
【2020年12月版】noteの非公式APIを使ってユーザーの"全記事データ”を取得してみる※pythonコード有り

note非公式APIは「v1」から「v2」へ
前回2020年の2月時点にも書いた「note非公式APIを用いて全記事データを取得する方法」ですが、2020/12/30の現時点において「v1」APIは廃止されておりもはや使えなくなっています。
そして代わりに「v2」APIが使えるようになっています。
そこで今回は「v2」APIを使って、ユーザーの"全記事データ”を取得するpythonコードについて検証していきたいと思います
現在のAPI
ユーザー情報を取得するAPI URL
https://note.com/api/v2/creators/user_nameuser_nameの部分に取得したいユーザー名を入れます
例としては以下のようになります
# 例:note公式の情報を取得
https://note.com/api/v2/creators/infoなお上記のURLで返ってくるのはjson形式のデータなのでwebブラウザで開くとこの様に見えます

これでは読み取るのも一苦労なので、次はpythonを用いてこれを展開していきます
ユーザー情報をPythonで取得する
前述のAPI URLをpythonのrequestsで取得し、pandasのデータフレームにそのまま投入するとこの様になります
# ユーザー情報取得
import requests
import pandas as pd
import json
user_name="info"
user_api_url="https://note.com/api/v2/creators/%s"%user_name
res = requests.get(user_api_url).content
df = pd.read_json(res)
display(df)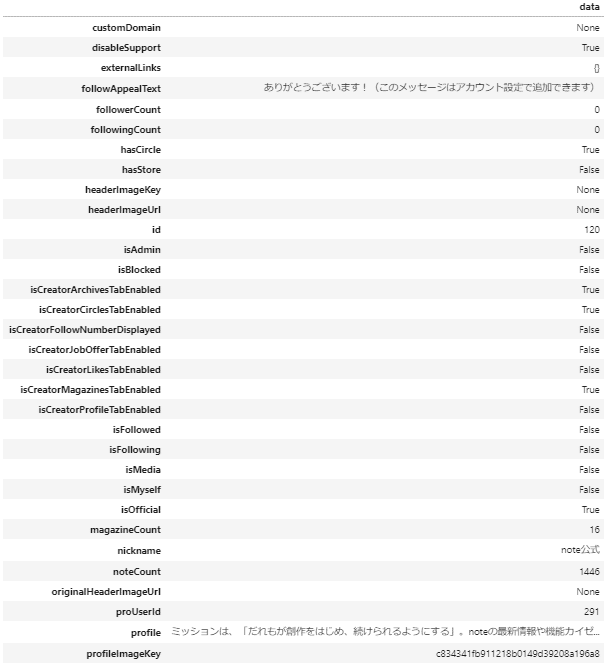
取得できた項目一覧
customDomain
disableSupport
externalLinks
followAppealText
followerCount
followingCount
hasCircle
hasStore
headerImageKey
headerImageUrl
id
isAdmin
isBlocked
isCreatorArchivesTabEnabled
isCreatorCirclesTabEnabled
isCreatorFollowNumberDisplayed
isCreatorJobOfferTabEnabled
isCreatorLikesTabEnabled
isCreatorMagazinesTabEnabled
isCreatorProfileTabEnabled
isFollowed
isFollowing
isMedia
isMyself
isOfficial
magazineCount
nickname
noteCount
originalHeaderImageUrl
proUserId
profile
profileImageKey
profileImageUrl
showFollowCount
socials
style
tlMagazines
urlname
フォロー数・フォロアー数・記事数などの情報を取得することが出来ました。
このAPIを使えばnoteユーザーの大体の情報を簡単に得ることが出来そうです(なおこのAPIは公式に公開されているものではないらしいことにご注意ください)
ユーザーの記事一覧取得
次に「記事」について情報を取得してみたいと思います。
記事に関するAPI URLは以下の様です
https://note.com/api/v2/creators/user_name/contentsuser_nameの部分を参照したいユーザー名に書き換えます
ユーザーの記事一覧を取得するpythonコード
# 記事情報取得
import requests
import pandas as pd
import json
user_name="info"
contents_api_url="https://note.com/api/v2/creators/%s/contents"%user_name
payload = {'kind':'note'}
res = requests.get(contents_api_url, params=payload).content
df = pd.read_json(res)
display(df)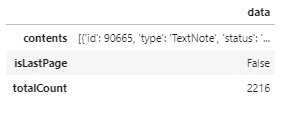
返ってきたデータはこれだけでした。どうやら個々の記事に関するデータは「contents」行にまとめて収納されているみたいです。
そこで次はこれを展開し、見やすいようにエクセルファイル化したいと思います。
検証用pythonコード:個々の記事のデータの展開
# 記事情報取得
import requests
import pandas as pd
import json
user_name="info"
contents_api_url="https://note.com/api/v2/creators/%s/contents"%user_name
payload = {'kind':'note'}
res = requests.get(contents_api_url, params=payload).content
df = pd.read_json(res)
df2 = pd.DataFrame()
# notes行だけを抽出
df_notes = df["data"]["contents"]
# 展開して新しいデータフレームに行として追加していく
for i in range(len(df_notes)):
df_n = pd.DataFrame(df_notes[i].values(), index=df_notes[i].keys()).T
df2 = pd.concat([df2, df_n])
display(df2)
# 結果をエクセルファイルで保存
df2.to_excel('notes.xlsx')結果

取得できたカラム名一覧
id
type
status
name
description
price
key
slug
publishAt
thumbnailExternalUrl
eyecatch
user
canRead
isAuthor
externalUrl
customDomain
body
separator
isLimited
isTrial
canUpdate
tweetText
additionalAttr
isRefund
commentCount
likes
likeCount
anonymousLikeCount
isLiked
disableComment
hashtags
twitterShareUrl
facebookShareUrl
lineShareUrl
audio
pictures
limitedMessage
labels
priorSale
canMultipleLimitedNote
hasEmbeddedContent
isPinned
pinnedUserNoteId
isTreasuredNote
spEyecatch
enableBacktoDraft
notificationMessages
isProfiled
isForWork
isCircleDescription
noteDraft
noteUrl
記事に関するデータはタイトル(name列)から本文(body列)含め、ほぼ全て取得できるようです。
しかし1回のリクエストで取得できる記事数は6記事までとなっている様です。
ただし「page」のクエリを追加することで、どの部分から6記事分取得するかは変えられる様です。
そこで今回は最後にユーザー情報にある総記事数のデータである「noteCount」を用いて、指定したユーザーの記事を全て取得してみたいと思います。
禁断のユーザー記事全件取得に挑む
# ユーザー記事データ全件取得
import requests
import pandas as pd
import json
import time
from tqdm import tqdm
# 取得したいユーザー名
user_name="info"
# API URL
user_api_url="https://note.com/api/v2/creators/%s"%user_name
contents_api_url="https://note.com/api/v2/creators/%s/contents"%user_name
# 取得秒数間隔の指定
interval = 1
# 総記事件数の取得
res = requests.get(user_api_url).content
df = pd.read_json(res)
note_count = df['data']['noteCount']
# 総取得ページ数
page_num = (note_count//6) + 1
# 個別ページの取得
df2 = pd.DataFrame()
for page in tqdm(range(page_num)):
page = page+1
payload = {'kind':'note','page':page}
res = requests.get(contents_api_url, params=payload).content
df = pd.read_json(res)
df_notes = df["data"]["contents"]
for i in range(len(df_notes)):
df_n = pd.DataFrame(df_notes[i].values(), index=df_notes[i].keys()).T
df2 = pd.concat([df2, df_n])
time.sleep(interval)
# 重複行を削除する
df2.drop_duplicates(subset='noteUrl', inplace=True)
# 投稿日順に並び替え
df2 = df2.sort_values('publishAt', ascending=False)
# インデックスの振り直し
df2 = df2.reset_index(drop=True)
# エクセルファイルとして保存
df2.to_excel('notes_all.xlsx')結果:成功!

ユーザーが公開している全記事のデータを取得することに無事成功しました!
おわりに
前回の記事を改稿する形で現行のnote非公式API「v2」を用いて、ユーザー情報やユーザー全記事データを取得することを試みました。
「v1」から「v2」で仕様が変わった部分も多少ありましたが引き続きnote 非公式APIは使用できるみたいです。
おまけ

2020/12/30時点におけるnote公式アカウントの「スキ」の数が多い記事トップ10
!!注意!!
なおnoteのAPIは公式に公開されているものでは無いらしいのでご注意ください
よろしければサポートお願いします。サポート? サポート……、サポート!よろしくおねがいします!?