
Python初心者 無料で学習を極める(11)

おはようございます。前回に、URL上からの画像取得ができましたね。
今度は、
そのサイトの状態を把握しながら、たくさんの画像をゲット★
を目標に進めていきます!この記事が読み終わったときには、HPってこんな風になっているんだなー。とか、知ることができると思います☆それではスタート!
HPの構造を理解する
HPには何も意識せずに閲覧が私たちは出来ていると思います。しかし、HPも実はコードで出来ているんですよねー。全然意識せず使っていませんでしたが、これからの方法を使うと、こんな感じなんだー。って感じると思います。是非参考に!
google chrome限定?「検証」について
今回、「もののけ姫」の画像を挙げて頂いてるサイトを元に話をしたいと思います。
こちらのサイトです。
ここのサイト上で、「右クリック」ー「検証」を押してください。
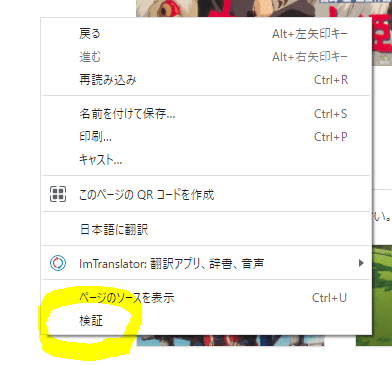
そうすると、この様な画面が表示されます

この右側に表示されたものが、本サイトのコードになります。この中の「▶」をクリックして展開をしていってください。そうすると・・・。

左側の一番上の部分の画像が選ばれた状態で、右側のコードが何を指しているか。見える事ができました。ここで分かる事は下記の事が言えますね。
左の図は
1)このURLに保存 :https://www.ghibli.jp/gallery/mononoke001.jpg
2)名前 :mononoke001
3)データサイズ :1920x1038
この様に、サイト上で検証を選択し、この画像はどんな形で保存されているのか。とみる事ができます。
これで、どの様な状態なのか。確認することが出来たと思います。
HPの傾向を確認する
先程、見たコードを見ていくと、一つの傾向を確認することができます。それは、
画像のURLの規則性
です。一番左上のURLでは、下記の様になっていました。
1)https://www.ghibli.jp/gallery/mononoke001.jpg
一番最後の右下の画像では、この様になっていました。
2)https://www.ghibli.jp/gallery/mononoke050.jpg
ここで、みると、下記の事が分かりますね。
1)もののけ姫の画像は50枚ある
2)保存されているURLの違いは、001-050 の数字のみ
これで、本サイトの傾向を確認できましたので、コードを書いていきましょう!
準備1)時間の概念
一つ前のサイトにも記載しました様に、前提条件を持ってスクレイピングを行う必要があります。もう一度思い出す場合は、下記を見て下さいね。
その為、前提条件の3項に挙げた内容に対応する必要があります。
3)取得先のサイトに負荷を与えない用に人のアナログ操作で出来る範囲の画像取得にする
色々な手法があるそうですが、私はtime.sleep()ライブラリを使用致します。スクレイピングを実行される為には、ステップがあるそうでして、そのステップを細分化し、適した時間設定で行う別のライブラリもあるそうですが、私の今の知識では分からない為、time.sleep() を用いていきます。
イメージとして、前段階としては、①それを使います宣言、②どれくらいの時間をあけますか?設定、③どんな処理? を設定できればOKと思います。
例題)1秒間隔で、数字のカウントアップ値を表示させる
を実施してみましょう。
#time関数を使います宣言
import time
#何を出力していきますか?
for num in range(1,6):
print(num)
time.sleep(1)めっちゃ簡単。笑。これで、1秒間隔で数字がカウントアップしていくことが確認できました。
準備2)連番のURLの作成
HPの傾向を確認していますので、数字が異なる部分のみを表示し続けるコードを書いてみます。ここでは、URLを記載しますので、文字列(str)を使用し、コードを作成してみましょう。
for num in range(1,6):
url="https://www.ghibli.jp/gallery/mononoke{}.jpg".format(str(num).zfill(3))
print(url)
time.sleep(1)
#出力結果
https://www.ghibli.jp/gallery/mononoke001.jpg
https://www.ghibli.jp/gallery/mononoke002.jpg
https://www.ghibli.jp/gallery/mononoke003.jpg
https://www.ghibli.jp/gallery/mononoke004.jpg
https://www.ghibli.jp/gallery/mononoke005.jpg出力結果はいい感じになりましたね。1秒毎にURLを出力することを実行できています。ここまでで、URLの準備ができました。それでは、実際に画像を取得してみましょう。一度に50枚も保存するのは恐ろしいので、ステップを踏みます。(怖がりですみません)
少ない枚数を保存(2枚)をトライ
それでは、今までの準備を用いてコードを記載してみました。状態が分かる様にしたかったので、URLを作っている時に、作成中と表示させ、画像出力ができたタイミングで、完成と表示させることが出来るようにしました。
#1枚目と2枚目を入手したい
for i in range(1,3):
print("{}枚目作成中".format(i))
url = "https://www.ghibli.jp/gallery/mononoke{}.jpg".format(str(i).zfill(3))
file_name = "mononoke{}.jpg".format(str(i).zfill(3))
#ちょっと2秒くらい待ってほしい
time.sleep(2)
response = requests.get(url)
image = response.content
#画像保存をやり切ってね文章
with open(file_name, "wb") as files:
files.write(image)
print("{}枚目完成".format(i))その結果・・・・。

きたーーーーーーー!二つの画像が保存されたことを確認できました!!
jupyternotebook画面上でも、実際に今やってるよー。(作成中)とのコメントあり、わくわくしながらみていました。
では、続いて本番です!50枚の画像があるため、一つのフォルダに保存しましょう。
本番!50枚の画像を一気に取得!
ここまでくれば怖いものはありませんね。それでは、実際に下記のコードを書いてトライしましたのでご報告します!
※フォルダ作成方法があるみたいですが、ちょっと理解しきれていないため、事前にフォルダ作成した状態ですすめます。すみません。
for i in range(1,51):
print("{}枚目作成中".format(i))
url = "https://www.ghibli.jp/gallery/mononoke{}.jpg".format(str(i).zfill(3))
file_name = "mononoke/mononoke{}.jpg".format(str(i).zfill(3))
time.sleep(1)
response = requests.get(url)
image = response.content
with open(file_name, "wb") as files:
files.write(image)
print("{}枚目完成".format(i))結果・・・。

すごーーい。約1分?ですべてを検出することができました!これで、また学習に活用できるデータを取得することができましたね。ジブリの皆様には感謝でございます。それでは本日はここまで~。
次回は、
他のジブリ作品の傾向を確認し、すべての写真を入手してみましょう!
にトライします。それではまた!
よろしければサポート頂けると幸いです!子供へのパパ時間提供の御礼(お菓子)に活用させて頂きます☆