
[Python]AIに自分好みのラーメンを見つけてもらおう(其の一:ラーメン画像の識別)

[はじめに]
こんにちは、@Kazunori-Gotoと申します。
最近プログラミングの勉強をしております。学習のアウトプットとして本記事を投稿します。未熟者故、至らぬ点やつっこみ所が満載かと存じますが、生暖かくご指摘・コメントいただければ幸いです。
[目的]
僕は今、Aidemy Premium Planという、未経験者が機械学習、ディープラーニング等の先端技術を3か月で学べるオンライン学習サービスでPythonプログラミングの勉強をしています。
なかでもAIアプリ開発というコースを受講しており、その中で成果物として画像認識アプリの制作に取り組んでいます。
僕が現在製作しているアプリは、「ラーメン、ギョーザ、チャーハンのいずれかの画像を渡すと、AIがどの料理なのかを分類してくれる」ものです。この記事ではその制作過程を紹介します。
タイトルにもある通り、最終的には画像認識の技術を使って、AIに自分好みのラーメンを見つけてもらうアプリの制作を目指していますが、コース受講期間の関係で、今回は一旦ここで区切ります。
[ラーメンアプリ制作のきっかけ]
きっかけは、僕が見知らぬ土地でラーメン屋さんを選ぶ時、食べログなどに載っている”ラーメンの写真で選ぶ”ことが多いと気付いたことでした。
僕はラーメンが大好きでよく食べに行くんですが、例えば初めて来た土地でラーメン屋さんを探す時なんかはハズレを引くのを嫌って、食べログやラーメンデータベース等で下調べをしてから行くことが多いです。
食べログ等でラーメン屋さんを探す際、近場且つレビューの評価が高いものがまず候補として挙がりますが、このレビューが曲者。ラーメンという食べ物は種類が膨大にあり、また味の好みに依るところが多い為か、レビューが高いラーメン屋さんが必ずしも”自分にとっても”美味しいとは限らないということを今まで幾度となく経験してきました。
そこで、僕はいつも近場且つレビューの評価が高いお店の中でも、最終的にラーメンの写真を見て、”自分の好みとマッチしてそうか”を確認してから選択します。この手法で選んだ店だとまぁほとんどの(自分にとっての)ハズレは回避できると思っています。
プログラミングを勉強する中で、「折角なら何か役に立つアプリが作りたいなー」とか「自分がやっている作業をAIにやってもらいたいなー」と思った時、ふとこのことを思い出したのです。
ラーメンの画像からは、ラーメンの大まかな種類、めんの太さ・ちぢれ具合、スープの濁り具合、具材の種類など、”自分の好み”とマッチするかを判断する為の情報が多く読み取れます。
AIにこのビジュアルとしての”自分の好み”を学習させたら、レビューの良し悪しよりさらに精度の高いレコメンド機能を作れるんじゃないかと思い、このアプリを作ろうと思いました。
作りたいアプリはこんな感じなんですが、まだまだ初心者。まずはその第一段階として、VGG16の転移学習で、”ラーメンの識別”の機能を持ったアプリを制作しようと思います。
[環境]
・macOS Big Sur 11.1 (Apple M1)
・Python 3.7.9
・Tensorflow 2.4.1
・google colaboratory
[アプリ制作の流れ]
1. 画像収集
スクレイピングでラーメンの画像を集めようとしていたところ、以下のデータセットを発見しました。
Food-101 – Mining Discriminative Components with Random Forests
https://data.vision.ee.ethz.ch/cvl/datasets_extra/food-101/
101種類の料理画像が各1000枚まとめられた超ありがたいデータセットです。
この中から今回は”ラーメン”の画像の他に、ラーメン屋さんにありそうな”ギョーザ”と”チャーハン”を各1000枚、計3000枚を使ってみます。データはGoogleドライブに保存しました。
2. ファイル名の変更
このデータセットはファイル名の数字がバラバラなので、番号を揃えます。
まずはGoogleColaboratoryでGoogleドライブのデータを扱えるようにしなければいけません。以下をGoogleColaboratory上で実行し、Googleドライブをマウントします。
from google.colab import drive
drive.mount('/content/drive')マウント出来たら、以下でファイル名を連番に置き換えます。(チャーハンって英語で"Fried rice"っていうんだ…。)
import os
import glob
categories = ['/ramen', '/gyoza', '/fried_rice']
path = '/content/drive/MyDrive'
for category in categories:
pathes = path + category
files = glob.glob(pathes +'/*.jpg')
for i, f in enumerate(files):
os.rename(f, os.path.join(pathes, '{}'.format(i) + ".jpg"))3. 学習
3.1 モデル定義、学習
続いて、ラーメン、ギョーザ、チャーハンの3分類のモデルを作成していきます。
今回はVGG16を使って転移学習します。VGG16は256層の全結合モデルと結合します。Flaskでアプリを作る際使用するため、モデルの保存も行います。
学習を行う際はGoogle Colaboratoryのランタイムのタイプを「GPU」に変更して行うことで短時間で学習することが出来ます。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from google.colab import files
from keras.utils.np_utils import to_categorical
from keras.layers import Dense, Dropout, Flatten, Input, BatchNormalization
from keras.applications.vgg16 import VGG16
from keras.models import Model, Sequential
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import keras.callbacks
nums = np.arange(100)
img_ramen = []
img_gyoza = []
img_fried_rice = []
for num in nums:
img = cv2.imread('/content/drive/MyDrive/ramen/' + str(num) + '.jpg')
img = cv2.resize(img, (70,70))
img_ramen.append(img)
for num in nums:
img = cv2.imread('/content/drive/MyDrive/gyoza/'+ str(num) + '.jpg')
img = cv2.resize(img, (70,70))
img_gyoza.append(img)
for num in nums:
img = cv2.imread('/content/drive/MyDrive/fried_rice/' + str(num) + '.jpg')
img = cv2.resize(img, (70,70))
img_fried_rice.append(img)
X = np.array(img_ramen + img_gyoza + img_fried_rice)
y = np.array([0]*len(img_ramen) + [1]*len(img_gyoza) + [2]*len(img_fried_rice))
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
y_train = to_categorical(y_train, 3)
y_test = to_categorical(y_test, 3)
input_tensor = Input(shape=(70, 70, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
model = Sequential()
model.add(Flatten(input_shape=vgg16.output_shape[1:]))
model.add(Dense(256, activation='relu'))#
model.add(BatchNormalization())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(BatchNormalization())
model.add(Dense(3, activation='softmax'))
model = Model(inputs=vgg16.input, outputs=model(vgg16.output))
for layer in model.layers[:15]:
layer.trainable=False
# コンパイル
model.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(lr=1e-4, momentum=0.9), metrics=['accuracy'])
# モデルの構造を出力
model.summary()
# 学習
history = model.fit(X_train, y_train, batch_size=30, epochs=40, verbose=1, validation_data=(X_test, y_test))
#resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
model.save(os.path.join(result_dir, 'model.h5'))
files.download( '/content/results/model.h5' )
# 汎化制度の評価・表示
score = model.evaluate(X_test, y_test, batch_size=30, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
#accuracyとval_accaccuracyのプロット
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()ちなみにこの時、当初は以下のimport文としていたのですが、後述のmain.pyで実行した際、エラーが発生していました。kerasは数年前にtensorflowに吸収されてしまったので、この辺りのライブラリの依存関係が複雑になっており、必要とされているバージョン合わせなど、エラー解消にかなりの時間を要しました。
from keras.utils.np_utils import to_categorical
from keras.layers import Dense, Dropout, Flatten, Input, BatchNormalization
from keras.applications.vgg16 import VGG16
from keras.models import Model, Sequential
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import keras.callbacks3.2 学習結果
トレインデータの正解率(accuracy)、テストデータの正解率(val_accuracy)の学習結果が以下です。
・トレインデータの正解率(accuracy):0.99
・テストデータの正解率(val_accuracy):0.87
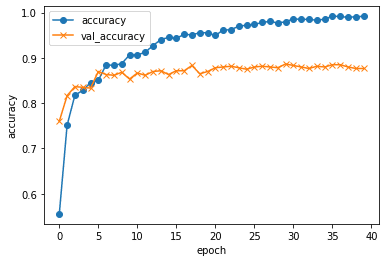
今回は正解率90%を超えることが出来ませんでしたが、第一歩としてはまぁまぁの正解率になったかと思います。更に正解率を高めるには、画像の水増しや、Inception-v3などVGG16以外の学習済みモデルの転移学習も試してみるといいかも知れません。
4. Flaskでアプリ作成
さて次は、Flaskでアプリにしていきます。以下のような建て付けでファイルを用意します。
ramen_app(フォルダ)
⇨main.py
⇨model.h5(保存した学習モデル)
⇨Procfile
⇨requirements.txt
⇨runtime.txt
⇨static(フォルダ)
⇨⇨stylesheet.css
⇨templates(フォルダ)
⇨⇨index.html
main.pyのコードは以下。アップロードされた画像を学習済みモデルに渡して分類結果を返します。
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow import keras
from tensorflow.keras.models import Sequential, load_model, Model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["これはラーメンです","これはラーメンではありません(ギョーザ?)","これはラーメンではありません(チャーハン?)"]
image_size = 70
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5')
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
img = image.load_img(filepath, grayscale=False, target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = classes[predicted]
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)index.htmlは以下。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>Ramen Classifier</title>
<link rel="stylesheet" href="./static/stylesheet.css" />
</head>
<body>
<header>
<img
class="header_img"
src="https://aidemy.net/logo-white.8748c46e.svg"
alt="Aidemy"
/>
<a class="header-logo" href="#">RamenAI</a>
</header>
<div class="main">
<h2>RamenAIが送信された料理画像がラーメンかどうかを識別します</h2>
<p>画像を送信してください</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file" />
<input class="btn" value="submit!" type="submit" />
</form>
<div class="answer">{{answer}}</div>
</div>
<footer>
<img
class="footer_img"
src="https://aidemy.net/static/media/logo.eb4d1a66.svg"
alt="Aidemy"
/>
<small>© 2021</small>
</footer>
</body>
</html>stylesheet.cssは以下。
header {
background-color: #76B55B;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: #fff;
font-size: 25px;
margin: 15px 25px;
}
.header_img {
height: 25px;
margin: 15px 25px;
}
.main {
height: 370px;
}
h2 {
color: #444444;
margin: 90px 0px;
text-align: center;
}
p {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}
footer {
background-color: #F7F7F7;
height: 110px;
margin: -8px;
position: relative;
}
.footer_img {
height: 25px;
margin: 15px 25px;
}
small {
margin: 15px 25px;
position: absolute;
left: 0;
bottom: 0;
}ページの外観はこのようになっています。改善の余地が多分にありますが、今回はとりあえず最低限のデザインでOKとしました。

これらをherokuにデプロイすれば準備完了です。
[実際にやってみる]
さて、それではアプリを実際に動かしてみます。『ファイルを選択』から画像を選択して、『Submit!』を押します。まずは僕が大好きなラーメン、龍上海『赤湯辛味噌ラーメン』の画像を渡してみます。(このラーメン、新横のラー博で食べられます。)

以下が結果です。問題なくラーメンだと認識してくれました。

次に、ギョーザ画像、チャーハン画像をそれぞれ渡してみます。


以下が結果です。それぞれしっかり認識してくれています。安心しました。


最後に料理ではなく全然関係のない車の画像を渡してみます。

結果がこちら。

AIさん、デロリアンをラーメンだと思っちゃってます。これは今後の課題ですが、料理以外を料理ではないと認識できるようにしたいです。(もしくはピンポイントにラーメン画像のみをピックアップできるようにしたい)
[おわりに]
未経験の初心者が一応アプリを作成することが出来ました。まだまだ追加・改良しないといけないことが山盛りですが、コツコツ勉強して楽しみながらやっていこうと思います。おわり。(このアプリ作ってると腹減る〜)
この記事が気に入ったらサポートをしてみませんか?