
【回収率150%】100万円を1年で儲ける競馬AIの作り方|「当たる」予想から脱却しよう

注意事項
・この記事は「確実に儲かる」ことを保証するものではありません。必ず自己責任でご利用ください。
・AIさえ使えばすぐに大勝ちできると思っている方は購入をお控えください。
・十分な余剰資金(少なくとも5万円)のない方はまずお金を貯めましょう。
・ある程度プログラミングの知識が必要です。Python、機械学習の経験があると進めやすいでしょう。
この記事では
「競馬AIの作り方とその運用法」
をお伝えします。
「競馬AIを開発したもののテストデータですらプラス収支にならない……」
「AIを作って競馬で勝ちたいがどうすればいいかわからない……」
こんな悩みを抱えていませんか?
タイトルにもある通り、「予想を当てる」ことを重視していては「回収できる」競馬AIは作れません。
僕が競馬AIの開発に着手してから1年足らず、試行錯誤の末に以下のようなテスト収支を出せるようになりました。
最終残高:1468970 円 最低残高:-42530 円 回収率:151 % 的中率:0.82 %

これは2023年1月から10月までの期間、僕のAIに三連複の馬券を買わせていたらどうなったかの収支グラフです。le6というのは0が6つ、つまり100万円単位ということになります。
2023年だけ運が良かったわけではありません。以下のデータをご覧ください。
0 最終残高:4155110 円 最低残高:-1800 円 回収率:181 % 的中率:0.99 %
1 最終残高:3791760 円 最低残高:-11370 円 回収率:186 % 的中率:0.98 %
2 最終残高:3967910 円 最低残高:-7260 円 回収率:185 % 的中率:1.03 %
3 最終残高:3115040 円 最低残高:-42020 円 回収率:176 % 的中率:1.2 %
4 最終残高:4006780 円 最低残高:-37420 円 回収率:191 % 的中率:1.18 %
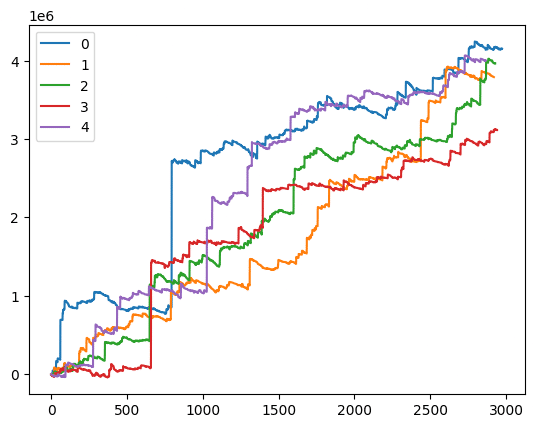
こちらは2008年から2022年までの15年間を3年ずつ5つに分割して収支をシミュレーションしたものです。
0から2までの9年分は訓練データなのでいい結果なのは当然ですが、3と4のテストデータでもそれぞれ300万円のプラスを達成しています。
ついでに単勝のデータもどうぞ。
0 最終残高:1508830 円 最低残高:943500 円 回収率:190 % 的中率:11.3 %
1 最終残高:1499050 円 最低残高:970600 円 回収率:192 % 的中率:14.3 %
2 最終残高:1514200 円 最低残高:998700 円 回収率:189 % 的中率:20.9 %
3 最終残高:1357810 円 最低残高:764900 円 回収率:139 % 的中率:14.9 %
4 最終残高:1596280 円 最低残高:951640 円 回収率:143 % 的中率:13.3 %
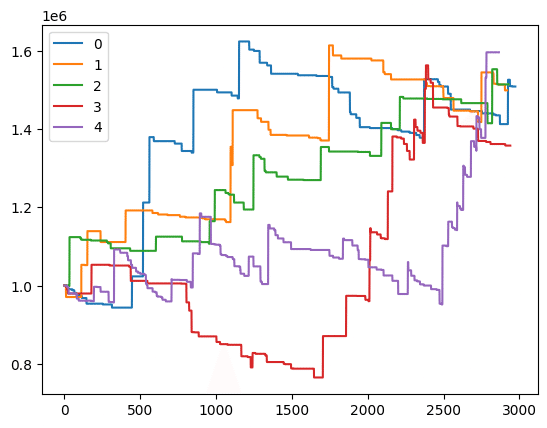
単勝では初期残高を設定し、残高とオッズに応じて収支が均等になるよう馬券を買う低リスクな方法でトレーニングしました。三連複よりは伸びが悪いですがしっかりプラスになっています。
この記事を読めば、ここに至るまでの成功と失敗から得た以下のようなノウハウを手に入れることができます。
・選択すべきアルゴリズムとそうでないもの
・データ分析の手法
・買い目と金額の決め方
・自動で馬券を購入する方法
競馬AIは利害に直結するせいで開発プロセスが秘匿され、個々人がほとんど0からのスタートを余儀なくされています。
この記事で僕の足跡を辿れば、車輪の再発明に費やす1年をスキップし自分の望むAIへ最短で行き着くことができるでしょう。まあ再発明は勉強になるので、どちらかと言えば競馬AIを開発中ではあるものの行き詰まった人向けです。
ひな形の入手
競馬AI開発における前準備はデータのスクレイピング、整形、加工など多岐にわたり結構面倒です。
こうした環境をまとめて整備してくれているひな形があるのでこちらを導入しましょう。
価格は2000円です。購入すると特典としてコミュニティに入ることができます。自由に質問できる上、著者と共同作業者によりソースコードも随時更新されていくのでおすすめです。
うまくいかなかったアルゴリズム
これらは僕が失敗したというだけでもしかしたら適切な手法も含まれているかもしれません。
ただ、まず成功することはないと考えていいものもいくつかあります。
クラス分類
クラス分類による着順予測はその「いくつか」の筆頭です。プラス収支になってもごく短い期間か買い目が非常に少ないかといった具合で希望が見えませんでした。
もしこれで成功した人がいれば純粋にやり方が気になるので教えてほしいです。本人は秘密にしたいかもしれませんが……。
ランク学習
強力なアルゴリズムですが、着順予測に使うのであれば適切な手段とは言えないでしょう。
ランク学習は文字通り情報を重要度順にランク付けする手法で、検索エンジンのサーチ結果を並べたりするのに使われます。
通常の訓練、検証、テストデータの他にクエリと呼ばれるグループの情報が必要だったり、日本語の文献が少なかったりとハードルが高いわりに成果があまり出なかったのを覚えています。
一応補足をすると競馬AIのトップランナー、AlphaImpactではランク学習の評価指標であるNDCGを使ってオッズを予測しています。ただこちらもAI本体に使用しているわけではなく、「前日にオッズを見たい人もいるだろうから」ぐらいの理由で提供しているらしいです。
ロジスティック回帰
ロジスティック回帰は着順予測の中で一番希望があります。連対確率を出せばオッズを用いて最適化問題に持ち込めるからです。
僕はうまくいきませんでしたが、これらから算出した期待値に基づいて馬券を購入すれば回収率100%を超える可能性があります。
以下の記事に詳しいので気になる方はご覧ください。
タイム予測
ちょっとだけ挑戦したのですが、いい結果が出る兆候がなかったのでやめました。
この方はTARGETの補正タイムを使ってうまくいっているらしいです。
強化学習 (DQN)
DQNは深層強化学習の一種です。以下の記事に詳しく書いてあります。
DQNの考え方自体は競馬AIの目的に即しているのですが仕様の面で二つ問題があります。
まず一つに「行動空間のサイズが常に一定であることを想定している」点があります。例えば単勝を扱う競馬AIにおいて、行動空間はそれぞれの馬についての購入枚数を出走頭数だけ並べた1次元配列です。
しかしご存じのように出走頭数はレースによって違います。1レースごとに行動空間のサイズを変更すると計算負荷が高くなる上、適切に学習できません。
最大出走頭数18をサイズとして足りない分を0で埋めるという方法もあるのですが、それだと大きい馬番の学習が正しく行えないという問題が出てきます。これが一つ目の欠点です。
二つ目が「行動による状態の変化が前提である」点です。DQNでは基本的に同じ空間で違う行動を繰り返し、状態と報酬がどうなるかを観測します。競馬AIではおそらく出馬表のテーブルデータを状態として見せることになるのですが、馬券を買ったからといって出馬表それ自体は変化しません。
買い目を決定させたら次の出馬表を見せる、というやり方なら確かに変化はしますが、それは行動の結果ではありません。したがってネットワークにとって意味のある情報は報酬だけ、ということになります。
以上の二点からDQNを競馬AIに適用するのは難しく、やるにしても相応の工夫が必要という結論に至りました。
着順予測について
ここまでお読みいただけるとわかると思うのですが、着順予測それ自体が回収率向上を目指す上で不適切と言えます。
理由はいくつか考えられますが、その一つが「間接的すぎる」ということです。
競馬において払い戻しを受けるまでのプロセスを分解すると以下のようになります。
予想→買い目決定→払い戻し
競馬AIを作る以上最大化したいのは払い戻しのはずですが、着順予測では予想を対象に最適化を試みてしまっています。着順予測、つまり「予想を当てること」が失敗する主要因はここにあると考えていいでしょう。
じゃあどうすればいいかは次の『選択すべきアルゴリズム』でお話しします。
ここから先は
この記事が気に入ったらサポートをしてみませんか?