
※重要:古い記事です:noteの非公式APIを使ってユーザーの"全記事データ”を取得してみる

!!重要!!
この記事の内容はもはや古いです。2020/12/30時点でこの記事を書いた当初使えていた「v1」APIは使用できなくなっていますのでご注意ください
「v2」を用いた新しい記事は以下になります
以下、古いバージョンの記事になります
現在noteでは公式なAPIは公開されていない様ですが、「note API」でweb検索するといくつか情報がヒットします。
そこで今回はその中から実際に情報が正しいのか、2020年2月の現時点でも使えるのか検証してみたいと思います。
非公式APIを検証
まず「ユーザー情報」を参照するAPIを試してみたいと思います。参考にしたの以下のページです。
https://note.mu/api/v1/users/*APIのURLがnote.comになる以前のnote.muとなっていますが、comでもmuでも現状は変わりなく使えるようみたいです
検証用pythonコード:ユーザー情報
# ユーザー情報取得
import requests
import pandas as pd
import json
api_url="https://note.mu/api/v1/users/"
urlname="info"
payload = {'urlname':urlname}
res = requests.get(api_url, params=payload).content
# jsonをPandasデータフレーム化
df = pd.read_json(res)
display(df)「urlname=""」の部分で対象とするユーザーID名をしています。
またAPIから返ってくるデータはjson形式となっていますが、ここでは扱いやすい様にPandasのデータフレームに直接変換しています。
結果

取得できた項目一覧
authentications
custom_domain
draft_count
follower_count
following_count
id
is_blocked
is_following
is_me
is_official
magazine_count
nickname
no_urlname_user
note_count
point_balance
profile
tokusyo_contact
tokusyo_name
tweet_text
urlname
user_profile_image_path
user_wallpaper_image_path
フォロー数・フォロアー数・記事数、下書き数などの情報を取得することが出来ました。
このAPIを使えばnoteユーザーの大体の情報を簡単に得ることが出来そうです(なおこのAPIは公式に公開されているものではないらしいことにご注意ください)
ユーザーの記事一覧取得
次に「記事」について情報を取得してみたいと思います。参考にしたのは以下のページです。
今回は上記のページで紹介されている
https://note.com/api/v1/notes/を試してみます。
検証用pythonコード:ユーザー記事一覧
# 記事情報取得
import requests
import pandas as pd
import json
api_url="https://note.com/api/v1/notes/"
urlname="info"
payload = {'urlname':urlname}
res = requests.get(api_url, params=payload).content
df = pd.read_json(res)
display(df)結果
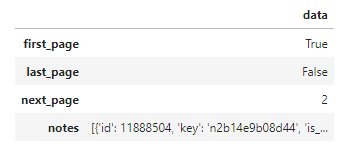
返ってきたデータはこれだけでした。どうやら個々の記事に関するデータは「notes」行にまとめて収納されているみたいです。
そこで次はこれを展開して表示したいと思います。
検証用pythonコード:個々の記事のデータ
# 記事情報取得
import requests
import pandas as pd
import json
api_url="https://note.com/api/v1/notes/"
urlname="info"
payload = {'urlname':urlname}
res = requests.get(api_url, params=payload).content
df = pd.read_json(res)
df2 = pd.DataFrame()
# notes行だけを抽出
df_notes = df["data"]["notes"]
# 展開して新しいデータフレームに行として追加していく
for i in range(len(df_notes)):
df_n = pd.DataFrame(df_notes[i].values(), index=df_notes[i].keys()).T
df2 = pd.concat([df2, df_n])
display(df2)
# 結果をエクセルファイルで保存
df2.to_excel('notes.xlsx')結果
列が多くてpandasでは見にくいのでエクセルで表示したものが以下になります。

取得できたカラム名
id
key
is_treasured_note
body
external_url
type
user_id
name
description
tweet_text
twitter_share_url
facebook_share_url
can_multiple_limited_note
can_sell_on_first_come_note
pictures
embedded_contents
audio
status
publish_at
price
created_at
updated_at
like_count
anonymous_like_count
comment_count
is_limited
is_trial
is_refund
is_my_note
can_read
can_vote
can_comment
is_liked
is_purchased
is_magazine_purchased
is_available
eyecatch
eyecatch_width
eyecatch_height
sp_eyecatch
has_draft
is_draft
is_published
is_reserved
reserved_publish_at
disable_comment
likes
user
comment_viewable
comments
hashtag_notes
has_coupon
prior_sale
custom_domain
editable_scopes
non_editable_reason
記事に関するデータはタイトル(name列)から本文(body列)含め、ほぼ全て取得できるようです。
記事数に関しては、どうやら1回のリクエストで取得できる記事数は10記事までとなっている様です。
ただし「page」のクエリを追加することで、どの部分から10記事分取得するかは変えられる様です。
そこで今回は最後にユーザー情報にある「note_count」を用いて、指定したユーザーの記事を全て取得してみたいと思います。
禁断のユーザー記事全件取得に挑む
# ユーザー記事データ全件取得
import requests
import pandas as pd
import json
import time
from tqdm import tqdm
urlname="info"
# 総記事件数の取得
payload = {'urlname':urlname}
res = requests.get("https://note.mu/api/v1/users/", params=payload).content
df = pd.read_json(res)
note_count = df['data']['note_count']
# 総取得ページ数
page_num = (note_count//10) + 1
# 個別ページの取得
df2 = pd.DataFrame()
for page in tqdm(range(page_num)):
page = page+1
payload = {'urlname':urlname,'page':page}
res = requests.get("https://note.com/api/v1/notes/", params=payload).content
df = pd.read_json(res)
df_notes = df["data"]["notes"]
for i in range(len(df_notes)):
df_n = pd.DataFrame(df_notes[i].values(), index=df_notes[i].keys()).T
df2 = pd.concat([df2, df_n])
time.sleep(3)
# 重複行を削除する
df2.drop_duplicates(subset='id', inplace=True)
df2 = df2.reset_index(drop=True)
# エクセルファイルとして保存
df2.to_excel('notes_all.xlsx')結果:成功!


ユーザーが公開している全記事のデータを取得することに無事成功しました!
おわりに
今回はnoteの非公式APIを使ってユーザー情報やユーザー全記事データを取得することを試みました。
公式には公開されていないnote APIですが、web上にある情報は正しく、2020年2月現在でも使用することが出来るみたいです。
おまけ
ノート公式アカウントの「スキ」の数が多い記事トップ10

注意
なおnoteのAPIは公式に公開されているものでは無いのでご注意ください
よろしければサポートお願いします。サポート? サポート……、サポート!よろしくおねがいします!?