
Pythonライブラリ(画像生成):StyleGAN3

1.緒言
1-1.概要
画像から画像を作成する技術(img2img)として有名なAIモデルにStyleganがあります。今回は最新Versionのstylegan3を実装しました。
1-2.Stylegan1, 2の実装に関する所感
stylegan1,2を実装しようと試みましたが環境構築で無理でした。ver.1,2はtensorflowの1.x系向けで作成されており、2022年9月現在のtensorflowは2.9系までVersion Upしております。
特に1.0系と2.0系でAPI仕様に大きな変化が出ており初学者レベルでは1.0系向けに作られたスクリプトを2.0系で使用することはムリゲーです。参考までに下記を実施してみましたがすべて無理でした(get_default_session()のエラーが抜けなかった)。
【stylegan1,2でのトライアル】
※基本的にはGoogle colabで実行
Version違いによる属性エラーの場合、エラー箇所に"compat.v1"を追加
”import tensorflow as tf”->"import tensorflow.compat.v1 as tf tf.disable_v2_behavior()"に変更
処理前に"%tensorflow_version 1.x"を実行->Colabではエラー
[どうしても消せなかったエラー]
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_13020/4120020643.py in <module>
----> 1 tflib.init_tf()
c:\Users\KIYO\Desktop\note\12. Python-Art\08. stylegan\stylegan\dnnlib\tflib\tfutil.py in init_tf(config_dict)
95
96 def init_tf(config_dict: dict = None) -> None:
---> 97 # Skip if already initialized.
98 if tf.get_default_session() is not None:
99 return
AttributeError: module 'tensorflow' has no attribute 'get_default_session'2.仮想環境の作成
仮想環境で開発していきますがどこまでPCの影響が出るかを理解できていません。参考までに私のPCではすでにCUDAのセットアップは終えておりNVCC(Nvidia CUDA コンパイラ)コマンドを入れると下記が出力されます。
[Terminal]
nvcc -V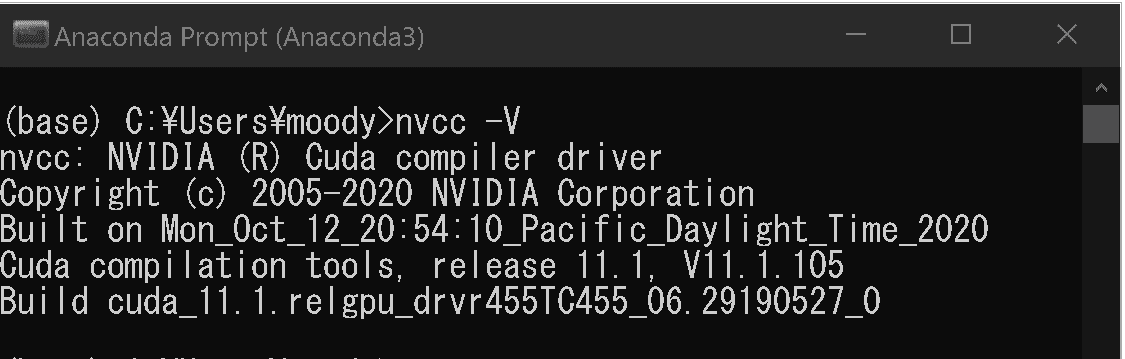
必要環境条件の詳細(各種VersionやOS)は「公式:Requirements」をご確認ください。
2-1.GitHubからstylegan3ファイルのDL
下記コードを実行して「NVIDIA Research Projects」のGithubからstylegan3のファイルをダウンロードします。処理が完了すると"stylegan3"フォルダが作成されます。
[Terminal]
git clone https://github.com/NVlabs/stylegan3.git
2-2.YAMLファイル修正
Anacondaを使用してstylegan3用の仮想環境を作成します。仮想環境の構築やコマンドは下記記事をご確認ください。
stylegan3ファルダ内に仮想環境を作成するための"environment.yml"がありますがこのままだとエラーになります。
[エラー内容]
Collecting package metadata (repodata.json): done
Solving environment: failed
ResolvePackageNotFound:
- cudatoolkit=11.1 修正方法として"cudatoolkit=11.1"の位置をpipの下へ移動させます。
(※参考までに「Windows11でStyleGAN3を試してみる」ではChannelsに"- conda-forge"を追記しています)
[修正後environment.yml"]
name: stylegan3
channels:
- pytorch
- nvidia
dependencies:
- python >= 3.8
- pip
- numpy>=1.20
- click>=8.0
- pillow=8.3.1
- scipy=1.7.1
- pytorch=1.9.1
- requests=2.26.0
- tqdm=4.62.2
- ninja=1.10.2
- matplotlib=3.4.2
- imageio=2.9.0
- pip:
- imgui==1.3.0
- glfw==2.2.0
- pyopengl==3.1.5
- imageio-ffmpeg==0.4.3
- pyspng
- cudatoolkit=11.1
2-3.仮想環境(stylegan3)の作成
YAMLファイルを修正したら作業ディレクトリをstylegan3へ移動して仮想環境を作成するコードを実行します。成功すれば各種パッケージのインストールが始まります。
[Terminal]
cd stylegan3
conda env create -f environment.yml完了後に仮想環境の一覧を出力してstylegan3という仮想環境が作成されていれば成功です。
[Terminal]
conda info -e
[OUT]
# conda environments:
#
base * C:\Users\KIYO\Anaconda3
stylegan3 C:\Users\KIYO\Anaconda3\envs\stylegan3【参考】
なんかエラーっぽい内容が出力されていますがとりあえず動いているからヨシ
done
Installing pip dependencies: - Ran pip subprocess with arguments:
['C:\\Users\\KIYO\\Anaconda3\\envs\\stylegan3\\python.exe', '-m', 'pip', 'install', '-U', '-r', 'C:\\Users\\KIYO\\Desktop\\note\\12. Python-Art\\09. stylegan3\\stylegan3\\condaenv.j3al44qt.requirements.txt']
Pip subprocess output:
Pip subprocess error:
Fatal Python error: init_import_size: Failed to import the site module
Python runtime state: initialized
Traceback (most recent call last):
File "C:\Users\KIYO\Anaconda3\lib\site.py", line 580, in <module>
main()
File "C:\Users\KIYO\Anaconda3\lib\site.py", line 566, in main
known_paths = addusersitepackages(known_paths)
File "C:\Users\KIYO\Anaconda3\lib\site.py", line 316, in addusersitepackages
addsitedir(user_site, known_paths)
File "C:\Users\KIYO\Anaconda3\lib\site.py", line 208, in addsitedir
addpackage(sitedir, name, known_paths)
File "C:\Users\KIYO\Anaconda3\lib\site.py", line 164, in addpackage
for n, line in enumerate(f):
File "C:\Users\KIYO\Anaconda3\lib\codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x82 in position 37: invalid start byte
failed
CondaEnvException: Pip failed2-4.仮想環境の起動:activate stylegan3
仮想環境の生成が確認出来たら起動させます。Terminalの頭が(base)->(stylegan3)に変更されていたら準備は完了です。
[Terminal]
activate stylegan32-5.追加ライブラリのインストール
本節は飛ばしてもよいですがもし動かない場合はエラー文に応じて各種ライブラリをインストールします。
[Terminal]
pip install imageio-ffmpeg #動画生成時[visualizer.py使用時]
>pip install imgui
pip install glfw
pip install pyopengl3.stylegan3のオプション
stylegan3のコマンドで使用するオプションを確認します。
3-1.画像用:gen_images.py
オプションは画像生成用スクリプト”gen_images.py”から確認しました。
【stylegan3のオプション】
●--outdir:出力結果を保存するディレクトリ
●--trunc{default=1}:(おそらく)input dataに対する変化の度合い:0は変化がなく数値が大きくなるにつれて出力がinputからずれていく
●--seeds:乱数シード->与える数値で画像が変化する (0-3と記載すれば4つの乱数値を与えて4枚の画像を出力できる。
●--network:学習済みモデルを取得するためのURL指定
●--class:ー
●--noise-mode{default='const'}:ー
●--translate{default=0.0}:-
●--rotate{default=0}:回転させる角度
3-2.動画用:gen_video.py
オプションは動画生成用スクリプト”gen_video.py”から確認しました。
【stylegan3のオプション】
●--output:出力するmp4ファイルのパスを指定
●--trunc{default=1}:(おそらく)input dataに対する変化の度合い:0は変化がなく数値が大きくなるにつれて出力がinputからずれていく
●--seeds:乱数シード->与える数値で画像が変化する (0-3と記載すれば4つの乱数値を与えて4枚の画像を出力できる。
●--shuffle-seeds{default:None}:シードをランダムで指定
●--network:学習済みモデルを取得するためのURL指定
●--grid{default:(1,1)}:幅高さ(W/H)方向に並べる画像配置数
●--num-keyframes{default:120}:補間するシードの数(指定がない場合は--seedの値から決定)
●--w-frames{default:1}:潜在間の補正をするためのフレーム数
4.学習済みモデルで画像生成
StyleGAN3の学習モデルは複数のモデルがあり"https://api.ngc.nvidia.com/
v2/models/nvidia/research/stylegan3/versions/1/files/<MODEL>"のように指定することでAPI経由で実行できます。モデル一覧は下記の通りです。
【StyleGAN3 pre-trained models】
●stylegan3-t-ffhq-1024x1024.pkl
●stylegan3-t-ffhqu-1024x1024.pkl
●stylegan3-t-ffhqu-256x256.pkl
●stylegan3-r-ffhq-1024x1024.pkl
●stylegan3-r-ffhqu-1024x1024.pkl
●stylegan3-r-ffhqu-256x256.pkl
●stylegan3-t-metfaces-1024x1024.pkl
●stylegan3-t-metfacesu-1024x1024.pkl
●stylegan3-r-metfaces-1024x1024.pkl
●stylegan3-r-metfacesu-1024x1024.pkl
●stylegan3-t-afhqv2-512x512.pkl
●stylegan3-r-afhqv2-512x512.pkl
乱数シードと学習モデルを固定すれば同じ出力結果が得られますので参考結果は下記ご確認ください。
なお学習モデルはAPIを使用せず下記からダウンロードも可能です。
4-1.AFHQv2で画像生成
NVIDIAの学習済みモデルAFHQv2(stylegan3-r-afhqv2-512x512.pkl)を使用して乱数値から画像を生成します。成功すると"out"フォルダが作成され猫の画像が生成されます。
[Terminal]
python gen_images.py --outdir=out --trunc=1 --seeds=2 --network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-afhqv2-512x512.pkl
[OUT]
Loading networks from "https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-afhqv2-512x512.pkl"...
C:\Users\KIYO\Anaconda3\envs\stylegan3\lib\site-packages\scipy\__init__.py:146: UserWarning: A NumPy version >=1.16.5 and <1.23.0 is required for this version of SciPy (detected version 1.23.1
warnings.warn(f"A NumPy version >={np_minversion} and <{np_maxversion}"
Generating image for seed 2 (0/1) ...
Setting up PyTorch plugin "bias_act_plugin"... Done.
Setting up PyTorch plugin "filtered_lrelu_plugin"... Done.
シードの指定を"--seedI0-3"のように指定すると乱数値を"0, 1, 2, 3"のように指定した形となり計4枚の画像が出力されます。
[IN]
python gen_images.py --outdir=out --trunc=1 --seeds=0-3 --network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-afhqv2-512x512.pkl
[OUT]
Loading networks from "https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-afhqv2-512x512.pkl"...
C:\Users\KIYO\Anaconda3\envs\stylegan3\lib\site-packages\scipy\__init__.py:146: UserWarning: A NumPy version >=1.16.5 and <1.23.0 is required for this version of SciPy (detected version 1.23.1
warnings.warn(f"A NumPy version >={np_minversion} and <{np_maxversion}"
Generating image for seed 0 (0/4) ...
Setting up PyTorch plugin "bias_act_plugin"... Done.
Setting up PyTorch plugin "filtered_lrelu_plugin"... Done.
Generating image for seed 1 (1/4) ...
Generating image for seed 2 (2/4) ...
Generating image for seed 3 (3/4) ...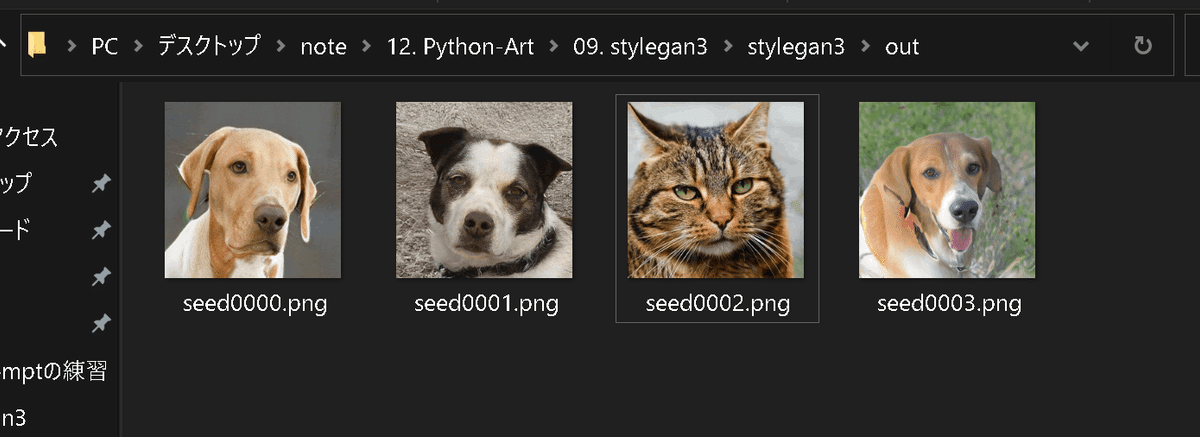
【参考:学習モデルの重み】
--networkに指定したURLから学習モデルの重み(Pickles)を取得しますが重みは"$HOME/.cache/dnnlib"に保存されています。
[]
"C:/Users/KIYO/.cache/dnnlib/downloads/20755e1ffb4380580e4954f8b0f9e630_stylegan3-r-afhqv2-512x512.pkl"4-2.学習済みモデルAFHQv2で動画生成
次に動画を作成します。下記条件では「乱数シード0~31を補間(内挿)して生成した画像を4×2グリッドに配置」となります。
[Terminal]
python gen_video.py --output=lerp.mp4 --trunc=1 --seeds=0-31 --grid=4x2 --network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-afhqv2-512x512.pkl
参考資料
参考資料1:実装関係
参考資料2:技術関係
参考資料3:StyleGANの記事
あとがき
取り急ぎ先出。stable diffusionの方が汎用性高そうなのでそちらに力注ぐ間も
この記事が気に入ったらサポートをしてみませんか?