
アルゴリズムの秘密: Google 検索の内部エンジニアリング文書が流出

Google のアルゴリズムについて常に知りたかったことを学びましょう。
グーグル、もしこれを読んでいるなら、もう手遅れだ。
OK 指を鳴らす。 本題に入ろう。 Google SearchのContent Warehouse APIの内部文書が流出した。
Google の内部マイクロサービスは、Google Cloud Platform が提供するものを反映しているようで、非推奨の Document AI Warehouseのドキュメントの内部バージョンが誤ってクライアント ライブラリのコード リポジトリに公開されました。このコードのドキュメントは、外部の自動ドキュメント サービスによって取得されたものでもあります。
変更履歴に基づくと、このコード リポジトリの間違いは 5 月 7 日に修正されましたが、自動化されたドキュメントはまだ公開されています。潜在的な責任を制限するため、ここではリンクしませんが、そのリポジトリ内のすべてのコードは Apache 2.0 ライセンスに基づいて公開されていたため、これに遭遇した人には、使用する能力を含む幅広い権利が付与されました。とにかく修正して配布してください。

私は API リファレンス ドキュメントを確認し、他の過去の Google リークや司法省の独占禁止法に関する証言と照らし合わせて説明しました。私はそれを、私の近刊の本「The Science of SEO」のために行った広範な特許およびホワイトペーパーの調査と組み合わせています。私が確認したドキュメントには Google のスコアリング機能に関する詳細は記載されていませんが、コンテンツ、リンク、ユーザー インタラクション用に保存されたデータに関する情報は豊富にあります。また、操作および保存されている機能についてのさまざまな程度の説明 (残念なほど希薄なものから、驚くほど明らかなものまで) もあります。
これらを広く「ランキング要素」と呼びたくなるかもしれませんが、それは不正確です。それらの多く、さらにはほとんどがランキング要因になりますが、そうでないものも多くあります。ここで私が行うことは、私の広範な調査と Google が伝えたことに基づいて、最も興味深いランキング システムと機能のいくつかを文脈化することです (少なくとも、この大規模なリークを調査して最初の数時間で見つけることができたもの)。何年にもわたって私たちに嘘をつきました。
「嘘をついた」という言葉は厳しいですが、ここで使うのに正確な言葉はこれだけです。私は、機密情報を保護している Google の代表者を必ずしも非難するわけではありませんが、再現可能な発見を発表したマーケティング、テクノロジー、ジャーナリズムの世界の人々の信用を積極的に貶めようとする彼らの取り組みには異議を唱えています。これらのトピックについて話す将来の Google 社員へのアドバイス: 場合によっては、単に「それについては話せません」と言ったほうがよい場合もあります。あなたの信頼性は重要であり、このようなリークや司法省裁判のような証言が出ると、今後のあなたの発言を信頼することは不可能になります。
注意事項
このリークからの私の調査結果と分析の信用を傷つけようとする人々がいることは誰もが知っていると思います。なぜそれが重要なのか疑問を抱き、「でも、私たちはすでにそれを知っていた」と言う人もいるでしょう。それでは、本題に入る前に、注意事項を整理しましょう。
時間と内容が限られている –週末が休みだったので、これらすべてに集中して費やすことができたのは 12 時間程度だけです。私が迅速に状況を把握できるよう、洞察を共有してくれた匿名の関係者に非常に感謝しています。また、昨年取り上げた Yandex のリークと同様に、私には全体像がありません。 Yandex の場合、解析するソース コードはありましたが、その背後にある考え方はありませんでしたが、この場合、何千もの機能とモジュールの背後にある考え方はありましたが、ソース コードはありませんでした。数週間にわたってこの資料にじっくり取り組んだ後よりも、あまり構造化されていない方法でこれを共有することをご容赦ください。
スコアリング関数がない –ダウンストリームのさまざまなスコアリング関数で特徴がどのように重み付けされるかはわかりません。利用可能なすべてが使用されているかどうかはわかりません。一部の機能が廃止されることはわかっています。明示的に示されない限り、ものがどのように使用されているかはわかりません。パイプラインのどこで何が起こるかはわかりません。私たちは、Google がそれを説明した方法、SEO が実際のランキングをどのように観察したか、特許出願や IR 文献がどのように説明したかに大まかに一致する一連の名前付きランキング システムを持っています。最終的に、このリークのおかげで、今後の SEO において何を重視し、何を無視するかを知ることができる、検討中の内容をより明確に把握できるようになりました。
おそらくいくつかの投稿のうちの最初のもの –この投稿は、私がレビューした内容の最初の投稿になります。詳細をさらに掘り下げていきながら、今後の投稿を公開する可能性があります。この記事をきっかけに、SEO コミュニティがこれらのドキュメントを解析するために競い合うことになり、私たちは今後数か月間、集合的に物事を発見し、再文脈化することになると思います。
これは最新の情報のようです –私の知る限り、このリークは、2024 年 3 月時点の Google 検索コンテンツ ストレージの現在アクティブなアーキテクチャを表しています。(Google の広報担当者が私が間違っていると言ったのを手がかりに。実際には、この曲は飛ばしましょう。そして踊ってください、皆さん)。コミット履歴に基づくと、関連コードは 2024 年 3 月 27 日にプッシュされ、2024 年 5 月 7 日まで削除されませんでした。

相関関係は因果関係ではありません– わかりました、これはここでは実際には当てはまりませんが、すべての基礎をカバーしていることを確認したかっただけです。
ドキュメントには 14K のランキング機能などが含まれています
API ドキュメントには、次のような 14,014 の属性 (機能) を持つ 2,596 のモジュールが示されています。

これらのモジュールは、YouTube、アシスタント、書籍、ビデオ検索、リンク、Web ドキュメント、クロール インフラストラクチャ、内部カレンダー システム、および People API のコンポーネントに関連しています。 Yandex と同様に、Google のシステムはモノリシック リポジトリ (または「モノリポ」) 上で動作し、マシンは共有環境で動作します。これは、すべてのコードが 1 か所に保存され、ネットワーク上のあらゆるマシンが Google のシステムの一部になることができることを意味します。

流出したドキュメントでは、API の各モジュールの概要が説明されており、概要、タイプ、関数、属性に分類されています。私たちが注目しているもののほとんどは、SERP (検索エンジン結果ページ - 検索者がクエリを実行した後に Google が表示するもの) を生成するためにランキング システム全体でアクセスされるさまざまなプロトコル バッファー(または protobuf) のプロパティ定義です。

残念なことに、概要の多くは、システムのさまざまな側面についての追加の詳細を提供する、Google の企業イントラネット上の URL である Go リンクを参照しています。これらのページにログインして表示するための適切な Google 認証情報がなければ (検索チームの現役 Google 社員であることがほぼ確実に必要になります)、私たちは自分のデバイスで解釈するしかありません。
APIドキュメントはいくつかの注目すべきGOOGLEの嘘を明らかにします
Google の広報担当者は、SEO としての私たちの行動を制御するために、Google のシステムの動作に関するさまざまな側面について、私たちを誤った方向に導き、誤解を招くよう全力を尽くしてきました。この用語には長い歴史があるため、私はそれを「ソーシャル エンジニアリング」とまでは言いません。代わりに…「ガスライティング」を考えましょう。 Google の公式声明はおそらく、意図的に嘘をつくためのものではなく、潜在的なスパマー (そして多くの正当な SEO も) を騙して、検索結果に影響を与える方法について私たちから知られないようにするためのものであると考えられます。
以下では、Google 従業員の主張とドキュメントの事実を、限定的なコメントを付けて紹介しますので、ご自身で判断してください。
「私たちにはドメイン権限のようなものはありません」
Googleの広報担当者は、「ドメイン権限」は使用していないと何度も述べている。私はこれが省略と難読化による嘘だとずっと思っていました。
ドメイン権限を使用しないと言うことで、特に「ドメイン権限」と呼ばれる Moz の指標を使用しないと言っている可能性があります (当然です 🙄)。また、Web サイトに関連する特定の主題 (またはドメイン) についての権威や重要性を測定していないと言う可能性もあります。この意味論による混乱により、サイト全体の権限指標を計算するか使用するかという質問に直接答えることができなくなります。
Google 検索チームのアナリストで、Web サイト作成者を支援する情報の公開に注力している Gary Ilyes 氏は、この主張を何度も繰り返しています。

そしてゲイリーは一人ではありません。 「Google 検索関係を調整する検索擁護者」である John Mueller 氏は、このビデオの中で「ウェブサイトのオーソリティ スコアはありません」と宣言しました。
実際には、ドキュメントごとに保存される圧縮品質シグナルの一部として、Google が計算する「siteAuthority」と呼ばれる機能があります。

この尺度がどのように計算され、下流のスコアリング関数で使用されるのかは具体的にはわかりませんが、この尺度が存在し、Q* ランキング システムで使用されることが明確にわかりました。 Google が確かに全体的なドメイン権限を持っていることが判明しました。 「私たちはそれを持っていますが、私たちはそれを使っていません」または「あなたはそれが何を意味するのか理解していません」と主張するGoogle社員を手助けしてください、または…待ってください、私は「限定的なコメント」と言ったでしょう?次に進みます。
「ランキングにクリック数は使用しません」
これは永久に寝かせましょう。
最近、司法省反トラスト法裁判におけるパンドゥ・ナヤク氏の証言により、 Glue および NavBoost ランキング システムの存在が明らかになりました。 NavBoost は、クリック主導の手段を採用して、Web 検索のランキングを向上、降格、または強化するシステムです。 Nayak 氏は、Navboost は 2005 年頃から存在しており、これまでは 18 か月間のクリック データをローリングで使用していたと述べました。このシステムは最近、13 か月分のデータを使用するように更新され、Web 検索結果に焦点を当てていますが、Glue と呼ばれるシステムは他のユニバーサル検索結果に関連付けられています。しかし、そのことが明らかになる前から、クリック ログを使用して結果を変更する方法を具体的に示す いくつかの特許 (2007 年の時間ベースのランキング特許を含む) を取得していました。
また、情報検索においては、成功の尺度としてクリック数がベスト プラクティスであることもわかっています。 Google が機械学習主導のアルゴリズムに移行しており、ML ではパフォーマンスを向上させるために応答変数が必要であることはわかっています。この驚くべき証拠にもかかわらず、Google の広報担当者の誤った指示と、Google の公式声明を無批判に繰り返す記事の恥ずかしいことに検索マーケティング業界全体での共謀により、SEO コミュニティでは依然として混乱が続いています。
Gary Ilyes は、このクリック測定の問題に何度も取り組みました。ある例では、Google 検索エンジニアの Paul Haahr 氏が2016 年の SMX West でのライブ実験についての講演で語った内容を強調し、「ランキングにクリックを直接使用するのは間違いだ」と述べました。

さらにその後、彼が自分のプラットフォームを使ってランド・フィッシュキン(Mozの創設者兼CEO、長年のSEO実践者)を貶め、「滞留時間、CTR、フィッシュキンの新しい理論が何であれ、それらは概してでっち上げだ」と発言したのは有名だ。

実際には、Navboost にはクリック信号に完全に焦点を当てた特定のモジュールがあります。
このモジュールの概要では、ランキング システムの 1 つである「クラップスのクリックおよびインプレッション シグナル」として定義されています。以下に示すように、悪いクリック、良いクリック、最後の最長クリック、潰されていないクリック、および潰されていない最後の最長クリックはすべて指標として考慮されます。 Google の「位置の顕著性に基づいたローカル検索結果のスコアリング」特許によれば、「スカッシングは、1 つの大きな信号が他の信号を支配するのを防ぐ機能です。」言い換えれば、システムはクリック信号に基づいた暴走操作がないことを保証するためにクリックデータを正規化しています。 Google社員らは、特許やホワイトペーパーに記載されているシステムが実際に運用されているものであるとは限らないと主張しているが、NavBoostがGoogleの情報検索システムの重要な部分でなければ、NavBoostを構築して組み込むのは無意味だろう。

これらの同じクリックベースの測定の多くは、インデックス信号に関連する別のモジュールにもあります。尺度の 1 つは、特定のドキュメントに対する「最後のグッドクリック」の日付です。これは、コンテンツの衰退 (または時間の経過によるトラフィック損失) は、ランキング ページが SERP 順位で予想されるクリック数を増加させないことにも起因することを示唆しています。
さらに、ドキュメントではユーザーを投票者として表し、ユーザーのクリックが投票として保存されます。システムは不正なクリックの数をカウントし、データを国とデバイスごとに分類します。
また、セッション中にどの結果が最も長くクリックされたかも保存されます。したがって、検索を実行して結果をクリックするだけでは十分ではなく、ユーザーはページ上でかなりの時間を費やす必要もあります。ロングクリックは滞在時間と同様に検索セッションの成功の尺度ですが、このドキュメントでは「滞在時間」と呼ばれる特定の機能はありません。それにもかかわらず、ロングクリックは事実上同じことの尺度であり、この問題に関するGoogle の声明と矛盾しています。
さまざまな情報源は、NavBoost が「すでに Google の最も強力なランキング シグナルの 1 つ」であることを示しています。リークされた文書には、タイトルに Navboost をフィーチャーした 5 つのモジュールが含まれており、「Navboost」という名前が 84 回指定されています。また、彼らがサブドメイン、ルートドメイン、URL レベルでのスコアリングを検討しているという証拠もあり、これは本質的に、サイトの異なるレベルを異なる方法で扱うことを示しています。サブドメインとサブディレクトリの議論には立ち入りませんが、システムからのデータが Panda アルゴリズムにどのように情報を与えたかについては後ほど説明します。
つまり、Google はこのドキュメントで「CTR」や「滞在時間」について正確な言葉で言及していませんが、ランドが証明した精神、つまり検索結果のクリック数と成功した検索セッションの尺度は含まれています。証拠はかなり決定的であり、Google がランキング アルゴリズムの一部としてクリックとクリック後の動作を使用していることにほとんど疑いの余地はありません。
「サンドボックスはありません」
Googleの広報担当者は、年齢や信頼シグナルの欠如に基づいてWebサイトを分離するサンドボックスは存在しないと断固として主張している。現在は削除されているツイートの中で、ジョン・ミュラー氏は「サンドボックスはない」とランク付けの資格を得るまでにどれくらいの時間がかかるかという質問に答えた。

PerDocData モジュールでは、ドキュメントには hostAge と呼ばれる属性が示されており、これは特に「配信時に新しいスパムをサンドボックス化する」ために使用されます。
結局のところ、サンドボックスがあることがわかりました。誰かわかったね?そうそう、ランドは知っていました。
「ランキングには Chrome のものは一切使用していません」
マット・カッツ氏は以前、Googleはオーガニック検索の一部としてChromeデータを使用していないと述べたと伝えられている。最近では、ジョン・ミュラー氏がこの考えを強化しました。

ページ品質スコアに関連するモジュールの 1 つは、Chrome からのビューのサイトレベルの測定を特徴としています。サイトリンクの生成に関連していると思われる別のモジュールにも Chrome 関連の属性があります。

2016 年 5 月に流出した RealTime Boost システムに関する内部プレゼンテーションでも、Chrome データが検索に利用されるようになったことが示されています。つまり、要点はわかります。
Google の広報担当者は善意を持っていますが、信頼できるでしょうか?
簡単な答えは、秘伝のソースに近づきすぎた場合ではありません。
私はここで引用した人々に対して悪意を持っていません。彼らは皆、許される範囲内でコミュニティにサポートと価値を提供するために最善を尽くしていると思います。しかし、これらの文書は、私たちが文書の内容を 1 つのインプットとして受け入れ続ける必要があり、私たちのコミュニティが何が機能するかを確認するために実験を続けるべきであることを明確にしています。
GOOGLE のランキング システムのアーキテクチャ
概念的には、「Google アルゴリズム」は、一連の重み付けされたランキング要素を含む巨大な方程式である 1 つのものとして考えることができます。実際には、これは一連のマイクロサービスであり、SERP を構成するために多くの機能が前処理され、実行時に利用できるようになります。ドキュメントで参照されているさまざまなシステムに基づいて、100 を超える異なるランキング システムが存在する可能性があります。これらがすべてのシステムではないと仮定すると、おそらくそれぞれの個別のシステムが「ランキング シグナル」を表しており、おそらくそれが Google がよく話題にする 200 のランキング シグナルを導き出す方法なのかもしれません。
Jeff Dean の「Google でのソフトウェア システムの構築と得られた教訓」の講演の中で、Google の初期のイテレーションでは各クエリが 1000 台のマシンに送信され、250 ミリ秒未満で処理および応答されたと述べました。彼はまた、システム アーキテクチャの抽象化の初期バージョンを図式化しました。この図は、スーパー ルートがクエリを送信し、最後にすべてをつなぎ合わせる Google 検索の頭脳であることを示しています。

Distinguished Research エンジニアの Marc Najork 氏は、最近のGenerative Information Retrieval プレゼンテーションで、RAG システム (別名 Search Generative Experience/AI Oververs) を使用した Google 検索の抽象化モデルを紹介しました。この図は、結果のさまざまなレイヤーを処理する一連の異なるデータ ストアとサーバーを示しています。

Google の内部告発者である Zach Vorhies が、Google 内のさまざまなシステムの関係を内部名で示したこのスライドをリークしました。これらのいくつかはドキュメントで参照されています。

これら 3 つの高レベル モデルを使用すると、これらのコンポーネントのいくつかがどのように連携して機能するかを考え始めることができます。ドキュメントから収集した情報によると、この API はGoogle の Spannerの上に存在しているようです。 Spanner は、基本的に、グローバルにネットワーク化された一連のコンピューターを 1 つとして扱いながら、コンテンツ ストレージとコンピューティングの無限のスケーラビリティを可能にするアーキテクチャです。
確かに、ドキュメントだけからすべての関係をつなぎ合わせるのは多少難しいですが、Paul Haahr の履歴書は、名前付きランキング システムの一部についての貴重な洞察を提供します。私が名前で知っているものを強調表示し、それらを機能に分割します。
クローリング
トローラー – Web クローリング システム。クロールキューを備え、クロール レートを維持し、ページが変更される頻度を把握します。
インデックス作成
Alexandria –コアインデックスシステム。
SegIndexe r –階層ドキュメントをインデックス内の階層に配置するシステム。
TeraGoogle –ディスク上に長期間保存されるドキュメント用のセカンダリ インデックス システム。
レンダリング
HtmlrenderWebkitHeadless – JavaScript ページのレンダリング システム。奇妙なことに、これは Chromium ではなく Webkit にちなんで名付けられています。ドキュメントには Chromium についての言及があるため、Google は当初 WebKit を使用していて、Headless Chrome の登場後に切り替えを行った可能性があります。
処理
LinkExtractor –ページからリンクを抽出します。
WebMirror –正規化と複製を管理するシステム。
ランキング
Mustang –主要なスコアリング、ランキング、およびサービング システム
Ascorer – 再ランキング調整の前にページをランク付けする主要なランキング アルゴリズム。
NavBoost –ユーザーの行動のクリックログに基づいて再ランキングするシステム。
FreshnessTwiddler –鮮度に基づいてドキュメントを再ランク付けするシステム。
WebChooserScorer –スニペット スコアリングで使用される機能名を定義します。
給仕Google Web サーバー – GWS は、Google のフロントエンドが通信するサーバーです。ユーザーに表示するデータのペイロードを受け取ります。
SuperRoot –これは Google 検索の頭脳であり、Google のサーバーにメッセージを送信し、再ランキングと結果の表示のための後処理システムを管理します。
SnippetBrain –結果のスニペットを生成するシステム。
Glue –ユーザーの行動を使用して普遍的な結果をまとめるシステム。
クックブック –シグナルを生成するシステム。実行時に値が作成されることが示されています。
先ほども述べたように、これらのドキュメントには他にも多くのシステムが概説されていますが、それらが何をするのかは完全には明らかではありません。たとえば、上の図の SAFT と Drishti もこれらの文書に示されていますが、その機能は不明です。
トゥイドラーズとは何ですか?
一般に Twiddlers に関するオンライン情報は限られているため、ドキュメントで登場するさまざまなブースト システムをより適切に説明できるように、ここで説明する価値があると思います。
Twiddler は、主要な Ascorer 検索アルゴリズムの後に実行される再ランキング関数です。これらは、表示内容がユーザーに表示される直前に調整される WordPress でのフィルターとアクションの動作と同様に機能します。 Twiddler は、ドキュメントの情報検索スコアを調整したり、ドキュメントのランキングを変更したりできます。私たちが知っている多くのライブ実験や名前付きシステムはこの方法で実装されています。この Xoogler が示しているように、これらはさまざまな Google システムにわたって非常に重要です。

Twiddler はカテゴリの制約を提供できます。つまり、結果の種類を具体的に制限することで多様性を促進できます。たとえば、作成者は、特定の SERP で 3 つのブログ投稿のみを許可することを決定する場合があります。これにより、ページの形式に基づいて、ランキングが失われた原因となる場合を明確にすることができます。
Google が Panda のようなものはコア アルゴリズムの一部ではなかったと言う場合、これはおそらく、Panda が再ランキングのブーストまたは降格の計算として Twiddler として起動され、その後主要なスコアリング関数に移行されたことを意味します。これは、サーバー側とクライアント側のレンダリングの違いに似ていると考えてください。
おそらく、Boost サフィックスが付いた関数はいずれも Twiddler フレームワークを使用して動作します。ドキュメントで特定されているブーストの一部を次に示します。
ナビブースト
クオリティブースト
リアルタイムブースト
WebImageBoost
命名規則を見ると、それらはすべて一目瞭然です。
私がレビューした Twiddlers に関する内部文書にもこれについて詳しく記載されていますが、この投稿では 、著者が私と同じ文書を見たようです。
SEO のやり方に影響を与える可能性のある重要な事実
本当に何のために来たのかを見てみましょう。私たちが知らなかった、または確信が持てなかった Google の取り組みは何でしょうか? それが私の SEO の取り組みにどのような影響を与える可能性がありますか?
次に進む前に簡単にメモしておきます。 SEO 業界に新しいコンセプトを知ってもらうことが常に私の目標です。あなたの特定のユースケースにそれを使用する方法についての処方箋を提供することが私の目的ではありません。それが望むのであれば、SEO のために iPullRank を雇うべきです。それ以外の場合は、そこから推測して独自のユース ケースを開発するのに十分以上のものが常にあります。
パンダの仕組み
パンダ(Panda)が登場したとき、多くの混乱がありました。機械学習ですか?ユーザー信号を使用しますか?回復するためにアップデートやリフレッシュが必要なのはなぜですか?サイト全体ですか?特定のサブディレクトリのトラフィックが失われたのはなぜですか?
パンダはアミット・シンハルの指導の下で解放された。シンハル氏は、機械学習の可観測性が限られているため、機械学習に断固として反対していた。実はパンダにはサイト品質に焦点を当てた特許が相次いでいるが、私が注目したいのは地味な 「検索結果のランキング」だ。この特許は、パンダ が私たちが考えていたよりもはるかに単純であることを明らかにしています。これは主に、ユーザーの行動と外部リンクに関連する分散シグナルに基づいてスコアリング修飾子を構築することでした。この修飾子は、ドメイン レベル、サブドメイン、またはサブディレクトリ レベルで適用できます。
「システムは、独立したリンクの数と参照クエリの数からリソースのグループに対する修正係数を生成する(ステップ306)。例えば、修正係数は、グループの参照クエリの数に対するグループの独立リンクの数の比率とすることができる。つまり、修正係数 (M) は次のように表すことができます。
M=IL/RQ、
ここで、IL はリソースのグループに対してカウントされた独立リンクの数、RQ はリソースのグループに対してカウントされた参照クエリの数です。
独立リンクは基本的にルート ドメインのリンクと考えられますが、参照クエリはもう少し複雑です。特許では次のように定義されています。
「特定のリソース グループに対する参照クエリは、特定のリソース グループ内のリソースを参照するものとして分類された、以前に送信された検索クエリである可能性があります。以前に送信された特定の検索クエリを、リソースの特定のグループ内のリソースを参照するものとして分類することは、以前に送信された特定の検索クエリが、リソースの特定のグループ内のリソースを参照すると決定された1つまたは複数の用語を含むことを判定することを含むことができる。 」
このドキュメントにアクセスできるようになったので、参照クエリが NavBoost からのクエリであることは明らかです。

これは、パンダ の更新が、Core Web Vitals の計算の機能と同様に、クエリのローリング ウィンドウに対する単純な更新であったことを示唆しています。また、リンク グラフの更新が パンダ に対してリアルタイムで処理されなかったことも意味する可能性があります。
馬に勝つわけではありませんが、パンダ の別の特許であるサイト品質スコアでも、参照クエリとユーザーの選択またはクリックの間の比率であるスコアが考慮されています。
ここでの重要な点は、ランクを維持し続けるには、より幅広いクエリを使用してクリック数を増やし、より多くのリンクの多様性を獲得する必要があるということです。概念的には、非常に強力なコンテンツがそれを実現するため、これは理にかなっています。より良いユーザー エクスペリエンスを目指して、より質の高いトラフィックを誘導することに重点を置くと、あなたのページがランク付けに値するというシグナルが Google に送信されます。役立つコンテンツの更新から回復するには、同じことに重点を置く必要があります。
著者は明示的な特徴です
EEAT については多くのことが書かれています。 SEO の多くは、専門知識や権威を評価することが非常に曖昧であるため、信念を持っていません。また、私は以前、ウェブ上で実際に著者マークアップがいかに少ないかを強調しました。ベクトル埋め込みについて学ぶ前、私は、著者であることが Web スケールで十分に有効なシグナルであるとは信じていませんでした。

それにもかかわらず、Google はドキュメントに関連付けられた作成者をテキストとして明示的に保存します。

また、ページ上のエンティティがページの作成者でもあるかどうかも判断します。

これを、これらの文書で紹介されているエンティティと埋め込みの詳細なマッピングと組み合わせると、作成者に関する包括的な測定が存在することは明らかです。
降格
一連のアルゴリズムによる降格についてはドキュメントで説明されています。説明は限られていますが、言及する価値はあります。 Panda についてはすでに説明しましたが、私が遭遇した残りの降格は次のとおりです。
アンカーの不一致 –リンクがリンク先のターゲット サイトと一致しない場合、リンクは計算上降格されます。以前にも述べたように、Google はリンクの両側で関連性を探しています。
SERP 降格 – SERP から観察された要因に基づいて降格を示すシグナル。クリックによって測定される可能性が高い、ページに対するユーザーの潜在的な不満を示唆します。
ナビゲーションの降格 – おそらく、これは不適切なナビゲーションの実践やユーザー エクスペリエンスの問題を示すページに適用される降格です。
完全一致ドメインの降格 – 2012 年後半、マット カッツ氏は、完全一致ドメインはこれまでほどの価値は得られないと発表しました。彼らの降格には特有の特徴があります。
製品レビューの降格 –これに関する具体的な情報はありませんが、降格としてリストされており、おそらく2023 年の最近の製品レビューの更新に関連しています。
場所の降格 - 「グローバル」ページと「スーパーグローバル」ページが降格される可能性があるという兆候があります。これは、Google がページを場所に関連付け、それに応じてランク付けしようとしていることを示唆しています。
ポルノの降格 –これは非常に明白です。
その他のリンクの降格 –次のセクションで説明します。
これらすべての潜在的な降格は戦略に影響を与える可能性がありますが、正直に言うと、結局のところ、強力なユーザー エクスペリエンスを備えた優れたコンテンツを作成し、ブランドを構築することになります。
リンクは依然としてかなり重要であるようです
リンクはそれほど重要ではないと考えられているという最近の主張に反論する証拠を私は見たことがありません。繰り返しますが、これは情報の保存方法ではなく、スコアリング関数自体で処理される可能性があります。とはいえ、リンク グラフを深く理解するために、機能の抽出と設計には細心の注意が払われました。
インデックス層はリンク値に影響を与える
ページがインデックス付けされている場所とそのページの価値との間の緩やかな関係を示す、sourceType と呼ばれるメトリクス。背景を簡単に説明すると、Google のインデックスは階層化されており、最も重要で定期的に更新され、アクセスされるコンテンツがフラッシュ メモリに保存されます。重要度の低いコンテンツはソリッド ステート ドライブに保存され、不定期に更新されるコンテンツは標準のハード ドライブに保存されます。

これは事実上、階層が高くなるほどリンクの価値が高くなることを意味します。 「新鮮」とみなされるページも高品質とみなされます。リンクを新しいページ、または上位層に掲載されているページから取得したいと言うだけで十分です。これは、ランキングの高いページやニュース ページからランキングを取得すると、ランキングのパフォーマンスが向上する理由の一部を説明します。見てください、デジタル PR をまたクールにしました!
リンクスパム速度シグナル
スパムアンカーテキストのスパイクの特定に関する一連の指標があります。フレーズAnchorSpamDays機能に注目すると、Googleはスパムのリンク速度を効果的に測定する機能を備えています。

これは、サイトがスパム送信していることを特定し、ネガティブな SEO 攻撃を無効にするために簡単に使用できます。後者について懐疑的な人のために、Google はこのデータを使用してリンク検出のベースラインを現在の傾向と比較し、単にどちらの方向のリンクもカウントしないようにすることができます。
Google はリンクを分析するときに、指定された URL の最後の 20 件の変更のみを使用します。
以前、Google のファイル システムが、ウェイバック マシンと同様に、ページのバージョンを長期にわたって保存できる仕組みについて説明しました。これについての私の理解は、Google はインデックスに登録したものを永久に保持しているということです。これが、単にページを無関係なターゲットにリダイレクトし、リンク エクイティのフローを期待できない理由の 1 つです。

ドキュメントはこの考えを補強し、ページに対してこれまでに行われたすべての変更を保持することを暗示しています。

DocInfo を取得して比較のためにデータを表示する場合、ページの最新 20 バージョンのみが考慮されます。

これにより、Google で「白紙の状態」にするために、ページを何回変更してインデックスに登録する必要があるかがわかります。
ホームページの PageRank はすべてのページに対して考慮されます
すべてのドキュメントには、ホームページの PageRank (最も近いシードのバージョン) が関連付けられています。これは、新しいページが独自の PageRank を取得するまで、そのページのプロキシとして使用される可能性があります。

おそらく、独自の PageRank が計算されるまで、これと siteAuthority が新しいページのプロキシとして使用されます。
ホームページトラスト
Google は、ホームページをどの程度信頼しているかに基づいて、リンクの評価方法を決定します。

いつものように、リンクの量ではなく、リンクの品質と関連性に重点を置く必要があります。
用語とリンクのフォント サイズが重要
私が 2006 年に初めて SEO を始めたとき、私たちが行ったことの 1 つは、テキストを太字にして下線を引いたり、特定の文章をより重要に見せるために大きくしたりすることでした。過去5年間、私は人々がそれはまだやる価値があると言っているのを見てきました。私は懐疑的でしたが、Google が文書内の用語の平均重み付けフォント サイズを追跡していることがわかりました。

リンクのアンカーテキストに対しても同じことを行っています。

ペンギンが内部リンクを削除
アンカー関連モジュールの多くでは、「ローカル」という概念は同じサイトを意味します。この DropLocalAnchorCount は、一部の内部リンクがカウントされていないことを示しています。
否認に関する言及は 1 つもありませんでした
否認データは他の場所に保存することもできますが、特にこの API には保存されません。特に、ここでは品質評価者のデータに直接アクセスできるためです。これは、否認データがコアのランキング システムから切り離されていることを示唆しています。

私の長年の思い込みは、否認は Google のスパム分類器をトレーニングするためのクラウドソーシングによる特徴エンジニアリングの取り組みであるというものでした。データが「オンライン」ではないということは、これが真実である可能性を示唆しています。
リンクをたどり続けて、IndyRank や PageRankNS などの機能について話すこともできますが、Google はリンク分析を非常に熱心に行っており、彼らが行っていることの多くは私たちのリンク インデックスでは近似されていないと言うだけで十分です。今読んだ内容に基づいて、リンク構築プログラムを再検討する非常に良い時期です。
ドキュメントが切り詰められる
Google は、トークンの数と、本文内の単語の合計と一意のトークンの数の比率をカウントします。ドキュメントでは、特に Mustang システムではドキュメントに対して考慮できるトークンの最大数があることが示されており、作成者は最も重要なコンテンツを早期に配置し続ける必要があることが強調されています。

短いコンテンツはオリジナリティで採点されます
OriginalContentScore は、短いコンテンツがその独創性によってスコアリングされることを示唆しています。おそらくこれが、薄いコンテンツが必ずしも長さの関数ではない理由です。
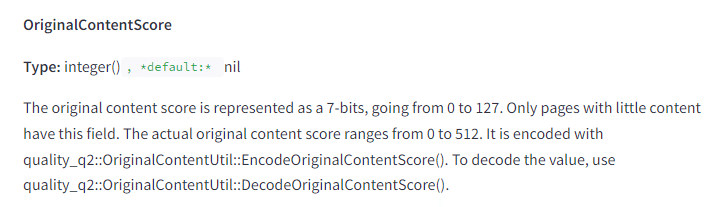
逆に、キーワード詰め込みスコアもあります。
ページタイトルは引き続きクエリに対して測定されます
ドキュメントには、titlematchScore があることが示されています。この説明は、ページ タイトルがクエリにどれだけ一致するかが、依然として Google が積極的に重視していることを示唆しています。

ターゲットキーワードを最初に配置することは依然として重要です。
文字数カウントの手段はありません
名誉のために言っておきますが、Gary Ilyes 氏は、メタデータの最適な文字数全体を SEO が占めていると述べています。このデータセットには、ページ タイトルやスニペットの長さをカウントするメトリクスはありません。ドキュメントで私が見つけた唯一の文字カウント基準は、スニペットの一部として使用できるものを決定するために設定されているように見える、snippetPrefixCharCount です。

これは、私たちが何度もテストしてきたことを裏付けるもので、長いページ タイトルはクリック数を増やすには最適ではありませんが、ランキングを高めるには問題ありません。
日付は非常に重要です
Google は最新の結果に非常に重点を置いており、文書は日付とページを関連付けようとする同社の数多くの試みを示しています。
bylineDate –これはページ上で明示的に設定された日付です。

syntacticDate – URL またはタイトルから抽出された日付です。

semanticDate –これはページのコンテンツから派生した日付です。

ここで最善の方法は、日付を指定し、構造化データ、ページ タイトル、XML サイトマップ全体で日付と一致させることです。ページ上の他の場所の日付と競合する日付を URL に含めると、コンテンツのパフォーマンスが低下する可能性があります。
ページに関するドメイン登録情報が保存されます
Google のレジストラとしての地位がアルゴリズムに影響を与えているというのは長年の陰謀論だった。陰謀の事実に格上げできる。最新の登録情報が複合ドキュメント レベルで保存されます。

前述したように、これは新しいコンテンツのサンドボックス化を通知するために使用される可能性があります。また、所有権が変更された以前に登録されたドメインをサンドボックス化するために使用することもできます。最近、期限切れのドメイン悪用スパム ポリシーの導入により、この問題の重要性が高まっているのではないかと思います。
ビデオ中心のサイトは異なる扱いを受ける
サイト上のページの 50% 以上にビデオが含まれている場合、そのサイトはビデオに重点を置いているとみなされ、別の方法で扱われます。

あなたのお金、あなたの人生は特別に採点されます
ドキュメントには、Google が YMYLHealth と YMYL News のスコアを生成する分類器があることが示されています。

また、「フリンジ クエリ」やこれまでに見られなかったクエリを予測して、それが YMYL かどうかを判断します。

最後に、YMYL はチャンク レベルでコア化されており、システム全体が埋め込みに基づいていることを示唆しています。

ゴールドスタンダード文書がある
これが何を意味するのかは示されていませんが、説明には「人間がラベルを付けたドキュメント」と「自動的にラベルが付けられた注釈」について言及されています。これが品質評価の機能なのかどうか疑問に思いますが、Google は品質評価はランキングに影響を与えないと述べています。したがって、私たちは決して知ることができないかもしれません。 🤔

サイトの埋め込みは、ページがトピックにどれだけ合っているかを測定するために使用されます
埋め込みについては次の投稿で詳しく説明しますが、Google が特にページとサイトをベクトル化し、ページの埋め込みをサイトの埋め込みと比較して、ページがどれほど主題から外れているかを確認していることは注目に値します。

siteFocusScore は、サイトが 1 つのトピックにどれだけこだわっているかをキャプチャします。サイト半径は、サイトに対して生成された site2vec ベクトルに基づいて、ページがコア トピックからどの程度外側に出ているかをキャプチャします。
Googleは小規模サイトを意図的に焼き付けている可能性がある
Google には、サイトが「小規模な個人サイト」であることを示す特定のフラグがあります。このようなサイトの定義はありませんが、私たちが知っていることすべてに基づくと、そのようなサイトを強化する Twiddler や、それらのサイトを降格させる Twiddler を追加することは難しくありません。

Helpful Content Update によって打撃を受けた反発と中小企業を考えると、彼らがこの機能を使って何かをするというのは不思議なことです。
私の未解決の質問
このまま続けることもできますし、そうするつもりですが、休憩の時間です。それまでの間、他の人たちがこのリークに夢中になり、独自の結論を導き出すことは避けられないと思います。現時点では、皆さんにぜひ検討していただきたい未解決の質問がいくつかあります。
役立つコンテンツのアップデートはベビーパンダとして知られていますか?
圧縮品質信号には、「赤ちゃんパンダ」と呼ばれるものへの言及が 2 つあります。 Baby Panda は、初期ランク付け後にボルトオンで調整される Twiddler です。

Panda 上で動作するという記述がありますが、ドキュメントにはその他の情報はありません。

Helpful Content Update には Panda と同じ動作が多くあるという点では、私たちは概ね同意していると思います。参照クエリ、リンク、クリックを使用するシステム上に構築されている場合は、コンテンツを改善した後にこれらに重点を置く必要があります。
NSR とはニューラル セマンティック検索のことですか?
命名規則の一部として NSR を使用したモジュールと属性への参照が大量にあります。これらの多くは、サイト チャンクと埋め込みに関連しています。 Googleは以前、改善の大きな焦点として「ニューラルマッチング」について議論した。私の推測では、NSR は Neural Semantic Retrieval の略で、これらはすべてセマンティック検索に関連する機能であると考えられます。ただし、場合によっては、「サイトランク」の隣に記載されている場合もあります。
反抗的な Google 社員がgo/NSRに行って、匿名のメール アドレスか何かで私に「あなたの言うとおりです」と送ってくれたら 嬉しいです。
実用的なもの
先ほども言いましたが、私にはあなたに処方箋はありません。ただし、戦略的なアドバイスはいくつかあります。
Rand Fishkin に謝罪を送る – PubCon での「Google が私たちに嘘をついたすべて」の基調講演以来、私は NavBoost に関連する Rand の汚名を晴らすキャンペーンに参加してきました。ランドは何年にもわたって、私たちの業界の向上に貢献するために感謝の余地のない仕事をしてくれました。彼は、Google 側と SEO 側から多くの非難を浴びました。時々彼は物事がうまくいかないこともありましたが、彼の心は常に正しい位置にあり、私たちが行っていることを尊重し、より良いものにするために強い努力を払ってくれました。具体的には、クリック実験の結論、Google サンドボックスの存在を示そうとした繰り返しの試み、Google がサブドメインのランク付けを異なる方法で行っていることを示すケーススタディ、そして Google がサイト全体で権威あるスタイルのシグナルを採用しているという長年軽視されてきた信念について、彼は間違っていませんでした。 。また、私にドキュメントを共有してくれたのは彼なので、この分析に関しても彼に感謝する必要があります。今こそ、多くの人にとって、スレッド上で彼への愛を示す良い時期です。
素晴らしいコンテンツを作成し、それを宣伝しましょう –冗談ですが、本気でもあります。 Google はそのアドバイスを提供し続けていますが、私たちはそれが実行不可能であるとして躊躇しています。一部の SEO にとって、それは自分たちの制御を超えています。Google に利点をもたらすこれらの機能を検討した結果、より良いコンテンツを作成し、共感を呼ぶ視聴者にそれを宣伝することが、これらの施策に最大の効果をもたらすことは明らかです。リンクとコンテンツの機能を測定すれば、確かにかなりの成果を上げることができますが、本当に Google で長期的に勝ちたいのであれば、ランキングに値するものを作り続ける必要があります。
相関関係研究の復活 – Google がランキングを構築するために使用している機能の多くについて、より深く理解できるようになりました。クリックストリーム データと特徴抽出を組み合わせることで、以前よりも多くの複製が可能になります。分野別の相関研究を復活させる時期が来たと思います。
テストして学ぶ – SEO に関して読んだり聞いたりするものはすべて信頼できないことがわかるように、可視性と Y 軸のトラフィック グラフを十分に見たはずです。このリークは、Web サイトに何が機能するかを確認するために、入力情報を取り入れて実験する必要があることを示すもう 1 つの兆候です。物事に関する逸話的なレビューを見て、それが Google の仕組みだと思い込むだけでは十分ではありません。組織に SEO の実験計画がない場合は、今が実験計画を始める良い機会です。
私たちは自分たちが何をしているのか知っています
このことから私たち全員が得られる重要なことは、SEO は自分たちが何をしているのかを知っているということです。何年も私たちが間違っていると言われてきた後、カーテンの後ろを見て、私たちがずっと正しかったことがわかるのは良いことです。そして、これらの文書には Google の仕組みについて興味深い微妙なニュアンスが含まれていますが、SEO の戦略的なやり方に劇的な変化をもたらすものは何もありません。
深く掘り下げる人にとって、これらの文書は主に、経験豊富な SEO が長年主張してきたことを検証するのに役立ちます。視聴者を理解し、彼らが何を望んでいるのかを特定し、それに合わせて可能な限り最高のものを作成し、技術的にアクセスしやすいものにして、ランクが上がるまで宣伝します。
自分が何をしているのかよくわかっていない SEO の皆さん、テストを続け、学習を続け、ビジネスを成長させ続けてください。 Google は私たちなしでは彼らが行っていることを行うことはできません。
ランキング機能をダウンロードする
そうですね、誰かがすべての機能をダウンロードしてスプレッドシートに整理してくれるでしょう。それは私でもいいかもしれません。この四半期はあと 1 か月しか残っていないので、とにかく MQL を上げたいと思っています。 😆
ランキング機能リストのコピーを入手してください。
まだ始まったばかりです
私が SEO についていつも気に入っているのは、SEO が常に進化するパズルであるということです。私たちの努力でブランドが数十億ドルを稼ぐのを支援するのは楽しいことですが、Google の仕組みを解明することに関連するすべての調査で私の好奇心を満たすことには、非常に満足できるものがあります。ついにカーテンの後ろを見ることができて、とてもうれしかったです。
今のところ私が知っているのはこれだけですが、何か見つけたらぜひ教えてください。私と何かを共有したい人は誰でも連絡してください。結構見つけやすいんです!
次のステップ
iPullRank が SEO とコンテンツを組み合わせてビジネスの認知度を高め、収益を促進するのに役立つ 3 つの方法を次に示します。30 分間の戦略セッションをスケジュールする: SEO とコンテンツの最大の課題を共有してください。これにより、デジタル プレゼンスを調査した後、カスタムの調査デッキをまとめることができます。すべてに当てはまる万能のソリューションはなく、ビジネスを成長させるための個別のアドバイスのみが必要です。今すぐセッションをスケジュールしてください。
AI 概要の潜在的な影響を軽減する: Google の AI 概要に対する SEO 戦略はどの程度準備されていますか?包括的な AI 概要脅威レポートを使用して、潜在的な脅威に先手を打ち、サイトの競争力を維持します。レポートを入手してください。
Orbitwise でコンテンツの関連性を強化:コンテンツが数学的に関連しているかどうかわかりませんか? Orbitwise を使用してコンテンツの関連性をテストおよび改善し、対象のキーワードに対してコンテンツがランク付けされるようにします。今すぐコンテンツをテストしてください。
もっと欲しい?過去のウェビナー、限定ガイド、専門家チームが作成した洞察力に富んだブログにアクセスするには、リソース ページにアクセスしてください。ビジネスを時代の先を行くために必要なものはすべてすぐに手に入ります。
iPullRank で次のステップに進みます。

マイク・キングは、iPullRank の創設者兼 CEO です。深い技術力と非常に創造的なマイクは、クライアントに 20 億ドルを超える収益を生み出すことに貢献してきました。ラッパーであり、立ち直りつつある大手エージェンシーの男であるマイクの最大の顧客は、二人の娘、ゾーラとグローリーだ。
この記事が気に入ったらサポートをしてみませんか?