目のファイルの内容" > "file${s}.txt"; doneその昔、bashでのデータ処理の例をnoteに投稿したこともありましたが、受けは今一つ。最近はJupyterで分析しますからね……。
それでも私はコマンドを打つのが好きです。出番は減ってしまったのですが、コンピューターを道具としてシンプルに使っている感じがあって、手に馴染むように感じます。
もしかすると、コマンドというよりUNIXの思想が好きなのかもしれません。仕事に疲れたときは以下の本を読むことがあるのですが、心が洗われる気がします。
ということで、個人的に好きなLinuxコマンドラインシェルの話でした。
この記事が気に入ったらサポートをしてみませんか?