
Pythonでやってみた(画像処理編2):物体検出(YOLOv5)

1.概要
前回の記事でYOLOv3による物体検出をしてみましたがリアルタイムでの検出は環境構築が私には無理でした。
今回YOLOv5を使用したらすんなりいったので紹介します。
参考としてPCスペックは下記の通りでありGPUは「NVIDIA GeForce RTX3050 Laptop GPU」を積んでおります(おそらくGPUがないと処理速度的に動かないと思います)。

2.YOLOの比較
You only look once (YOLO) とはリアルタイムで高精度に物体を検出してくれるAIモデルです。詳細・実演はYOLOv3開発者:Joseph Redmon氏のTED公演をご確認ください。
YOLOv4以降ではJoseph Redmon氏は関与していないらしく独自の形で進化しており、2022年8月現在ではYOLOv7まで出ているとのことです。
Official YOLOv7 (state-of-the-art real-time detector) is more accurate and faster than:
— Alexey Bochkovskiy (@alexeyab84) July 7, 2022
- YOLOv5 by 120% FPS
- YOLOX by 180% FPS
- Dual-Swin-T by 1200% FPS
- ConvNext by 550% FPS
- SWIN-L CM-RCNN by 500% FPS
- PPYOLOE-X by 150% FPShttps://t.co/t5EOx3IdQahttps://t.co/utnk0nqu83 pic.twitter.com/jqLzRtfMNN
3.YOLOv5の環境構築
YOLOv5実装のための準備をします。私はWindowsユーザーですが、おそらくMac、Linuxでも同等な処理で実装できると思います。
3-1.関連ファイル/ライブラリ取得
まずは公式通りの手順でターミナル上から下記3つのコードを実行します。参考として私はターミナルとしてAnaconda Promptを使用しました。
[Terminal]
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt【環境構築の詳細説明】
①GitHubからファイルをダウンロード->yolov5フォルダが作成される
②作業ディレクトリをyolov5に移動
③yolov5に必要なライブラリをインストール
【出力の参照】


3-2.エラー発生時:coco128.yamlの修正
作成されたyolov5フォルダ内の"yolov5/data/coco128.yaml"を開いて(念のためにバックアップを取り)、下記1~7行目を削除して保存します。
[削除するエリア]
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: python train.py --data coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here (7 MB)
【修正の理由】
私の環境では本節の処理をせずに実行すると下記エラーが発生しました。エラー記載の通りcoco128.yaml内に読み取れない文字があるとのことです。
別の人はファイルを”shift-jis形式”に変更して対応したとのことです。
File "C:\Users\KIYO\anaconda3\lib\site-packages\yaml\reader.py", line 143, in check_printable
raise ReaderError(self.name, position, ord(character),
yaml.reader.ReaderError: unacceptable character #x0080: special characters are not allowed
in "data\coco128.yaml", position 227参考として自宅のWindows10だとエラーが出て、移動用のWindows11のノートPCだと修正なしでもエラーは発生しませんでした。
4.YOLOv5詳細設定
YOLOv5をより使いやすいようにするための設定をします。(5章の)動作は本設定がなくても動くため、とにかく動かしたい人は本章は飛ばしてもらっても問題ないです。
※5章において出力された動画が見れない人は4-2節はご確認ください。
4-1.OpenCVのコーデック変更:Windows
(おそらく)Windowsユーザーのみで発生するエラーだと思いますが、出力された動画を開こうとすると下記の通りエラーが出ます。

おそらくコーデックの相性が悪いと思うので"./yolov5/detect.py"のコーデック部分を書き換えました(mp4v->XVID, mp4->avi)。
修正後は動画を見れるようになりました。
[detect.py_修正前]
save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
[detect.py_修正後]
save_path = str(Path(save_path).with_suffix('.avi')) # 2022年8月修正:拡張子をaviに変更
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'XVID'), fps, (w, h)) # 2022年8月修正:コーデックを変更
【エラー詳細】
「コーデックをサポートしていない」とあるため、cv2.VideoWriter()におけるコーデック指定が悪いと思います。拡張子を".mp4"にした状態でコーデックをDIVX, XVID, MJPG, X264などで実行しましたが全部ダメでした。
いろいろ試した結果{"拡張子":".avi", "コーデック":"XVID"}でうまくいきました。
4-2.出力先の設定
デフォルトでは処理ファイルは"runs/detect"フォルダ内に"exp"フォルダが作成されて出力されます。
出力先パスと出力用フォルダ名を指定するには"./yolov5/detect.py"を開いて下記エリアを書き換えます。事前に指定フォルダに"output"フォルダを作成しておき、そのフォルダ内にデータが格納されるようにしました。
[detect.py]
def parse_opt():
#出力先のディレクトリを指定する
parser.add_argument('--project', default=ROOT / 'C:/Users/KIYO/Desktop/note/note_yolov5/output', help='save results to project/name')
#出力格納用フォルダ名の設定
parser.add_argument('--name', default='output', help='save results to project/name')
前章で実行したコードを同じように処理しました。出力は”Results saved to C:\Users\KIYO\Desktop\note\note_yolov5\output\output”となっており出力個所が変更されました。
[Terminal]
python detect.py --source "C:\Users\KIYO\Desktop\note\note_yolov5\konan.JPG"[OUT]
detect: weights=yolov5s.pt, source=C:\Users\KIYO\Desktop\note\note_yolov5, data=data\coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=C:\Users\KIYO\Desktop\note\note_yolov5\output, name=output, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False
YOLOv5 v6.1-391-g7639e4c Python-3.9.7 torch-1.10.1+cu113 CUDA:0 (NVIDIA GeForce RTX 3050 Laptop GPU, 4096MiB)
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs
image 1/1 C:\Users\KIYO\Desktop\note\note_yolov5\konan.JPG: 640x480 1 cat, 1 potted plant, Done. (0.010s)
Speed: 0.0ms pre-process, 10.0ms inference, 4.0ms NMS per image at shape (1, 3, 640, 640)
Results saved to C:\Users\KIYO\Desktop\note\note_yolov5\output\output
4-3.処理用フォルダの指定(--source省略)
コード実行時に毎回オプションとして"--source"を記載しますがファイルを一括で処理する場合は毎回記載するのは手間です。デフォルトで処理するフォルダを指定すれば"--source"の記載が不要になります。
今回は"input"フォルダを作成してそこをデフォルトに変更します。

"./yolov5/detect.py"を開きparse_out()関数内の'--source'にあるROOTの部分を指定フォルダに変更します。
[detect.py_修正前]
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')
[detect.py_修正後]
parser.add_argument('--source', type=str, default=ROOT / 'C:/Users/KIYO/Desktop/note/note_yolov5/input', help='file/dir/URL/glob, 0 for webcam')
このように設定すると"input"フォルダに入れたファイルは下記コードだけで処理可能となります。
[Terminal]
python detect.py5.YOLO実行:物体検出
物体検出(inferance)のコードは公式より下記の通りです。

デフォルトでは"--source"のルートパスは"data/images"です。オプション(--source)を指定せず下記コードを実行するとimagesフォルダ内にあるサンプル画像を物体検出して、"runs/detect"フォルダ内に結果が出力されます。
[Terminal]
python detect.py

5-1.リアルタイム検出:--source 0
ターミナル上から下記コードを実行する自動でWebCamが立ち上がりリアルタイムで検出されます。終了は「Ctrl+C」を押します。
[terminal]
python detect.py --source 0 [OUT ※初回の重みが自動でダウンロードされる]
detect: weights=yolov5s.pt, source=0, data=data\coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs\detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False
YOLOv5 v6.1-391-g7639e4c Python-3.9.7 torch-1.10.1+cu113 CUDA:0 (NVIDIA GeForce RTX 3050 Laptop GPU, 4096MiB)
Downloading https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt to yolov5s.pt...
100%|███████████████████████████████████████████████████████████████████████████████████| 14.1M/14.1M [00:01<00:00, 8.43MB/s]
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs
1/1: 0... Success (inf frames 640x480 at 30.00 FPS)
5-2.画像から検出:--source path
画像の検出は"source <画像のパス>"を渡します。一枚の画像を処理するなら画像のパス、複数の画像をまとめて処理する場合は画像が入っているフォルダのパスを指定します。
[Terminal]
python detect.py --source <img_path> or <img_folder>下記の通りファイルを配置したうえでコードを実行します。

[Terminal]
python detect.py --source "C:\Users\KIYO\Desktop\note\note_yolov5\konan.JPG"実行後はターミナルに下記が出力されます。出力内に”1 cat, 1 potted plant, Done.”とあり検出された物体名が記載されております。
[OUT]
detect: weights=yolov5s.pt, source=C:\Users\KIYO\Desktop\note\note_yolov5\konan.JPG, data=data\coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs\detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False
YOLOv5 v6.1-391-g7639e4c Python-3.9.7 torch-1.10.1+cu113 CUDA:0 (NVIDIA GeForce RTX 3050 Laptop GPU, 4096MiB)
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs
image 1/1 C:\Users\KIYO\Desktop\note\note_yolov5\konan.JPG: 640x480 1 cat, 1 potted plant, Done. (0.016s)
Speed: 0.0ms pre-process, 15.6ms inference, 0.0ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp3処理後画像はyolov5フォルダ内の"runs\detect\exp3"に出力されます。各処理でフォルダが作成される出力先はターミナル内をご確認ください。

【複数の画像処理】
先と同じフォルダに複数の画像を配置しました。複数画像を処理する場合はコードに渡すパスとしてフォルダを指定して実行します。

[Terminal]
python detect.py --source "C:\Users\KIYO\Desktop\note\note_yolov5"[OUT]
detect: weights=yolov5s.pt, source=C:\Users\KIYO\Desktop\note\note_yolov5, data=data\coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs\detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False
YOLOv5 v6.1-391-g7639e4c Python-3.9.7 torch-1.10.1+cu113 CUDA:0 (NVIDIA GeForce RTX 3050 Laptop GPU, 4096MiB)
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs
image 1/2 C:\Users\KIYO\Desktop\note\note_yolov5\konan - .JPG: 640x480 1 cat, 1 potted plant, Done. (0.011s)
image 2/2 C:\Users\KIYO\Desktop\note\note_yolov5\konan.JPG: 640x480 1 cat, 1 potted plant, Done. (0.009s)
Speed: 0.0ms pre-process, 9.9ms inference, 2.5ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp4
(base) C:\Users\KIYO\Desktop\note\note_yolov5\yolov5>フォルダを指定してコードを実行すると"runs\detect\exp"フォルダ内に物体検出された複数の画像が出力されました。

5-3.動画から検出:--source path
動画関係の物体検出をします。 動画の処理方法は画像処理と同じで"source <動画のパス>"です。
サンプル動画は下記より取得してファイル名は"samplemovie.mp4"で保存しました。
[Terminal]
python detect.py --source "C:\Users\KIYO\Desktop\note\note_yolov5\samplemovie.mp4"
5-4.Youtube
Youtube動画の検出はsourceの後ろにYoutubeの動画URLを指定します。ちなみにShort動画で実行した場合は「ValueError: Need 11 character video id or the URL of the video.」のエラーが発生したためあきらめました。
[Terminal]
python detect.py --source <Youtubeのショートパス(共有からコピー)>サンプル動画として『千鳥・ノブがSKE48須田亜香里にNG発言連発!? 千鳥MC『チャンスの時間 # 129』』を使用しました。
[Terminal]
python detect.py --source https://youtu.be/Yx1CqlmLJSs
[OUT]
下記参照
5-5.複数ファイルの一括処理
複数のファイルを処理する場合は"source <ファイルがあるディレクトリ>"で処理します。サンプルコードは下記の通りです。
[Terminal]
python detect.py --source "C:\Users\KIYO\Desktop\note\note_yolov5"
下記の通り指定フォルダにあるファイル(画像と動画ファイル)をまとめて処理できました。

6.YOLOの転移学習:専用モデルの作成
前章では開発者が作成した学習モデル(重み)を使用しているため、簡単に実行できる反面、自分が検出したいものが検出できないこともあります。
本章では自分でYOLOを学習させて自分専用の物体検出モデルを作成していきます。主な手順は下記の通りです。
【YOLOv5のモデル学習フロー】
1.データ収集(+アノテーション)
2.data.yamlの作成
3.モデルの学習・検証
6-1.学習用データ収集
データのダウンロード方法は下記記事を参考にしました。
まずは学習用のデータを集めます。今回は「roboflow」のMask Wearing Datasetを使用します。データ数は149枚しかありませんが全データにアノテーションがされているためそのまま使用できます。
なお上記のURLからDownloadできない(ポップアップがでない)場合は「Mask Wearing Computer Vision Project」のサイトからroboflowのアカウントでログインするとできると思います。

DLしたフォルダ"Mask Wearing.v4-raw.darknet"の構成は[学習、検証、テスト]用フォルダの中に(画像とラベル)が1Setで入っています。ラベルは{0:"マスクあり", 1:"マスクなし"}であり位置座標もあります(ラベル詳細は別添参照)。
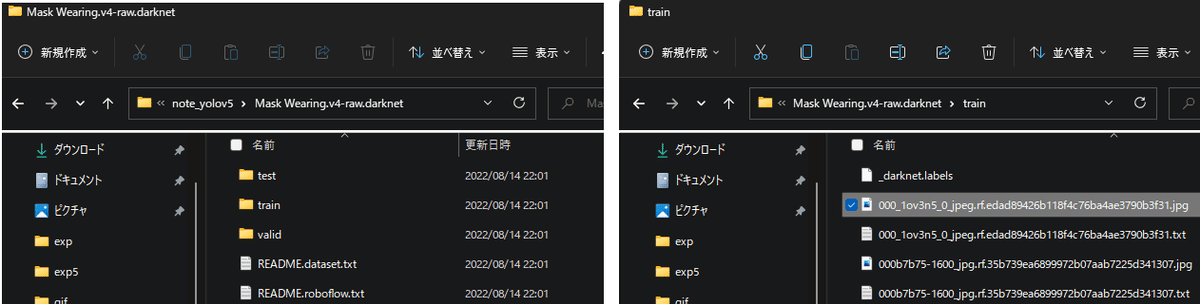

【ラベル情報に関して】
ラベルは"分類クラス x座標 y座標 幅 高さ"の順で記載されています。詳細は本記事の別添をご確認ください。

[ラベルのサンプル ※[oject-class] [x_center] [y_center] [width] [height]]
0 0.480000 0.630000 0.690000 0.710000
0 0.740000 0.520000 0.310000 0.930000
27 0.360000 0.790000 0.070000 0.400000【ラベルの意味】
●oject-class:クラスの番号。yamlファイルの内容と合わせる
●x_center:bounding box 中心のx座標
●y_center:bounding box 中心のy座標
●width:bounding box x方向長さ
●height:bounding box y方向長さ
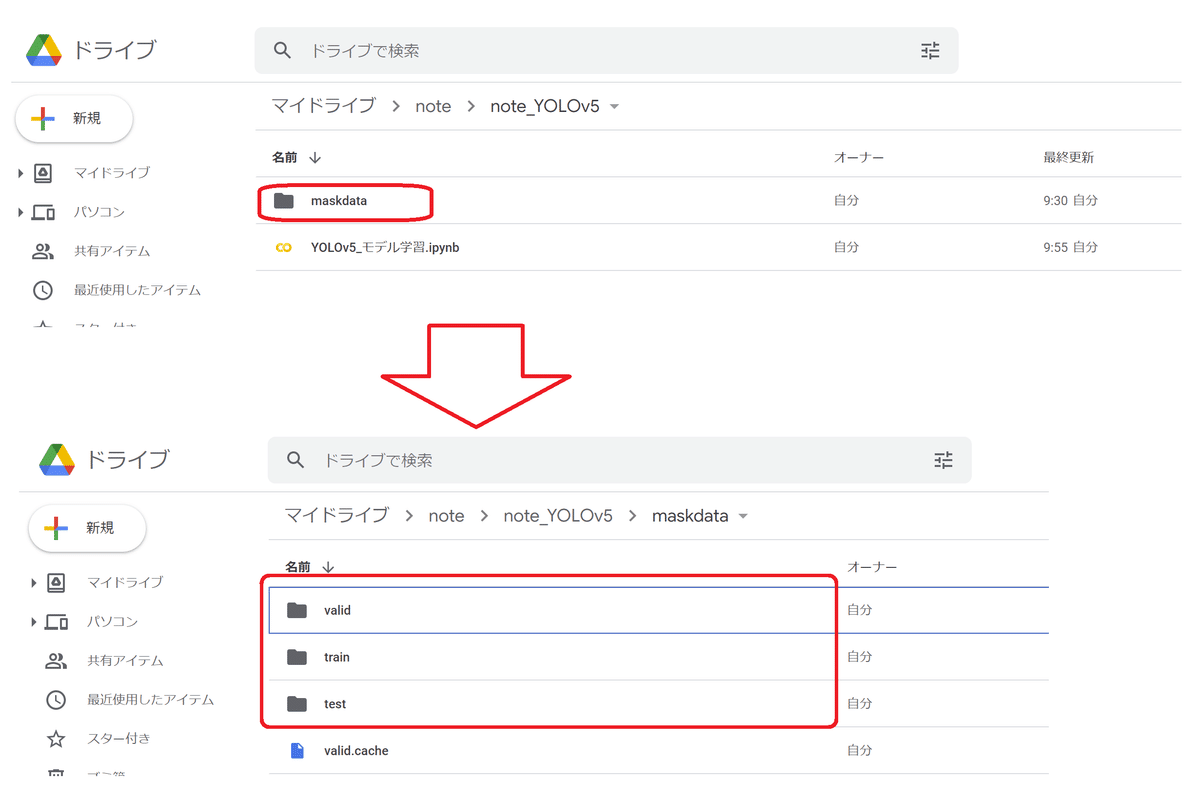
6-2.データの配置/Google Colab準備
データ学習が私のPCではうまくいかなかったためGoogle Colabを使用しました。Google Drive上に"maskdata"フォルダを作成して前節の学習用データを保存します。
学習前にColabの”ノートブックの設定”からGPUの設定しておきます。
6ー3.data.yamlの作成
YOLOv5でデータ学習用のデータパス、分類数、分類名は"data.yaml"で指定します。ローカルPCでのサンプルコードは下記の通りです。
(Colab上のサンプルコードではyamlはコードで作成しました。)
[data.yaml]
#データのパスを指定
train: C:/Users/KIYO/Desktop/note/note_yolov5/maskdata/train
val: C:/Users/KIYO/Desktop/note/note_yolov5/maskdata/valid
#分類の数
nc: 2
#分類名
names: ["mask", "no-mask"]6-4.モデルの学習:python train.py
モデルを学習してきます。学習時はterminalの作業位置を"train.py"があるフォルダ(デフォルト:yolov5)に移動して下記コードを実行します。
[Terminal]
python train.py --batch <バッチ数> --epochs <エポック数> --data <data.yamlのパス>【学習モデルの引数】
●--batch:学習1回あたりに使用するデータ数
●--epochs:学習の回数
●--data:data.yamlファイルのパス
Gooble Colabでは初期設定から実施するため全コードは下記の通りです。textのtrain:, val: 後ろのパスを自分が6-1節で保存したデータパスに変更すれば同じコードで実行できると思います(GPU有で10-14分くらいかかります)。
ちなみにGoogle Colabでは3-2節 coco128.yamlの修正は不要でした。

[IN]
!git clone https://github.com/ultralytics/yolov5 # GitHubからyolov5フォルダを取得
%cd yolov5 #作業ディレクトリをyolov5に変更
%pip install -r requirements.txt #必要ライブラリをインストール
from google.colab import drive
drive.mount('/gdrive') #Google Driveをマウント
text = """#データのパスを指定
train: /gdrive/MyDrive/note/note_YOLOv5/maskdata/train
val: /gdrive/MyDrive/note/note_YOLOv5/maskdata/valid
#分類の数
nc: 2
#分類名
names: ["mask", "no-mask"]
"""
#data.yamlを作成
with open('data.yaml', 'w') as f:
f.write(text)
!python train.py --batch 16 --epochs 100 --data /content/yolov5/data.yaml[OUT]
train: weights=yolov5s.pt, cfg=, data=/content/yolov5/data.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=100, batch_size=16, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs/train, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
github: up to date with https://github.com/ultralytics/yolov5 ✅
YOLOv5 🚀 v6.1-394-gd7bc5d7 Python-3.7.13 torch-1.12.1+cu113 CUDA:0 (Tesla T4, 15110MiB)
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Weights & Biases: run 'pip install wandb' to automatically track and visualize YOLOv5 🚀 runs in Weights & Biases
ClearML: run 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 🚀 runs in ClearML
TensorBoard: Start with 'tensorboard --logdir runs/train', view at http://localhost:6006/
Downloading https://ultralytics.com/assets/Arial.ttf to /root/.config/Ultralytics/Arial.ttf...
100% 755k/755k [00:00<00:00, 18.0MB/s]
Downloading https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt to yolov5s.pt...
100% 14.1M/14.1M [00:00<00:00, 138MB/s]
Overriding model.yaml nc=80 with nc=2
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 18879 models.yolo.Detect [2, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model summary: 270 layers, 7025023 parameters, 7025023 gradients, 16.0 GFLOPs
Transferred 343/349 items from yolov5s.pt
AMP: checks passed ✅
optimizer: SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 60 weight(decay=0.0005), 60 bias
albumentations: Blur(always_apply=False, p=0.01, blur_limit=(3, 7)), MedianBlur(always_apply=False, p=0.01, blur_limit=(3, 7)), ToGray(always_apply=False, p=0.01), CLAHE(always_apply=False, p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))
train: Scanning '/gdrive/MyDrive/note/note_YOLOv5/maskdata/train.cache' images and labels... 105 found, 0 missing, 0 empty, 0 corrupt: 100% 105/105 [00:00<?, ?it/s]
val: Scanning '/gdrive/MyDrive/note/note_YOLOv5/maskdata/valid.cache' images and labels... 29 found, 0 missing, 0 empty, 0 corrupt: 100% 29/29 [00:00<?, ?it/s]
Plotting labels to runs/train/exp/labels.jpg...
AutoAnchor: 5.89 anchors/target, 0.999 Best Possible Recall (BPR). Current anchors are a good fit to dataset ✅
Image sizes 640 train, 640 val
Using 2 dataloader workers
Logging results to runs/train/exp
Starting training for 100 epochs...
Epoch gpu_mem box obj cls labels img_size
0/99 3.73G 0.121 0.06306 0.02933 79 640: 100% 7/7 [00:08<00:00, 1.20s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 0% 0/1 [00:00<?, ?it/s]WARNING: NMS time limit 1.170s exceeded
Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 1/1 [00:04<00:00, 4.47s/it]
all 29 162 0.00146 0.0282 0.000863 0.000262
~以下省略~
Epoch gpu_mem box obj cls labels img_size
99/99 4.33G 0.02685 0.0373 0.00427 56 640: 100% 7/7 [00:06<00:00, 1.07it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 1/1 [00:00<00:00, 1.85it/s]
all 29 162 0.932 0.777 0.894 0.604
100 epochs completed in 0.230 hours.
Optimizer stripped from runs/train/exp/weights/last.pt, 14.5MB
Optimizer stripped from runs/train/exp/weights/best.pt, 14.5MB
Validating runs/train/exp/weights/best.pt...
Fusing layers...
Model summary: 213 layers, 7015519 parameters, 0 gradients, 15.8 GFLOPs
Class Images Labels P R mAP@.5 mAP@.5:.95: 100% 1/1 [00:00<00:00, 1.27it/s]
all 29 162 0.93 0.789 0.905 0.611
mask 29 142 0.92 0.81 0.922 0.622
no-mask 29 20 0.939 0.769 0.889 0.601
Results saved to runs/train/exp
学習が完了すると”runs/train/exp/weights/”に学習した重みが出力されるためDLしてローカルPCに保存します。
私はローカルPC上にweightsフォルダを作成してその中に配置しました。

6-5.学習済みモデルによる推論:--weights
学習した重みを使用して物体検出を実施します。重みの指定は--weightを指定します。
[Terminal]
python detect.py --weight <学習した重みファイルのパス>
[Terminal:学習用データも指定]
python detect.py --source<データのディレクトリ> --weight <学習した重みファイルのパス>参考用画像はinputフォルダに保存して、デフォルトの重みと学習した重み(last.pt)の2つで実行しました。
[Terminal:デフォルト]
python detect.py --source C:\Users\KIYO\Desktop\note\note_yolov5\input
[Terminal:重み使用]
python detect.py --source C:\Users\KIYO\Desktop\note\note_yolov5\input --weights "C:\Users\KIYO\Desktop\note\note_yolov5\weights\last.pt"

結果を確認すると重みを使用した方ではデフォルトで検出できていたものがなくなる代わりにマスクをしている人が検出できました。ただしデータ数が少ないため誤検出もあります。
精度を上げるにはデータ数を増やすか他のモデルを使用できます。
6-6.参考:ローカル上でのエラー対応
ローカルPCで実行したところ下記エラーが発生してPCメモリが100%近くまで上昇しました。
おそらくメモリが足りないため仮想メモリを増加させれば対応できると思います。ただし毎回再起動しないといけないため今回は検証しておりません。必要が出たタイミングで確認予定です。
[TERMINAL]
python train.py --batch 16 --epochs 100 --data ./data.yaml
[OUT]
OSError: [WinError 1455] ページング ファイルが小さすぎるため、この操作を完了できません。 Error loading "C:\Users\KIYO\anaconda3\lib\site-packages\torch\lib\cudnn_cnn_infer64_8.dll" or one of its dependencies.
forrtl: error (200): program aborting due to control-C event7.別添 アノテーションによるラベル作成:VOTT
6章のデータ学習ではroboflowのラベル付きのデータセットを使用しましたが通常はデータ用画像もラベル付け(”アノテーション)も自分で行う必要があります。
詳細は下記記事にまとめましたのでご確認ください。
参考資料
あとがき
YOLOv3で苦労したアレはなんだったんだろうか・・・・・
この記事が気に入ったらサポートをしてみませんか?