AppFlowを使ったS3のCSVファイル→ Salesforce連携について

この記事について
業務でAppFlowを使って以下を実装したので、その際に気づいたこと、設定方法を紹介したいと思います。
S3に出力されたCSVファイルをSalesforceのオブジェクトのレコードとして連携
反対にSalesforceのオブジェクトのレコードをCSVファイルとしてS3に出力
この記事では、「S3に出力されたCSVファイルをSalesforceのオブジェクトのレコードとして連携」の手順を紹介していきます。
そもそもAppFlowとは?
公式によると以下の説明があります。
Amazon AppFlow は、Salesforce、SAP、Zendesk、Slack、および ServiceNow などの SaaS (Software-as-a-Service) アプリケーションと、Amazon S3 や Amazon Redshift などの AWS のサービスとの間で、たった数回のクリックでデータを安全に転送できるフルマネージド統合サービスです。
データを投入するだけなら、APIを使って投入するスクリプトを書けば良いですが、
スケジュール実行
データソース(主にS3)の暗号化
エラーハンドリング
データの値による投入するか否かの判断
などを実装でカバーするのは大変です。
しかも、投入したいデータはCSVかもしれないし、JSONかもしれないしでデータの形式に合わせて実装を変えるのも面倒です。
そういった面倒くさいことを丸っと行ってくれるのがAppFlowです。
AppFlowはさまざまなSaasサービスとの統合ができますが、その中でも今回はSalesforceを選択してこの記事のタイトルについて構築してみます。
AppFlow作ってみる(S3 → Salesforce)
以下の手順でAppFlowを作ってみます。
※ Salesforceは事前にユーザ登録をしておいてください。参考はこちら。
手順1: Salesforceでカスタムオブジェクトを作成
項目は適当に定義しましたが、以下のように定義しました。
勤怠情報(労働時間)を格納するオブジェクトを作りました。
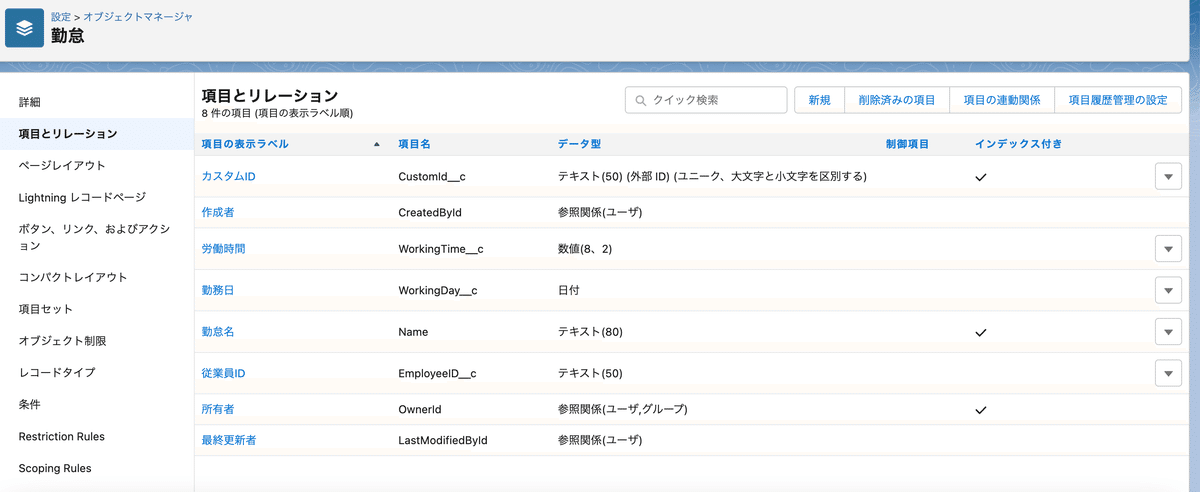
今回はレコードのupsert要件に対応できるようにしたいので、カスタムIDを外部キーとして定義しました。
カスタムIDのコード体系は、勤務日 + 従業員ID を想定しています。
※カスタムオブジェクトID(Salesforceで自動生成されるレコードを一意に特定するID)をupsertの条件キーとしてもいいのですが、その値を別の場所で管理する必要があるので、今回は項目を複数組み合わせて作成できる複合キーを外部キーとします。
手順2:S3にCSVファイルの配置
先程作成したカスタムオブジェクトにデータ投入するためのCSVファイルを作成して、S3に配置していきます。
CustomId__c,WorkingDay__c,EmployeeID__c,WorkingTime__c
20220211_ABCDEF1,2022-02-11,ABCDEF1,8
20220211_ABCDEF2,2022-02-11,ABCDEF2,6
20220211_ABCDEF3,2022-02-11,ABCDEF3,5今回、CSVファイルはs3の
s3://test-bucket-to-salesforce/attendance/に配置します。
ここはAppFlowが取り込むS3のpathになります。

手順3:AppFlowとSalesforceとの接続情報の作成
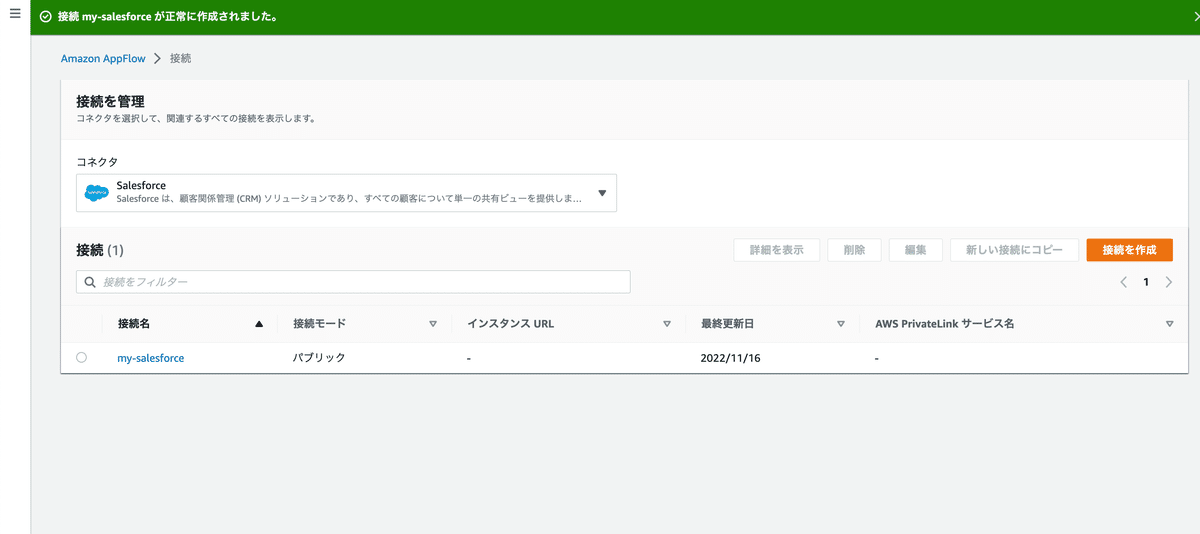
AppFlowの画面に移動し、左タブで「接続」を選択。
コネクタで Salesforce を選択。
「接続を作成」をクリックして、Salesforceと接続情報を作成する。
項目を適当に入力。
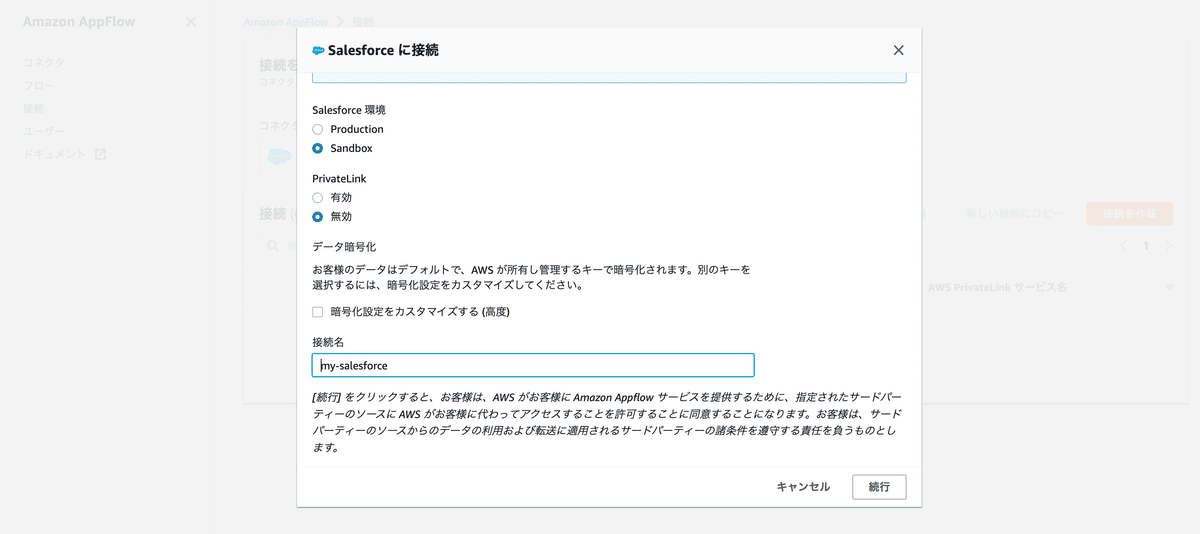
あとは先ほど作成したSalesforceの情報を入力して接続を作成する。
手順4:AppFlowの構築
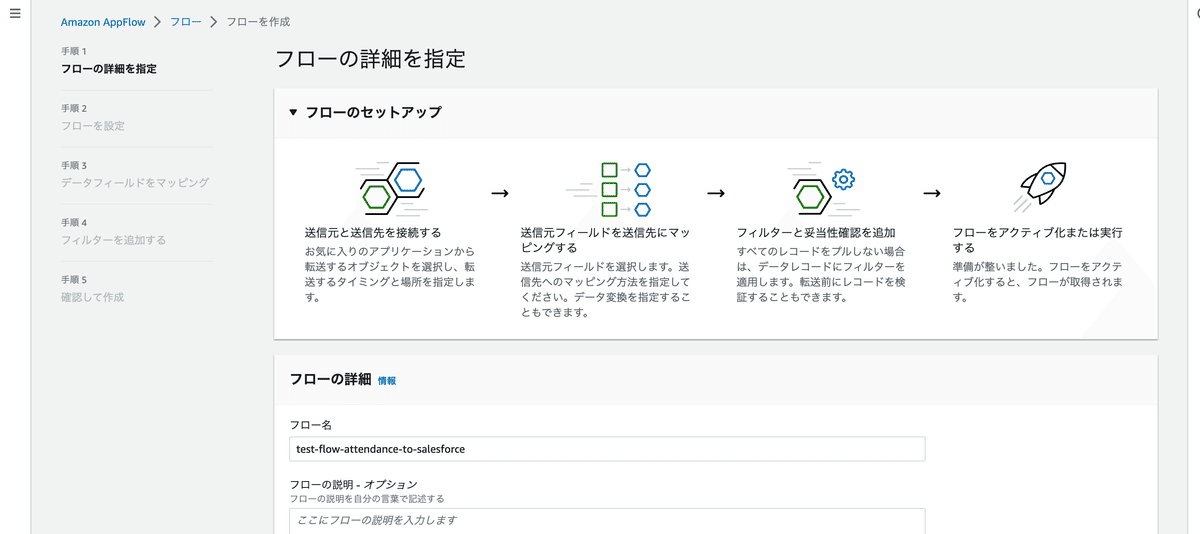
ここからはAppFlowをしていきます。
まずはフローの詳細を設定。
フロー名を適当に入力。
データ暗号化、タグという項目がありますが、ここでは入力しません。
次は、フローを設定。
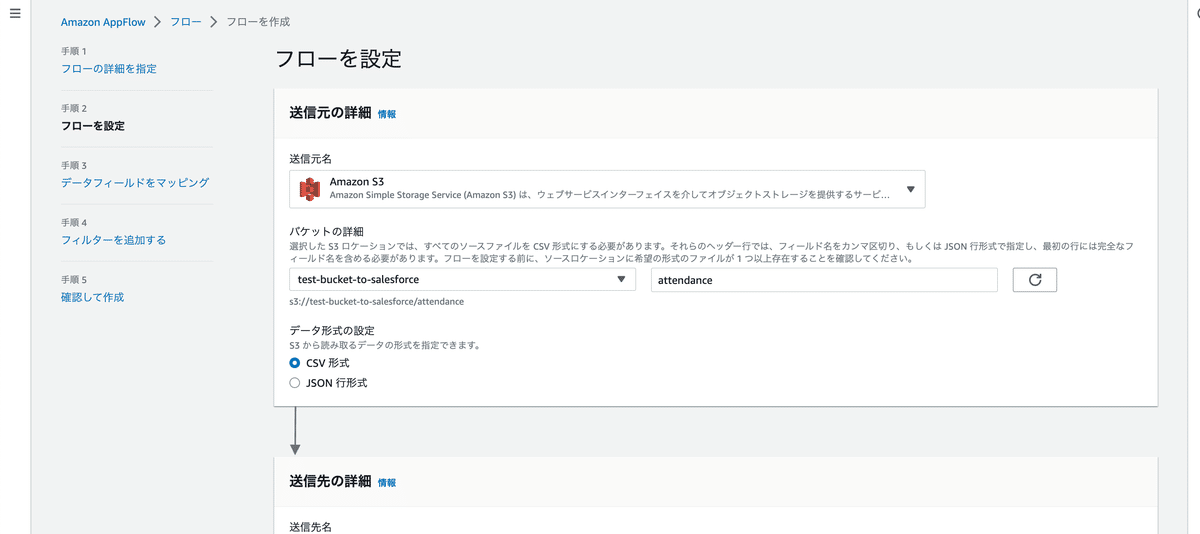
送信元の詳細で、送信元名をS3を選択。
さらに、バケットの詳細で「CSVファイルの配置先」を指定します。
送信先の詳細で、Salesforceを選択。
選択したら「接続する」で先ほど作成した接続情報を選択します。
さらに、先ほど作成したカスタムオブジェクトの「勤怠」を選択します。

エラー処理では、「現在のフロー実行を停止する」を選択します。
また、「転送できなかったデータを書き込む」ではエラーが発生した時のレコードのログを出力するPathを選択します。
ここでは、以下を選択します。
s3://test-bucket-to-salesforce/attendance/failed※補足)
・「現在のフロー実行を停止する」はCSVレコードを順番にSalesforceに取り込んでいく中でデータの取り込み失敗(データ型が異なるなど)した場合は、途中で取り込みを打ち切る挙動。取り込みを打ち切った場合はAppFlowの実行ステータスがエラーとして残る。
・「フロー実行を無視して続行する」はCSVレコードを取り込む際、データの取り込み失敗(データ型が異なるなど)した場合も、途中で取り込みを打ち切らない挙動。AppFlowの実行ステータスがエラーとして残らない。
また、フロートリガーでオンデマンドで実行を選択します。
スケジュール実行を選択すると、実行時間やどれくらいのタイミング(分ごと/時間ごと …etc)で取り込むかの指定、転送モード(全分 or 差分)が選択できます。

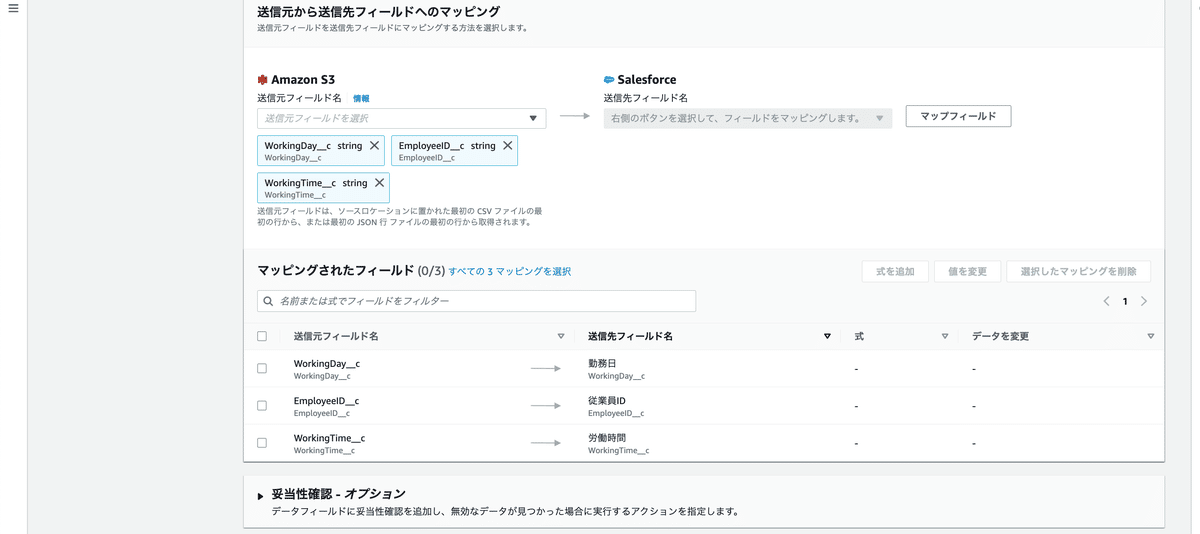
データフィールドをマッピングで、「手動でフィールドをマッピングする」を選択。
ここでいうマッピングは、送信元フィールド(S3に格納されたCSVの項目)と送信先フィールド(Salesforceオブジェクト項目)の対応のことです。
※「マッピングされたフィールドを含む .csv ファイルをアップロードする」を選択すると、マッピングを定義したCSVファイルをアップロードすることで、マッピングできます。
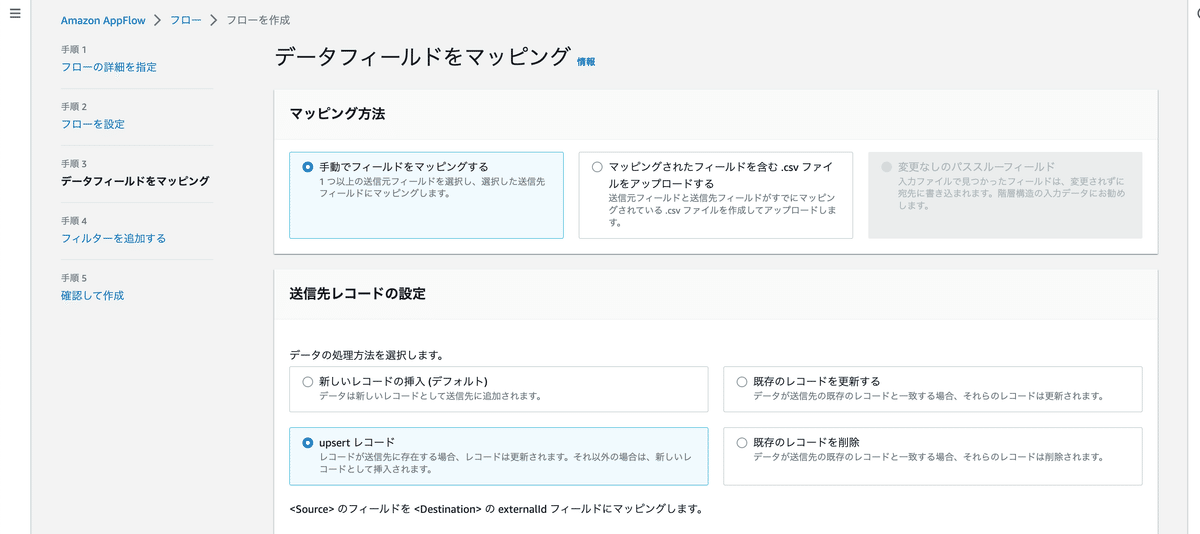
送信先レコードの設定では「upsertレコード」を選択して、
upsert されたフィールドでは、CustomId_c を選択します。

送信元から送信先フィールドへのマッピングでは、マッピングされたフィールドを選択します。
左側がCSVのフィールド名(CSVキー名)で、右側がSalesforceオブジェクトの項目名。
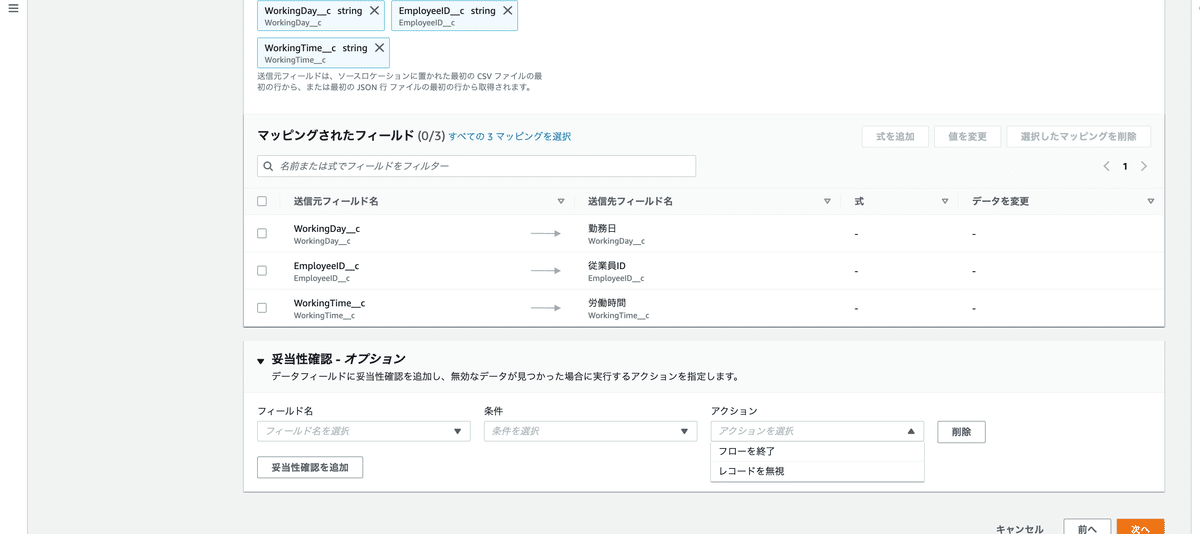
ここでは選択しませんが、妥当性確認ではCSVの特定のフィールドがある条件になったときに「フローを終了」か「レコードを無視(取り込み無視)」を選択できます。
あとは流れで進めてフローを作成完了します。
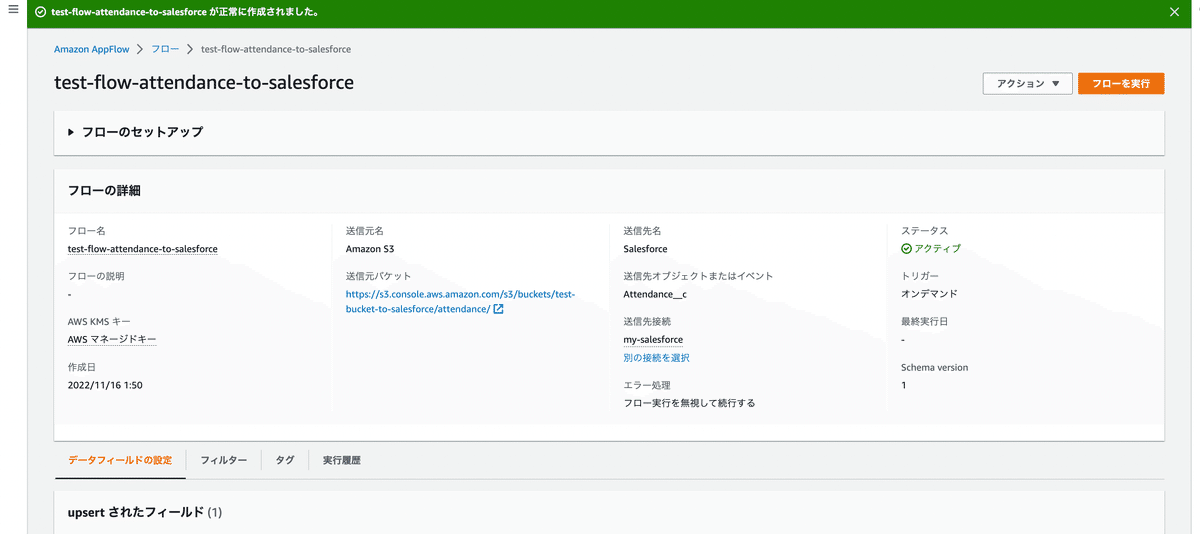
動作確認してみます。右上のフローを実行をクリックします。
オンデマンドなので、実行されます。

三件成功とポップアップ出ました。
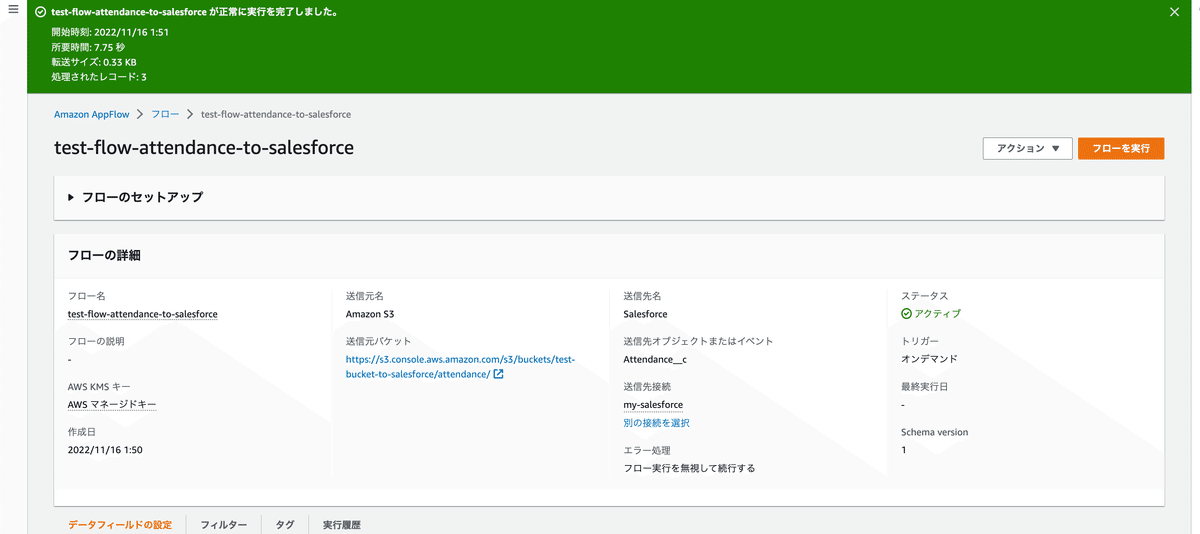
Salesforce見てみます。
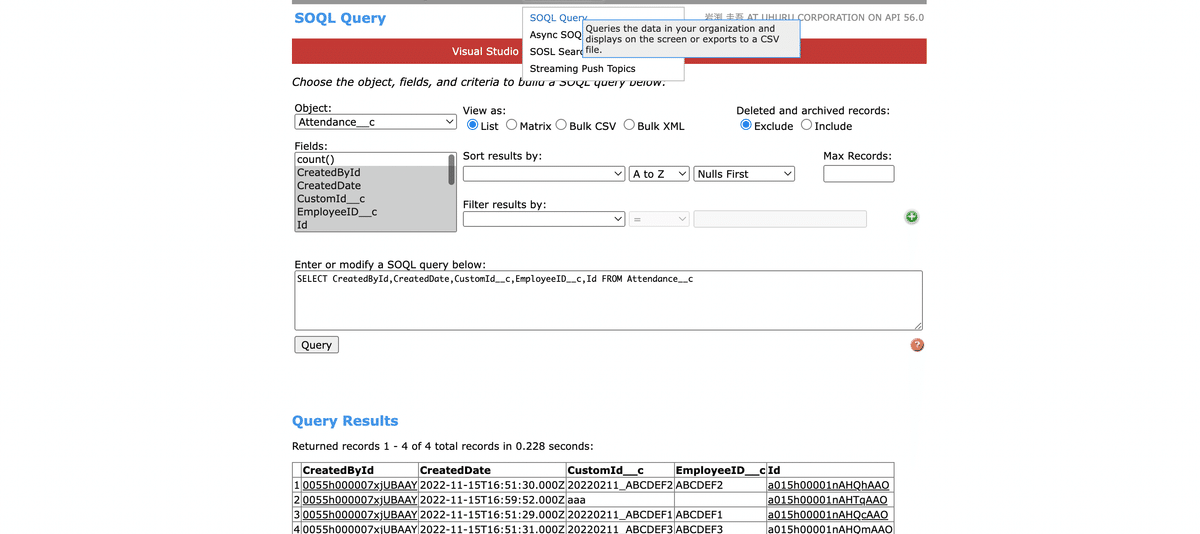
カスタムオブジェクトのリストビューとレポートの作り方わからなかったので、workbench 使ってみました。
使い方はログイン画面から自分のSalesforceアカウントにアクセスして、下記画像のタブからアクセスしてクエリを打つだけです。
打ってみた結果以下のようになってます。ちゃんと登録されてることが確認できました。
※1個余分なレコードありますが、これは私がSalesforce上でごちゃごちゃ作業してて作ったものです。。
長かったですね。お疲れ様です🙇♂️
Salesforceの作業でちょっと詰まりましたが、なんとか最後まで到達しました。
次は、「反対にSalesforceのオブジェクトのレコードをCSVファイルとしてS3に出力」の手順を別記事で紹介していきます。
この記事が気に入ったらサポートをしてみませんか?