
Rを活用した地域課題解決のためのヒント NDB分析編 #6-10の予告(特定健診)

特定健診データの機械学習について
#6から特定健診データ(及び質問票)の機械学習(ML:Machine Learning)を事例を交えてやってみたいと思います。
機械学習は大別して、教師データなし学習と教師データあり学習があります。教師データなし学習としては、クラスター分析(クラスタリング)、主成分分析、因子分析などを、教師データあり学習としては、相関分析、多変量回帰分析(重回帰分析)、決定木(応用としてランダムフォレスト)などを予定しています。
教師データ(正解となるデータ)として何を使うかですが、opendata として使えるのが限られている中では、若干無理があるなあと思いつつ、平均寿命(健康寿命)を使ってみます。つまり、平均寿命を教師データとして使って、特定健診の結果との関係性を最適なモデルとして構築します。また、特定健診データを教師データとして質問票との関係モデルを作ってもいいかもしれません。
出来る限りn数が多い程良いので、都道府県(n:47)ではなく二次医療圏(n:334)で分析してみたいと思います。
下のグラフは全二次医療圏の特定健診の検査の平均値(全年齢階層の平均値)を男女別にplotしたものです。ビジーなグラフですが、都道府県CD順に左から並べています。1つの都道府県の縦軸に各都道府県に属する二次医療圏のデータが点として表現されています。都道府県のデータより粒度が上がっていますので、地域差がより可視化されています。傾向としてはBMIや中性脂肪などお椀型(北と南で検査値が高め)になっている項目が多いですね。なお、所々ゼロのデータ(レコード)があるので分析する場合は除いた方が良さそうです。
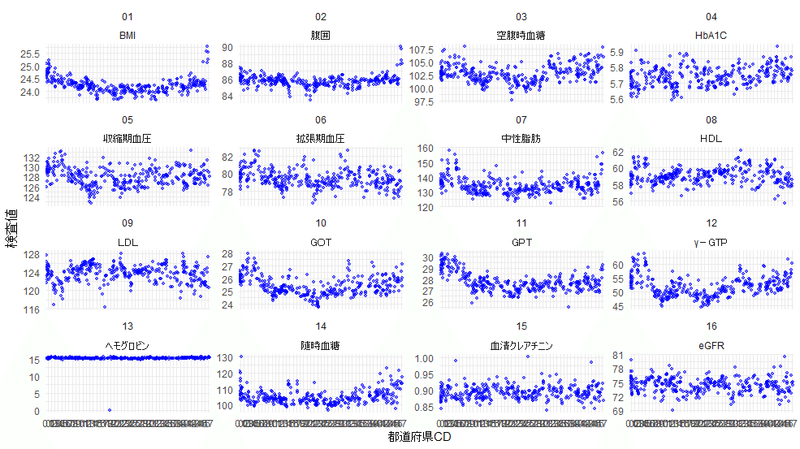
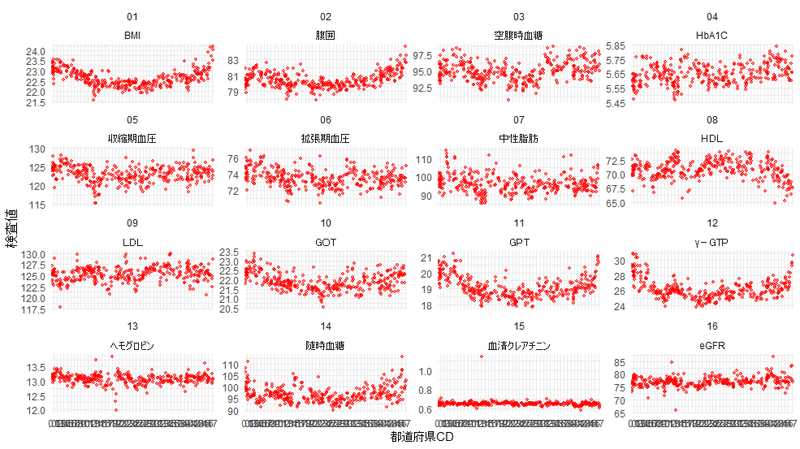
機械学習の例
教師データなし学習のサンプルとして二次医療圏の特定健診結果のうち男性の全年齢階層の平均値を使って階層クラスター分析(ウォード法)をやってみました。以下は実行結果の樹形図(デンドログラム)になります。二次医療圏CDの文字がつぶれて見えませんが、16項目の特定健診結果(男性)で似たような二次医療圏がクラスターとして分類されています。教師データがないので、この結果から何が言えるのか考える必要があります。
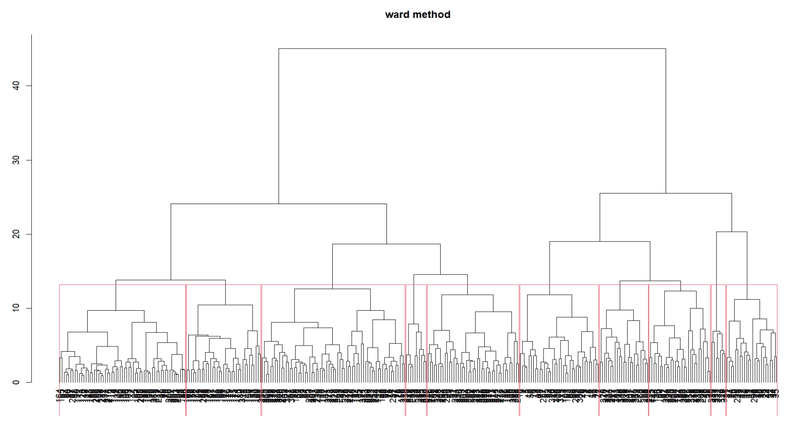
実際にはRスクリプトと実行結果、また実行結果のデータもダウンロードできるようにしてみますのでご期待ください。
この記事が気に入ったらサポートをしてみませんか?