
C言語教室 第12回 - 中間まとめと振り返り

かれこれC言語教室も、今回で12回目となります。教室は以下のマガジンにまとめられているので、これから挑戦してみようという方は、ぜひ最初から読んでいただければ嬉しいです。
C言語教室
まず「やってみよう」という事で、あまり細かな文法にこだわらず、良く使う、そして、良く間違うような部分に焦点をあててきたつもりです。そのため、急に説明していない使い方が出てくることもありますが、そこは単に真似をしたり、他のドキュメントをネットで探したりしていただければ幸いです。
これまでの回をザックリと振り返ると以下のような感じになるかと。
第1回 - 関数の宣言のやり方、変数のスコープ
第2回 - 参照渡しとポインタ
第3回 - 配列 - 多次元配列 配列の初期化
第4回 - 配列を引き数に使う
第5回 - 文字列のキホン
第6回 - 文字列操作 - コピーと終端文字
第7回 - mallocとfree
第8回 - 文字列操作関数 constなど
第9回 - 演算子 - 優先順位 - インクリメントの前と後
第10回 - 文字種判定 文字コード
第11回 - プリプロセッサとマクロ 大文字と小文字
ようやく関数とは何か、関数と変数をやりとりするにはどうすればよいのか、それから配列と文字列を使う方法まで来ました。これだけである程度のコードは書けるはずです。この後、構造体とファイル入出力まで済めば、いろいろなアルゴリズムをC言語で、どのように表現できるかに取り組めそうです。
ただ、我が家での教室でもですが、今までの範囲でも理解するのが難しくハマってしまうところがあるようです。そもそも例示されているコードのどの部分が何をしているのか、もっと説明してほしいと指摘されてしまいました。やはりポインタが鬼門で、まだ基本的な使い方しかしていないつもりですが、’*’と’&’の関係、そして配列とポインタの関係を理解するのが大変みたいです。
そこでここで指摘されたいくつかの疑問に対して、簡単に補足をしたいと思います。ところどころ込み入ったことも書いてしまいましたが、そんなこともあるんだと流してください。
空白とインデント
C言語の名前はアルファベット(通常は小文字)から始まり、数値は数字から始めるという規則があるので、宣言であるとか式の中で空白で区切るのは、そこまでが名前であると明示するとき以外は空白を入れなくて大丈夫です。例えば、
#include <stdio.h>
int main(){printf(“hello\n”);}とギュッと詰めても問題ありません。プリプロセッサ命令が行に対して効果があるので、ここで改行しなければならないのと、int と main の間を空白で区切らないと intmain という名前になってしまい別の意味になるのでダメなだけです。
一般的には「読みやすさ」の為に、ひとつの文ごとに改行し、関数自身や if や for といった{} で囲んで複数の文を書けるところを、その範囲を間違えないように、左側にタブや空白をいれて同じ文字位置から始まるように「インデント」します。また大きなまとまりを示す必要がある時には何も書かない空行を挿入することも一般的です。
#include <stdio.h>
int main() {
printf(“hello\n”);
}ここで、{}だけで1行としたり、インデントは空白何文字分なのかは、いろいろな流儀があって、どれが良いかはいろいろな理由があって一概には言えません。どのように書いてもC言語的には正しくて、これが理由でエラーが出たりすることは無いというのだけ覚えておいてください。
#include <stdio.h>
int
main()
{
printf( “hello\n” );
}※python だけはインデントに言語としての意味がありますね。
宣言、特にポインタ型の宣言に関しても、*の前後の空白に意味はなく、
char*s;と書いても大丈夫ですし、
char *s;でも
char* s;でも同じ意味です。* は型の一部なので、char* s と書きたいところですが、char *s と書くほうが一般的です。もちろん char * s と書いても構いません。
ポインタ変数
ポインタ変数という考え方をC言語で覚えるのは、あまり良くないようで、考え方としては PASCAL におけるポインタの方が相応しいかもしれません。動的なメモリ割り当てや、他で宣言されている変数の一部を指すときなどに使うもので、ポインタ変数の値がどのように実装されているのかを知ることはできませんし、知る必要もありません。このためポインタ変数に対してできることが制限されており、間違っても2つのポインタ値の差分を取って領域の大きさを知ろうなんて使い方はできません。これはPASCAL系の言語であるDelphiやObjective-PASCALでも同様なので、そちらの仕様も見てみると勉強になります。
Pascal 入門
なんでポインタ演算ができないのよ(しくしく)
もうひとつ先に覚えたほうが楽かもしれないのがアセンブラです。レジスタにメモリから値をとってくるのに、アドレスを直接指定するアブソリュート(絶対)アドレス指定だけではなく、指定したアドレスのメモリの中身をアドレスとして使うインダイレクト(間接)アドレス指定というアドレッシングモードがあります。C言語のポインタはまさにコレで、ポインタ変数の値はメモリアドレスであって、実際にこのアドレスを使って指している値を取り出すのです。
8086の例
mov ax,[di]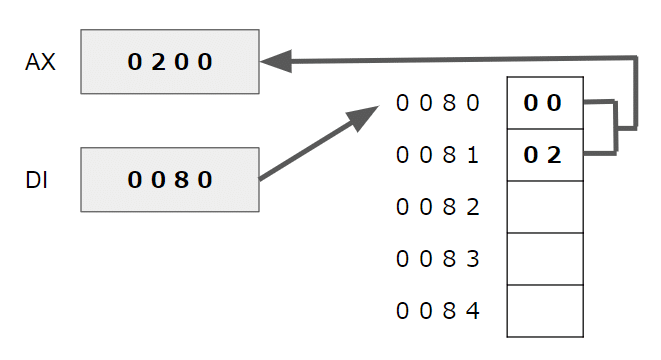
68000の例
move.w (a0),d0
86系と68系ではバイトオーダだけではなくてオペランドの順序も逆だったんですよね。アセンブラ表記は方言も多いので少し違う書き方になることもあります。
ということで、ポインタ変数が何を指しているのかを説明するのに、以下のような箱と矢印で指す図を使うことが良くあります。

なお、ポインタの指す先が無い、ポインタの値が無効であることを示すのに NULL が用いられますが、NULL の定義は 0 です。C言語を動かすシステムでは、アドレス0 は無効であり使われることは無いという前提になっています。実際にはアドレス0 は存在し、ここを読み書きすることはできるのですが、ライブラリプログラムやOSがこれを検出するように頑張っていますし、アドレスが 0 であるかをチェックするコードもあちらこちらに存在するので、使いたくても使ってはいけません。余談ですが大型機にC言語を移植する時に、どうしてもアドレス0へアクセスしたくて NULL の定義を変えてみましたが、既存のコードが 0 であることを前提としているために、正しく変えることは不可能でした。なお最新の C++ では、型システムの問題で NULL は 0 と「定義」されていたのが、nullptr というキーワードを使うように変わったようです。
ポインタ (プログラミング)
C++11 では NULL ではなく nullptr を使う - C++ プログラミング
配列変数とポインタ変数
配列変数の値を舐める(すべての要素にアクセスすることを、良くこのように呼びます)時に、添字の数を最小(0)から最大(サイズで指定した値-1)まで変化させる方法が、多くの言語では一般的ですが、C言語では先頭の要素へのポインタで初期化して、インクリメントしながらアクセスするほうが一般的です。
配列変数を配列の添字を指定して初期化する例
#define MAX (10)
int v[MAX];
for ( i = 0; i < MAX; i++) {
v[i] = 0;
}配列変数を配列の要素へのポインタを使って初期化する例
#define MAX (10)
int v[MAX];
int *p = v;
for ( i = 0; i < MAX; i++) {
*p++ = 0;
}そもそもは、添字を指定する方法だと、初期化する変数のアドレスを求めるのに、毎回、配列の先頭アドレスに対して、添え字に一つ分の要素の大きさを掛けたオフセットを加算する必要があり、これよりもアドレスを都度、一つ分の要素の大きさを加えてオフセットを計算したほうが速いよね。ということが言われていたのですが、最近のCコンパイラであれば、この程度の処理はオプティマイザが何とかしてくれることも良くあります。それよりも配列(などの集合型)を舐めるときには、イテレートするものだという考え方が主流となり、イテレートするためにイテレータ(反復子)というオブジェクトを用意して、これを使って舐めるべしということになっています。
イテレータを使えば、オブジェクトの数や繰り返しの際に必要な処理が見やすくなるのですが、残念ながらC言語には実装されていないので「それっぽく」書くのが精一杯です。イテレータっぽく書く時に注意する必要があるのは、それぞれの要素の処理の中に、他の要素へのアクセスが出来ないことです。また処理の順序も必ずしも決まっていません(大抵は先頭からですが)。一部のC++コンパイラなどはイテレートされている処理を自動的に並列実行するようなコードを吐くこともあるので、これからのマルチコア時代を考えると、今のうちに、この考え方に慣れておいたほうが良いと思います。それに慣れると見やすいですよ。
イテレータ
そうそう教室の中でも触れましたが、配列変数の型、例えば int[] と int* は、同じようにも見えますが違う型です。int[] は安全に int* に変換できるだけです。int[] は定数なので代入することは出来ません。C言語には他にリテラルくらいにしか定数が無いので(constがついている変数は、書き換えできない「変数」なのであって定数ではありません)、見慣れていないかもしれませんが、定数にも型はあるんだよと覚えておいてください。int* の配列を使ったりすると、今度は int*[] であるとか int** とかが登場して、とてもわかりにくくなり、エラーメッセーにも int* pa[] みたいなメッセージが出てきて、かなり混乱しますが、この例だと変数名 pa の型は int* [] なんだと読むわけです。なんだか変数名が型名に挟まれて、ドイツ語みたいに前後に分かれますが(ドイツ語をご存知の方しか通じなくてすいません)、これは慣れるしかなさそうです。困ったときは、やはり図を描くのが良さそうです。
コメント
サンプルコードには、コメントを入れていませんでした。コメントを入れるほどの長さではなく、コメントにある説明ではなくて、コードに集中してほしいと思い、あえて入れていませんでしたが、そろそろ込み入ったコードも出そうなので、今後は適宜、コメントも入れておこうと思います。
コメントって、大切なのですが、あくまで人間が読むもので、コンパイラは読んでくれません。書いた人が大事だと思ったことと、読む人が必要など思うことも、必ずしも一致しませんし、一番恐ろしいのが、コードを修正した際に適切にコメントが修正されないことです。今日のコメントは明日の大嘘つきである可能性があるのです。人の書いたコードを読むにつけ、どうもコメントは信用できないと思うようになってしまったのが、コメントが少ない遠因かもしれません。コードのところどころにあるコメントよりも、コメントの形式かもしれませんが関数の単位で、しっかりと仕様と実装の說明が書いてある方が個人的には好みです。
さて、結構、長くなってしまったので、中間テストは別に用意したいと思います。そうそう前回の解答編もこれから用意しますので、もう少しお待ちを。
これからも末永く読んでいただければ幸せです。先は長そう。
ヘッダ画像は、今回もいらすとやさんより
https://www.irasutoya.com/2017/02/blog-post_284.html
この記事が気に入ったらサポートをしてみませんか?