
YOLOの画像認識をサーバーAPIとして実装する

概要
画像認識のYOLOはGPU動作が基本のため、エッジデバイスで推論するのに適さない場合があります
なので、YOLOの画像認識だけをさせるweb api serverを実装しました。その際のメモです。
恐らく、誰かの車輪の再発明です。ChatGPTに聞きながら、ぱぱっと作れました。
用いたYOLOのモデルは以下の通り。
モチベーション
最終的には、画像認識をさせながら実験を行えるロボットアーム系を作りたい
Webカメラのドライバ、利便性等を考えると、とりあえず手持ちのwindowsをインターフェースにするのが便利
しかし、windowsにpythonの深層学習系ライブラリetcを入れるのは面倒
WSLを使うにしても、何だかんだで連携が面倒そう(特にドライバ周り)
GPU系の処理でファンが唸るのがうるさいし、遅延が生じるリスクもある
→→ 重たい処理はワークステーションで通信しながら実装するのが良いという考えに至りました
APIサーバー
GPU(RTX2080)を積んだubuntuで動かします。
画像データを受け取り、YOLOで計算したアノテーションをJSONで返す仕様です。
Recognizerクラスの実装
from ultralytics import YOLO
class Recognizer:
def __init__(self,model_path):
self.model = YOLO(model_path)
self.names = self.model.names
def recognize(self, img,conf=0.3):
preds =self. model.predict(img,conf=conf)
annot_list=[]
for box in preds[0].boxes:
label=self.names[box.cls.cpu().numpy()[0]]
conf=box.conf.cpu().numpy()[0]
xmin, ymin, xmax, ymax=box.xyxy.cpu().numpy()[0]
xmin, ymin, xmax, ymax=int(xmin), int(ymin), int(xmax), int(ymax)
d={
"label":label,
"conf":conf,
"xmin":xmin,
"ymin":ymin,
"xmax":xmax,
"ymax":ymax
}
annot_list.append(d)
return annot_listサーバーの実装
Flaskを使いました。ローカルネットなので、セキュリティ関連は無視します。
from PIL import Image
from flask import Flask, request, Response
import json
from Recognizer import Recognizer
import numpy as np
app = Flask(__name__)
recognizer=Recognizer("models/0707pipette.pt") #YOLOの学習済みモデルのパスを指定
def default(o):
if isinstance(o, np.float32):
return float(o)
raise TypeError
@app.route('/image', methods=['POST'])
def process_image():
file = request.files['image']
image = Image.open(file.stream) # Open the image file
annot_list=recognizer.recognize(image)
json_str= json.dumps(annot_list, default=default)
return Response(response=json_str, status=200, mimetype="application/json")
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0')
サーバーの立ち上げ
python server.py
手持ちのマシンの処理
Webカメラの画像をサーバーに投げて、受け取ったアノテーション情報を重ね書きするだけです。画像はpngにしています。
カメラ周り
import cv2
import numpy as np
import io
import requests
import copy
class Camera:
def __init__(self, camera_id,
server_url="http://192.168.254.73:5000/image",
):
self.camera_id = camera_id
self.server_url = server_url
self.cap = cv2.VideoCapture(self.camera_id)
if not self.cap.isOpened():
raise IOError("Cannot open webcam")
def get_frame(self, buffer=False):
ret, frame = self.cap.read()
if not ret:
raise IOError("Cannot read frame")
if buffer:
frame = self.frame_to_png_buffer(frame)
return frame
def frame_to_png_buffer(self, frame):
is_success, buffer = cv2.imencode(".png", frame)
if not is_success:
raise Exception("Could not encode image")
io_buf = io.BytesIO(buffer)
return io_buf
def get_annotated_image(self):
frame = self.get_frame()
io_buf = self.frame_to_png_buffer(frame)
response = requests.post(self.server_url, files={"image": io_buf})
if response.status_code == 200:
# print("Image successfully sent to server")
pass
else:
print("Failed to send image to server")
annotations = response.json()
annotated_frame = self.draw_annotations(frame, annotations)
return frame, annotated_frame, annotations
def draw_annotations(self, original_img, annotations):
img = copy.deepcopy(original_img)
for annotation in annotations:
xmin = int(annotation["xmin"])
ymin = int(annotation["ymin"])
xmax = int(annotation["xmax"])
ymax = int(annotation["ymax"])
label = annotation["label"]
conf = annotation["conf"]
cv2.rectangle(img, pt1=(xmin, ymin), pt2=(
xmax, ymax), color=(0, 255, 0), thickness=2)
# Add the label
y = ymin - 15 if ymin - 15 > 15 else ymin + 15
cv2.putText(img, label, (xmin, y),
cv2.FONT_HERSHEY_SIMPLEX, 2, (0, 255, 0), 2)
# add confidence
cv2.putText(img, str(conf), (xmin, y+25),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
return img
インターフェース(jupyter)
from Camera import Camera
import matplotlib.pyplot as plt
import cv2
import os
from IPython.display import clear_output
os.environ["OPENCV_VIDEOIO_MSMF_ENABLE_HW_TRANSFORMS"] = "0"
#カメラIDとサーバーのurlを指定
camera_id=1
server_url="http://192.168.***.***:5000/image"
webcam = Camera(camera_id,server_url)
#表示
while True:
frame,annotaded_frame,annotations=webcam.get_annotated_image()
annotaded_frame= cv2.cvtColor(annotaded_frame, cv2.COLOR_BGR2RGB)
clear_output(wait=True)
plt.imshow(annotaded_frame)
plt.axis('off')
plt.show()実行結果
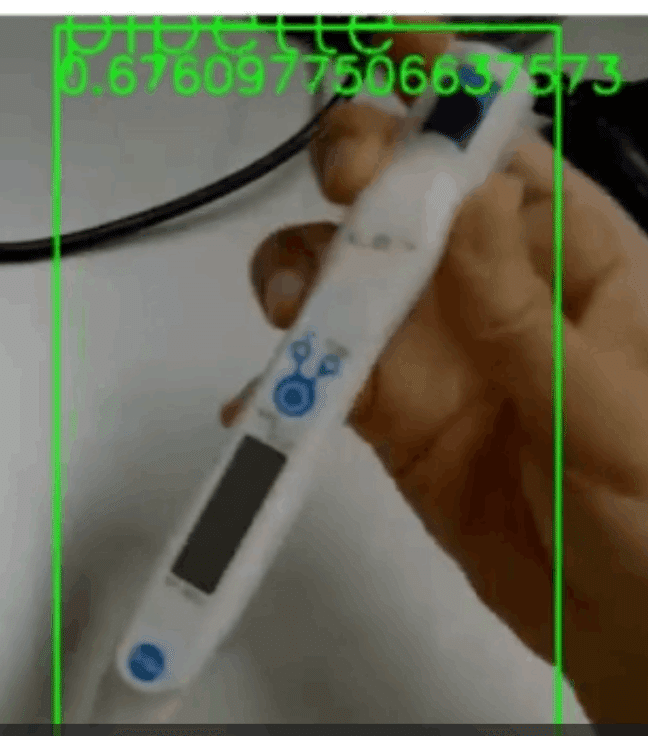
動画はこちら。
ピペット認識 pic.twitter.com/OI9bnrMd2i
— 畠山 歓 Kan Hatakeyama (@kanhatakeyama) July 7, 2023
所感
ちょっとカクカクしてますが、筆者の用途的には、十分な速度でした。
画像認識タスクそのものは10 msくらいで終わってました。
アノテーションデータを相当にいい加減作ったこともあり、ピペットと認識できていないframeがあったりします。
ピペットのチップは全く検出できませんでした。
実際に使うsituation / 光源条件で、学習用データを作る必要がありそうです。
先ほど、深度カメラが届きました。
次週は溜まった諸業務をこなした後、より本格的な物体認識に挑戦したいと思います。
この記事が気に入ったらサポートをしてみませんか?