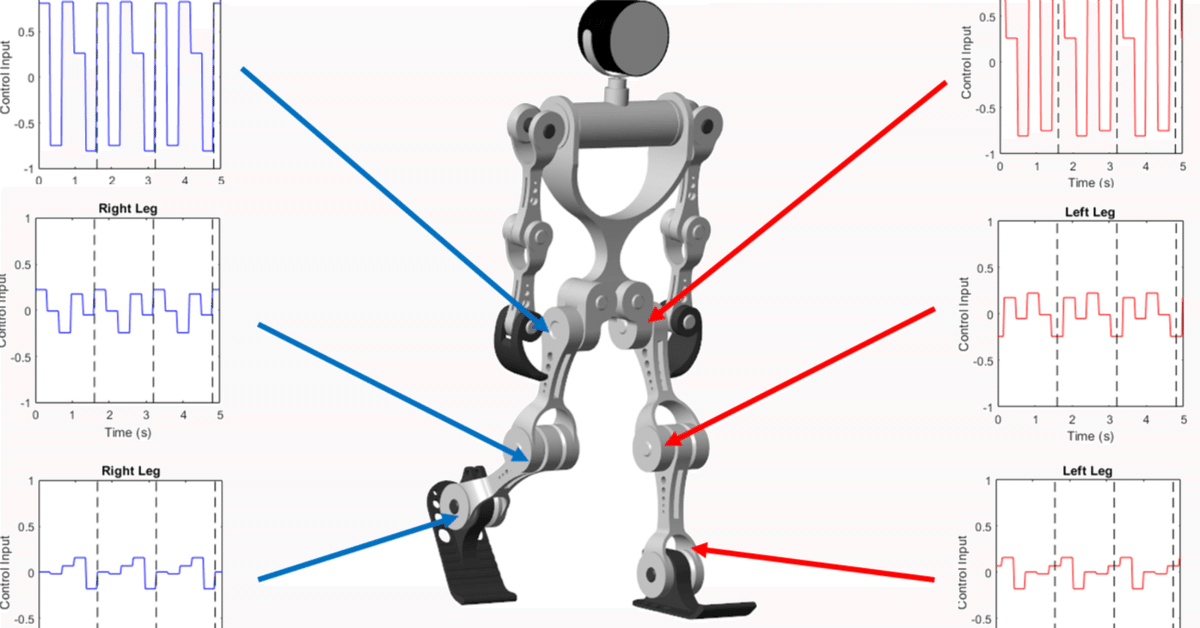
ロボットをシミュレーション上で歩かせるには

Nvidia OpenUSDでヒューマノイドを物理シミュレーションの世界に置くとすぐに顔を伏せ倒れてしまった。
ボストン・ダイナミクスやテスラのヒューマノイドはトリッキーな動作をする。
Nvidiaはシミュレーション環境を提供し、強化学習するプラットフォームを提供している。
4096体のコピーが作られ同時にトレーニングされる。
養鶏場のようなに見えるのがトレーニング中のヒューマノイドの環境だ。
最初は、このかわいそうなロボットはどう動けばいいのかまったくわからないので、各関節にランダムな力をかけ、結果は4096体のロボットがありとあらゆる方法で倒れている。
最初の報酬関数は、体の高さをチェックすることで床に倒れた個体を検出する、
倒れると最初の状態にリスタートさせる。定期的にビューポートを開き、このロボットがどうなっているかをチェックする。転倒検知のしきい値を調整し、訓練を再開させる。さらに5分後......彼らのほとんどは立っている。
ロボットがシミュレーション上で安定して歩けるようにするには、単に高さを保つだけでなく、より複雑な報酬関数を設計する必要がある。
姿勢の安定性
重心の位置
重心が支持多角形内にあるときに正の報酬を与える
重心が支持多角形から外れるほど負の報酬を増やす
体幹の傾き体幹が垂直に近いほど高い報酬を与える
傾きが大きくなるほど報酬を減少させる
歩行の効率性
前進速度
目標速度に近づくほど高い報酬を与える
目標速度から離れるほど報酬を減少させる
エネルギー効率関節トルクの二乗和を最小化するような報酬を設計する
過剰な動きや振動を抑制するため
自然な動作
周期性
左右の脚の動きが交互に行われるよう報酬を設計する
歩行の周期性を維持するための報酬を与える
関節角度の制限関節が生物学的に妥当な範囲内にあるときに報酬を与える
極端な関節角度に対しては負の報酬を与える
転倒防止
足の接地
少なくとも一方の足が地面に接地しているときに報酬を与える
両足が同時に地面から離れた場合に負の報酬を与える
頭部の高さ頭部が一定の高さ以上を維持しているときに報酬を与える
頭部の高さが急激に低下した場合に負の報酬を与える
Q:ヒューマノイドロボットの歩行を最適化する、複数の要素を考慮した総合的な報酬関数の発見と数値は人力ですか? Nvidia simulation labは人間が操作することなく自分で報酬関数を見つけ、数値をセットすることができますか?
Nvidia Isaac Simのような高度なシミュレーション環境では、完全に自動化された報酬関数の発見と最適化が可能です。以下にその仕組みと特徴を説明します:
自動報酬関数設計
メタ学習アプローチ
シミュレーション環境自体が報酬関数の構造と重みを学習する
人間が設計した初期の報酬関数をベースに、より効果的な関数を自動生成する
進化的アルゴリズム複数の報酬関数候補を生成し、それぞれの性能を評価
優れた結果を示した関数を組み合わせて新しい候補を作成する
自動パラメータ調整
ベイズ最適化
報酬関数のパラメータを自動的に調整し、最適な値を探索する
少ない試行回数で効率的に最適なパラメータを見つけ出す
グリッドサーチと勾配法の組み合わせ広範囲のパラメータ空間を探索し、局所的な最適化を行う
大域的な最適解を効率的に発見する
自己進化型アーキテクチャ
階層的強化学習
低レベルの制御から高レベルの行動計画まで、複数の層で学習を行う
各層が自動的に最適な報酬関数を発見し、調整する
カリキュラム学習簡単なタスクから徐々に難しいタスクへと学習を進める
報酬関数も段階的に複雑化し、最終的な目標に向けて自動調整される
Nvidia Isaac Simのような先進的なプラットフォームでは、これらの技術を組み合わせることで、人間の介入なしに報酬関数の設計と最適化を行うことが可能です。システムは膨大な試行錯誤を通じて、最も効果的な報酬関数とそのパラメータを自動的に発見し、調整していきます。
ただし、完全に自動化されたプロセスであっても、初期設定や大まかな目標設定には人間の専門知識が必要となる場合があります。また、生成された報酬関数の解釈可能性や、意図しない副作用の防止などの課題も残されています。
Isaac Sim上で報酬関数を実装するためのPythonコードの概略は以下のようになります:
import omni.isaac.core.utils.torch as torch_utils
from omni.isaac.core.articulations import ArticulationView
from omni.isaac.core.utils.viewports import set_camera_view
class HumanoidReward:
def __init__(self, robot: ArticulationView, dt, max_episode_length):
self.robot = robot
self.dt = dt
self.max_episode_length = max_episode_length
self.reset()
def reset(self):
self.episode_length = 0
self.last_base_pos = None
def compute(self):
self.episode_length += 1
base_pos, base_rot = self.robot.get_world_pose()
reward = 0.0
# 姿勢の安定性
reward += self._stability_reward(base_pos, base_rot)
# 歩行の効率性
reward += self._efficiency_reward(base_pos)
# 自然な動作
reward += self._natural_motion_reward()
# 転倒防止
reward += self._fall_prevention_reward(base_pos)
done = self.episode_length > self.max_episode_length
self.last_base_pos = base_pos
return reward, done
def _stability_reward(self, base_pos, base_rot):
reward = 0.0
# 重心位置の報酬
support_polygon = self._get_support_polygon()
com = self._get_center_of_mass()
if self._is_point_in_polygon(com, support_polygon):
reward += 1.0
else:
distance = self._distance_to_polygon(com, support_polygon)
reward -= distance
# 体幹の傾き報酬
up_vec = torch_utils.quat_rotate(base_rot, torch.tensor([0, 0, 1]))
tilt_angle = torch.acos(torch.dot(up_vec, torch.tensor([0, 0, 1])))
reward += 1.0 - tilt_angle / (0.5 * torch.pi)
return reward
def _efficiency_reward(self, base_pos):
reward = 0.0
if self.last_base_pos is not None:
# 前進速度の報酬
velocity = (base_pos - self.last_base_pos) / self.dt
target_velocity = torch.tensor([0.5, 0, 0]) # 目標速度を設定
velocity_diff = torch.norm(velocity - target_velocity)
reward += torch.exp(-velocity_diff)
# エネルギー効率の報酬
joint_torques = self.robot.get_joint_torques()
energy = torch.sum(joint_torques ** 2)
reward -= 0.001 * energy # エネルギーに対するペナルティ
return reward
def _natural_motion_reward(self):
reward = 0.0
# 周期性の報酬
left_leg_phase = self._get_leg_phase("left")
right_leg_phase = self._get_leg_phase("right")
phase_diff = torch.abs(left_leg_phase - right_leg_phase)
reward += torch.exp(-(phase_diff - torch.pi) ** 2)
# 関節角度の制限報酬
joint_positions = self.robot.get_joint_positions()
joint_limits = self.robot.get_joint_limits()
for pos, (lower, upper) in zip(joint_positions, joint_limits):
if lower <= pos <= upper:
reward += 0.1
else:
reward -= 0.1
return reward
def _fall_prevention_reward(self, base_pos):
reward = 0.0
# 足の接地報酬
left_foot_contact = self._is_foot_in_contact("left")
right_foot_contact = self._is_foot_in_contact("right")
if left_foot_contact or right_foot_contact:
reward += 1.0
else:
reward -= 1.0
# 頭部の高さ報酬
head_height = self._get_head_height()
min_height = 1.0 # 最小許容高さ
if head_height > min_height:
reward += 1.0
else:
reward -= (min_height - head_height) ** 2
return reward
# ヘルパー関数(実装は省略)
def _get_support_polygon(self):
pass
def _get_center_of_mass(self):
pass
def _is_point_in_polygon(self, point, polygon):
pass
def _distance_to_polygon(self, point, polygon):
pass
def _get_leg_phase(self, side):
pass
def _is_foot_in_contact(self, side):
pass
def _get_head_height(self):
pass
# 使用例
robot = ArticulationView(prim_paths_expr="/World/robot")
reward_function = HumanoidReward(robot, dt=0.01, max_episode_length=1000)
# シミュレーションループ内で使用
for _ in range(1000):
# アクションの適用など
reward, done = reward_function.compute()
if done:
reward_function.reset()
break具体的なロボットモデルに合わせて関数を調整する必要があります。
パラメータ(重み、閾値など)は実験的に調整する必要があります。
3.関数(例:`_get_support_polygon`)は、ロボットの具体的な構造に基づいて実装する。
Citations:
[1] https://note.com/kawamura_akihiro/n/n1b966c39f624
この記事が気に入ったらサポートをしてみませんか?