読書会で使っているリストをPythonで自動化した話

こんにちは!
今回は毎月開催している「レバレッジ・リーディング読書会」というオンライン読書会で使っている「参加者の読んだ本リスト」を自動化したことについて書きたいと思います。人に見せるほどのコードではないですし、需要があるとも思えませんが、一応コードも公開しているので興味のある方はご参照下さい。
ちなみに、読書会がどんな感じなのかは、過去のレポートやHPをご覧ください。
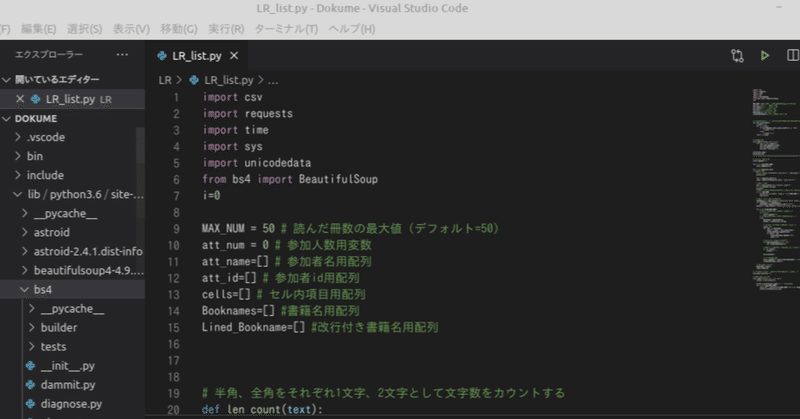
ソースコード
細かいことを四の五の言う前に、とりあえずソースコードを置いておきます。自己責任において、使いたい人はご自由に使っていただいて構いません。需要があるとは思えませんが、これを参考にしてなにかをやる際には出典元を明記いただけると嬉しいです(別に必須ではないです)。
一応書いておきますが、このコードは記事作成時点での読書メーターのWebサイトの構造をベースにしているので、読書メーター側の仕様が変われば使えなくなることも全然ありえます(そもそも、利用規約上ウェブスクレイプ自体が禁止される可能性もあります)。配布元はそういった責任の一切を負いかねます。もし使うのであれば、そのあたりご理解のうえご利用ください。
> 後日追記
既に色々と改変しているので、最新版はリポジトリの最新コミットをご参照下さい。
開発のモチベーション
HPやレポートを読んだ方ならわかるとおり、このオンライン読書会では事前に参加者が前の月に読んだ本をリストアップしておき、それを見ながら会話するという形で行っています。みんなで同じリストを見ながら話していると会話のきっかけにもなりますし、気になる本のことなど気軽に質問できるので割と良いツールになっているのかなと思っています。単純に、たくさんの本をリスト化すると、それを眺めているだけでも楽しいというのもありますけどねw
とまあ結構重宝しているリストではありますが、問題は正直言って作るのがややめんどくさいということです。毎月僕が参加者の読書メーターのページにアクセスして手動でリストを作っていたわけですが、これが地味にめんどくさい。もちろん、それだけの価値はある作業だとは思っていますが、やはりちょっと大変な感は否めません。
特に最近は(大変ありがたいことに)参加希望者も多く、コンスタントに定員の5人が埋まっている状態なので、リストを作るのにかかる手間も増えてきました。また、キャンセル待ちの方も出てきており、月に2回開催なども本格的に考えていこうと思っているので、このリスト作りの手間を減らすのは必須かなと。そんなわけで、このリスト作りを自動化したというわけです。
開発環境
OS: Linux mint 19.3 64bit
使用言語: Python 3.6.9
統合開発環境: VS code
使用外部ライブラリ: Beautifulsoup4、Requests
タイトルの通り、今回使ったのはPythonというプログラミング言語です。オープンソースのプログラミング言語で、比較的見やすいコーディングが出来ることを意識している言語ようです。AI(機械学習)や統計処理、ウェブクロール(インターネットからの自動情報収集)関係のライブラリが充実しているらしく、ここのところ結構話題になっている言語の一つですね。
Pythonを使った理由を正直に言うと、一度Pythonで何かを作ってみたかったというのが一番大きいですw ただ、読書メーターと言うウェブサイトからの情報収集を自動化するのが目的なので、ウェブクロールに強いPythonを使ったという側面もあります(正確にいうと、今回やっているのはウェブクロールではなく、ウェブスクレイプという方が正しいです)。
今回利用した外部ライブラリはRequestsとBeautifulsoup4。Requestsは指定されたURLからhtmlコードを取得するライブラリで、Beautifulsoupはhtmlを解析して必要な情報を取り出すためのライブラリです。要するに、Requestで参加者の読書メーターのページのhtmlを取得して、Beatifulsoupでその中から本の名前と著者名を引っ張ってくると言う感じです。
英語版ではありますが、各ライブラリの公式サイトはこちら。これらのライブラリは非常によく使われるようなので、公式にこだわらなければ日本語で使い方を解説している文献・サイトは結構いろいろあります。
プログラムの構造
今回の記事ではソースコードの詳細な説明はしませんが(どうせわかる人はコードを見ればわかるので)、簡単に全体の構造だけ紹介したいと思います。大まかに書くと、以下のような感じです。
csvファイルから参加者の情報(ユーザー名とユーザーID)を取得
→ 各ユーザーのサマリーページにアクセスして本のタイトルと著者名を抽出
→ csvファイルに書き出し
こんな感じですね。これを見ればわかるとおり、プログラムとしてはそんなに大したボリュームのものではありません(コード量的にも100行かそこらです)。開発しようとした段階では、もうちょっと複雑なものになるかなぁと考えていただけに、すこし肩透かしを食らった感すらありますw もちろん、それはBeautifulsoupの恩恵によるところが大きいです。htmlからの抽出がかなりシンプルなコードで実現できるので、こういうライブラリは非常にありがたいですね。
実際にデータを収集するためにアクセスするページは、読書メーターの先月の読書まとめページです。具体的には↓です。
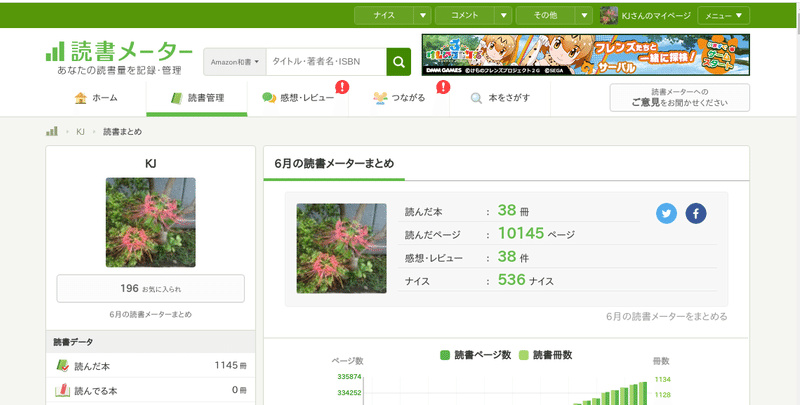
どうやら、「https://bookmeter.com/users/【ユーザーID】/summary」というURLが各ユーザーの先月読んだ本のまとめページになっているようです。あとはこのページのソースコード(html)とにらめっこしながら、どこを抽出すれば「本のタイトル」と「著者名」を拾ってこられるかを考えてコーディングしていきます。このあたりは慣れるまでちょっと時間がかかりましたが、色々と試行錯誤するうちになんとなくコツがわかってきた感じですね。Google Chromeのディベロッパーツールを使うとかなりいい感じに分析できます。
これは余談になりますが、今回自動化するに当たってのメリットとして、著者名を追加できるようになったことがあげられます。タイトルだけではなく、著者名もリストに入れることでより会話の幅も広がるかなぁとは思っていたので、今回それが実現出来たのは結構大きいです。もちろん手動でも出来ることは出来るのですが、流石に毎回そこまでやる気力はないのでやっていなかったんですよね。こういう追加的な情報を簡単に引っ張ってこれる来れるようになるのは自動化のメリットの一つです。
基本的にこのプログラムで概ね満足していますが、あえて改良点を上げるとすると出力形式についてです。現状はcsv形式で吐き出していますが、実際に参加者に配布するのは普通のエクセルの形式(.xlsx)なので、その変換に一手間かける必要があります。もちろん、一から手動でリストをつくるのに比べれば遥かに少ない労力ではありますが、この手間もなんとか減らしたいところです。調べてみたところ、Pythonでもエクセルを手軽に扱えるライブラリがあるようなので、近々改良したいと思っています。
>改良して、記事にしました!
仮想環境の構築
ついでというわけではないですが、LinuxにおけるPythonの開発環境の構築についても(備忘録的に)簡単に書いておきたいと思います。
Linuxにおいて注意しなければならないのは、OS自体の一部にPythonが用いられていることです。これが何を意味するかと言うと、OSにインストールされているPythonの環境をいじると、OSの機能に影響を与えてしまうということです。外部ライブラリなどを追加すると、依存関係や相性の問題でOSが動かなくなってしまうということもありえます。
そこで必要になるのが仮想環境。OSにプリインストールされているPythonを使うのではなく、特定のフォルダを仮想環境として、その中ではOSにインストールされているPythonとは独立して運用できるというものですね。これを使えば、OSとはバージョンが違うPythonを使うことが出来たり、依存関係を気にせず外部ライブラリを使うことができます(アプリケーションごとに違う環境を切り替えることも可)。
まずは仮想環境作成用のパッケージをインストール
$ sudo apt-get install python3-venvあとは、このvenvを使って仮想環境のフォルダを設定して、仮想環境をアクティブ化。
$ python3 -m venv {仮想環境フォルダ名}
$ cd {仮想環境フォルダ名}
$ source bin/activateここまでできたら、必要なパッケージをインストール。今回利用したのは、冒頭にも書いたとおり、RequestsとBeautifulsoup4です。
$ pip install requests
$ pip install beautifulsoup4あとはインタープリターの設定。コマンドラインに「python3」と打ったときに参照されるインタープリターを指定してあげるわけですね。今回使ったのはVScodeなので他のアプリケーションを使うとどうなのかはわかりませんが、VScodeの場合は「Ctl+Alt+p」を押せばインタープリターの設定ができます。ここで、OS側のPython3ではなく、仮想環境のものを選択するればOK。あとはバシバシとプラグラムコードを書いていくだけです。
まとめ
というわけで、今回はPythonで読書会のときに使うリストを自動化したことについて書いてみました。プログラムについては、わかる人はコードを見ればわかりますし、わからない人に一から説明するのは困難なので、記事を書くのはちょっと難しいですね(汗
Pythonは読みやすい言語だとは思うので、何かしらの言語でコーディングを勉強したことがある方であれば、プログラムを読めば何をやっているかなんとなくわかるとは思います。
今回、Beautifulsoupというライブラリを使ってみて、ウェブからデータを収集するというコードが思った以上に簡単にできるとわかりました。スクレイプ対象のページのhtml構造を把握するのは結構大変でしたが、そのあたりもなんとなくコツがわかってきたので、何か面白いものが思いつけばまた作れればなと思いました。
それでは、また!
この記事が気に入ったらサポートをしてみませんか?