
バッチサービスを独立させたら色々な非同期処理が捗った話

ナレッジワークのソフトウェアエンジニアの多久島(@yackrru)です。
ナレッジワークではバックエンドシステムには、Google CloudとGo言語を使用しています。その中の主なサービスはGKEで動いていましたが、GKE はメンテナンスが必要であるため、サーバーレス化を目論んで、これをCloud Runに移行する動きが出てきました。その話は別の機会に@yudoufuあたりが紹介してくれると思います。
ここで1つ問題があります。GKE上でサーバーを動かしていたときはgoroutineを使ったバックグラウンド処理をしてもCPUが割り当てられていたのですが、Cloud Runではalways-on CPUの設定をしなければリクエスト外の処理には CPU がほぼ割り当てられません。また、従来のバッチサービスはGKEで動いており、他のサービスとPodが同じで設定を共有していたためにタイムアウトの制限も短く、goroutineを使用したバックグラウンド処理をしている箇所がありました。したがって、従来のバッチサービスは単純にCloud Runに移行することができませんでした。
そこで、バッチサービスをGKEの他のサービスから切り離し、バッチサービス専用の独立したCloud Runの基盤を作ることになりました。今回は、そのバッチサービス開発の話を通してナレッジワークのバッチ処理アーキテクチャの紹介ができればと思います。
また、バッチサービスを作った副産物として非同期処理が容易になったので、その話も合わせて紹介します。
ナレッジワークの旧バッチ処理アーキテクチャとその問題
ナレッジワークのバッチはProtocol Buffers(以下、protoと呼ぶ)を使用したgRPCのAPIとして定義されており、HTTPリクエストにより呼び出すことができます。
次の図は従来のバッチサービスを簡易的に模したアーキテクチャです。
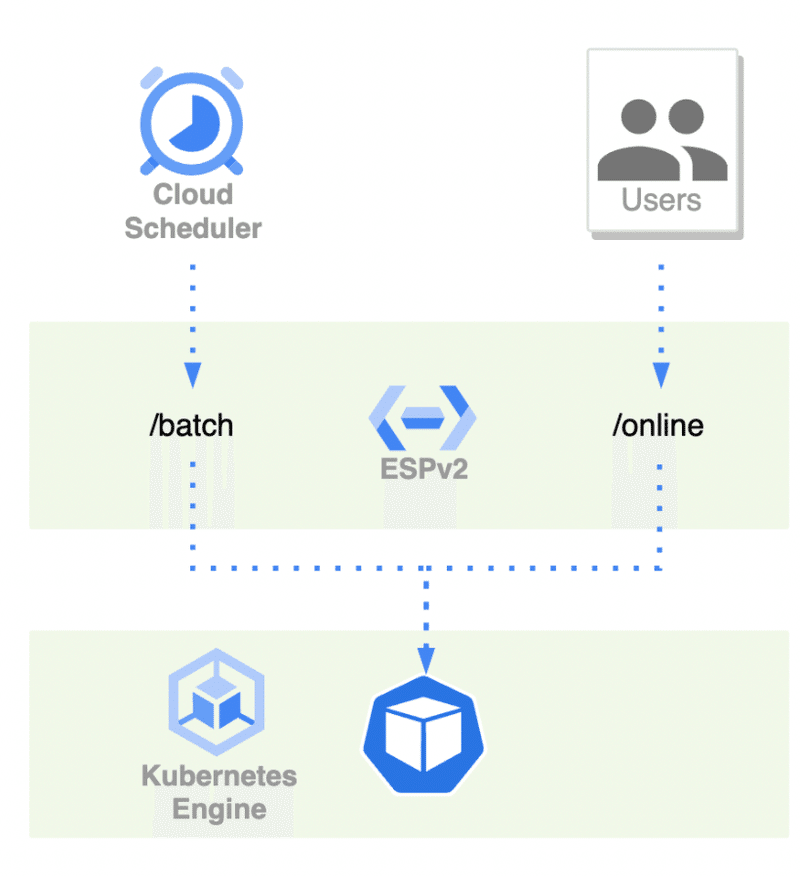
バッチの実行はESPv2にHTTP to gRPCの変換を通して、Cloud SchedulerからHTTPリクエストで呼ばれていました。従来のバッチサービスはオンライン用のAPIと同じ形式でデプロイされており、ESPv2 のタイムアウトの設定なども共有されていました。結果として、長時間実行できない、同じデプロイに乗っかっているが故にAPIレスポンスのメトリクスにバッチの長時間実行の結果が混じる、バッチの高負荷な実行がAPI実行に影響を及ぼすことがある、等の課題がありました。
解決策としての新バッチ処理アーキテクチャ
そこでバッチサービスをオンライン用APIのデプロイから切り離し、さらに保守を容易にするためにCloud Runにデプロイを乗せることにしました。これがタイトルにもある「バッチサービスの独立」を意味しています。
以下の図が新アーキテクチャの簡易図です。
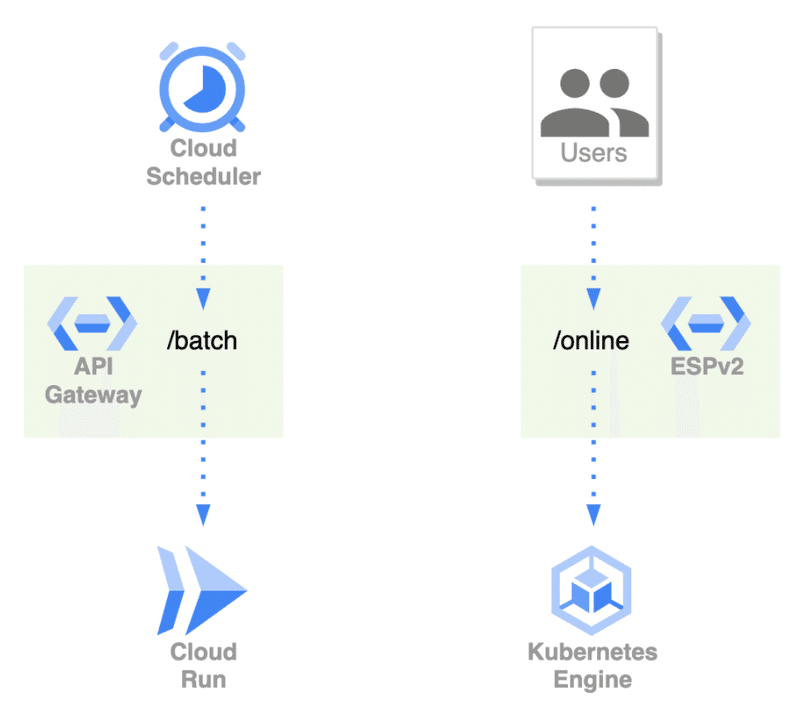
これまでHTTP to gRPCの変換はESPv2を通していましたが、新バッチサービスではAPI Gatewayを採用しました。技術選定の理由としては、マネージドサービスを使うことで保守をより楽にしようというものでした。また、今後使えるかもしれないサービスなので知見を得たいという意図もありました。
ナレッジワークではこういったインフラ構成の変更の際も、先にDesignDocを書いて議論をし、設計を固めてから着手します。DesignDocについては弊社CTOの@mayahが執筆した「ナレッジワークの開発体制」でも紹介されているので、合わせてご覧ください。
また、せっかくなのでバッチサービス分離のDesignDocの一部を載せておきます。
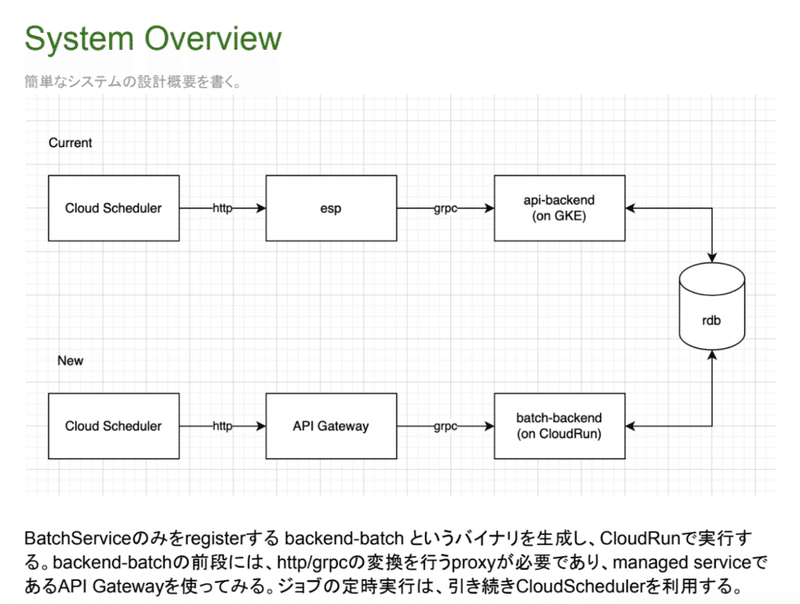
非同期処理が捗った話
バッチサービスを独立させた結果、これまで挙げた複数の問題が解決しました。
さらに、副産物として非同期処理が容易になりました。冒頭でも紹介したGKEで動いているオンライン用APIでは、時間がかかる処理にgoroutineを使用してバックグラウンドに処理する手法を取っていました。これをCloud Runに移行するとCPUが割り当てられなくなるため対策が必要でした。しかし、バッチサービスを独立させた結果、非同期に実行したい処理をバッチサービスにAPIとして実装し、オンライン用APIからCloud Tasks経由でバッチサービスを実行するという手法を取れるようになり、この課題が解決しました。
さて、読んでくださっている方の中には「そんなに非同期処理して保守性は下がらないの?」と心配な方もいることでしょう。
答えを先に申し上げると、現状保守性は下がっていません。
その理由は「型」の存在です。protoでAPIを定義することにより、Cloud Tasksにキューイングする際もprotoの形式でリクエストを作る必要があります。これにより、期待した型でのみ通信を行えるので、APIの型が変わった場合にも該当箇所をすぐに判別できます。
移行の結果
旧バッチ処理アーキテクチャの紹介で挙げた課題はすべてクリアすることができました。特にバッチの長時間実行が可能になり、バッチサービスを使用した開発の幅が広がりました。
これまでは長時間実行をするために専用のCloud Runを用意するサービスもありましたが、それをバッチサービスに移行するような動きも出てきています。
実行時間が伸びたことは成果ですが、依然として課題も残りました。Cloud Runは最大1時間実行できるようになっていますが、API Gatewayのタイムアウト設定が最大10分であることです(2022年9月現在)。サービスアップデートにより最大1時間まで伸びることを期待しています。
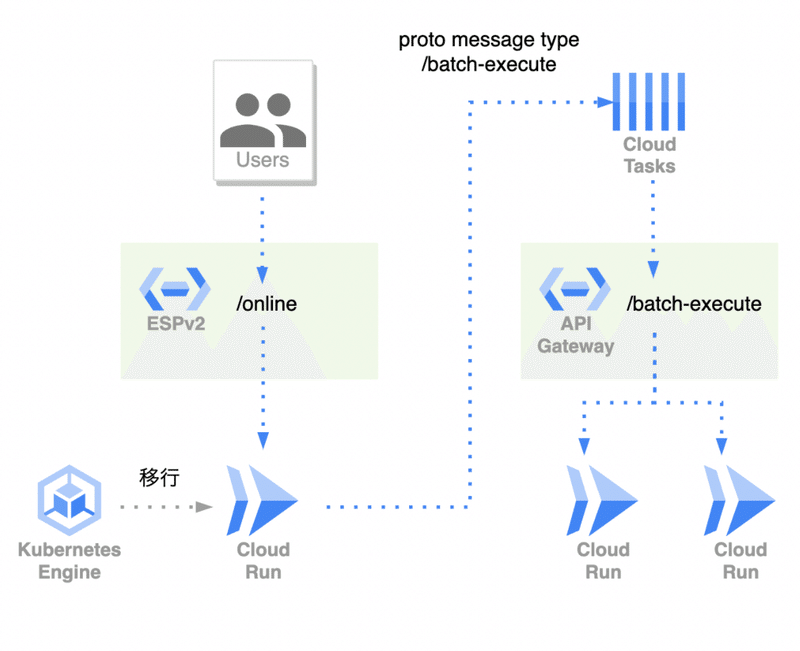
モノによっては10分以上かかるバッチというのは明らかに存在します。このようなバッチは現状次のような構成を取ることで回避しています(Cloud Pub/Subを使用していたり、全てがこの形式という訳ではありません)。
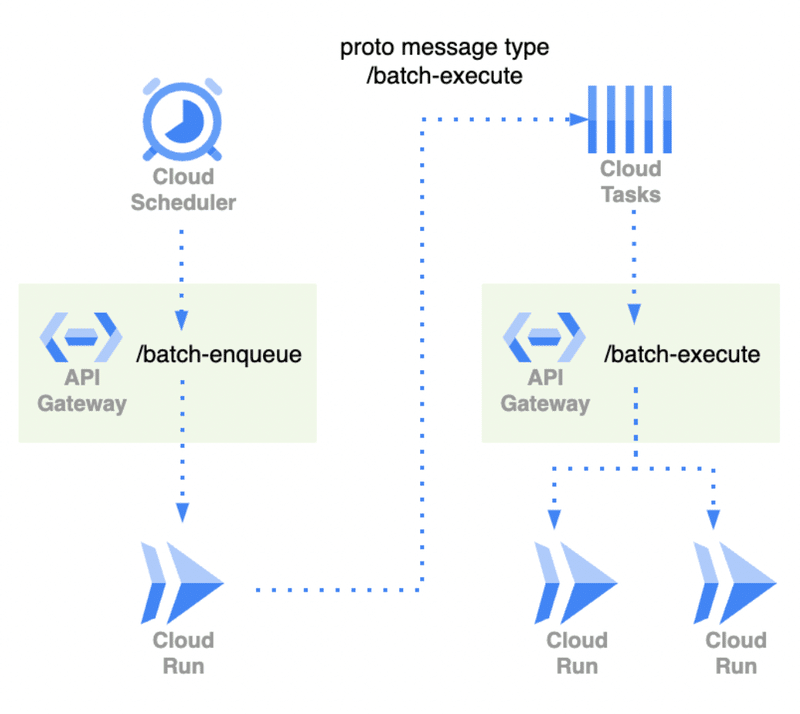
ナレッジワークはマルチテナントなシステムで、テナントごとに処理をすることができます。
上図のCloud Runは全てバッチサービスで、例えば、/batch-enqueueで実行されるAPIはテナントをListし、テナントごとに/batch-executeを実行するようにCloud Tasksにキューイングします。全体で実行すると長いがテナントごとの実行は短時間で済むというようなケースで有効です。
「非同期処理が捗った話」でも述べましたが、時間がかかるオンライン処理を非同期に実行したい場合にCloud Tasks経由でバッチサービスを実行するという仕組みができたことも、バッチサービス独立の成果のひとつです。
他にも、最近Cloud Run jobsがリリースされていたりするので、使えるかどうか調査してみたいと思っています。
個人としてのイネーブルメント
この業務に携わった結果、個人としても技術力の向上を達成することができました。特に大きかったのは、実務レベルのTerraform実装の経験ができたことです。
私は前職ではAWSを使用しておりアーキテクチャの設計なども行っていましたが、Terraformは私がいるチームではなく別のチームが管理しており、実務としてのTerraform実装経験はありませんでした。
しかし、ナレッジワークではSREメンバーによりレビューを受けながら、バックエンドメンバーでもTerraformを書くことができます(モノによってはフロントエンドメンバーが書いているのも見かけました)。
多少、develop環境→staging環境→production環境と反映していく流れで失敗もありましたが、「デプロイ戦略を見直す」という次のアクションにもつなげられています。この話はまた別の機会にできればと思います。
最後に
以上、ナレッジワークのバッチ処理アーキテクチャやそれを取り巻く非同期処理の話を紹介しました。
ナレッジワークの内部でどんな技術を使っているのか、システムがどんな風に構成されているのか、ということを知っていただいてナレッジワークに興味を持ってもらえたのであれば幸いです。
ナレッジワークでは、このブログで書いたように、問題は根本から解決しようとする傾向があります。解決できていないことはまだたくさんあります。また、サービス拡大や人員拡大に伴って、今まで上手くいっていたやり方が上手くいかなくなるケースもあります。
少しでも興味を持っていただけた方は、ぜひ話を聞きに来てください!一緒に世の中にイネーブルメントをお届けできるソフトウェアエンジニアを心待ちにしています。
まずは話を聞いてみたいという方も大歓迎ですので、その場合は下記カジュアル面談フォームよりご応募ください!