
YOLOをファインチューニングしてマイクロピペットを認識させる

概要
YOLO v8で自作のデータセットを学習させる際の試行錯誤のメモです
意外とまとまったサンプルコードがなかったので、まとめてみました。
コードはこちら
YOLOとは?
有名な画像認識のライブラリです
23年7月時点では、YOLO-NASが最新のようですが、サンプルコードがあまりなかったので、前世代のv8を使います
SAMも有名です

データセットの作成
画像の準備
ヒトや猫などは、基盤モデルで認識可能ですが、化学実験に使う道具のようなマニアックなものについては、自作のデータセットでfine tuningが必要です
今回はお試しで、マイクロピペットの本体とチップを認識させてみることにしました。
練習として、適当に動画を撮影し、適当なコマを抽出しました。

アノテーション
アノテーションデータを作ります。
ソフトは色々とあるようですが、labelImgという、traditionalなソフトを使ってみます。windowsのexeはこちら。
ソフトを起動後、画像を貯めたフォルダを開きます。
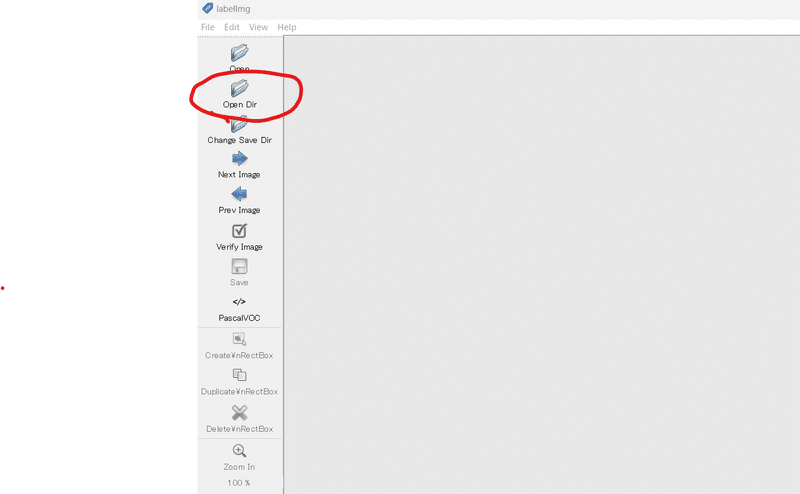
ソフトは直感的で分かり易いです。
create rect boxをクリックして、アノテーションしたい範囲を選択します。その後、ラベルを付けていきます。今回は、pipetteとtipとします。
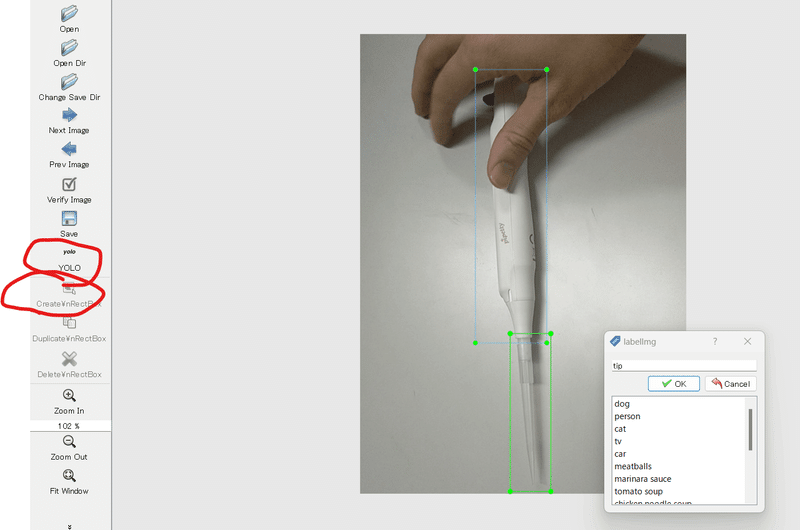
注意
データの出力形式は、YOLOに変更する
Viewタブから、Auto Save modeを選択しておきます。そうすると、next imageなどを押したときに、自動保存されるようです
高速化のコツ
use default labelを設定すると、ボックスを作成したタイミングで、labelが自動入力されます。
その上で、ショートカットキーを使うと、素早く画像を切り替えられます
A、Dで前・次の画像へ移動

以下のようなファイルが作成されるはずです。
読み方の例: 15はラベルID(pipette), それ以降は四角の座標のようです。
※ 今回はpipette, tipのみ学習させるので、それ以外でデフォルトで入っているラベル(ID=0-14, classes.txtに記載)は不要です。が、削除する方法が分かりませんでした。

YOLO用にディレクトリ作成
YOLOの学習用に、ファイルを並べる必要があります。
このあたり、あまり情報が見つからなかったので我流でやりました。ファイル形式は、こちらのレポジトリを参考にしました。
フォルダ構成
original_setフォルダ
data.yaml (データセット情報を記載)
images
1.png
2.png
…
labels
1.txt
2.txt
…
data.yamlはこんな感じにします。
(繰り返しになりますが、dog, personとかは、今回は本来、不要です)
train: ./train/images
val: ./valid/images
test: ./test/images
nc: 17
names: ["dog", "person", "cat", "tv", "car", "meatballs", "marinara sauce", "tomato soup", "chicken noodle soup", "french onion soup", "chicken breast", "ribs", "pulled pork", "hamburger", "cavity", "pipette", "tip"]
以上のようにファイルを配置した後、train,validation, testにデータを分けていきます。この作業は面倒なので、自作のスクリプトを回すことにしました。
(jpgの場合は、コードの書き換えが必要です)
#train,val, testの自動分割
import glob
import os
import random
dataset_dir="orignal_set"
#データ一覧
img_list=glob.glob(os.path.join(dataset_dir+"/labels","*.txt"))
#データをシャッフル
random.shuffle(img_list)
#8:1:1に分割
num_data=len(img_list)
num_train=int(num_data*0.8)
num_val=int(num_data*0.1)
num_test=num_data-num_train-num_val
#分割
split_dict={}
split_dict["train"]=img_list[:num_train]
split_dict["valid"]=img_list[num_train:num_train+num_val]
split_dict["test"]=img_list[num_train+num_val:]
for name in ["train","test","valid"]:
#フォルダ作成
dir_name=os.path.join(dataset_dir,name)
if not os.path.exists(dir_name):
os.mkdir(dir_name)
#images,labelsフォルダ作成
for folder in ["images","labels"]:
dir_name2=os.path.join(dir_name,folder)
if not os.path.exists(dir_name2):
os.mkdir(dir_name2)
#コピー
for path in split_dict[name]:
txt_path=path
img_path=path.replace("labels","images").replace(".txt",".png")
if dir_name2.find("labels")>0:
os.system("cp {} {}".format(txt_path,dir_name2))
else:
os.system("cp {} {}".format(img_path,dir_name2))学習と推論
YOLOはこちらからpipで入れられます。4GBくらいのGPUメモリは合った方が良さそうです。
pip install ultralytics学習
YOLOをimportし、trainするだけOKです。
epochは100くらいあった方が良い気がしました。validationで自動的に、bestなモデルが保存される仕組みになっています。
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
model.train(data="*******/orignal_set/data.yaml", epochs=300) # train the model
metrics = model.val() # evaluate model performance on the validation setruns/detect/train 的なフォルダが自動生成され、学習の様子やモデルが自動保存されます。
推論
ネット上には、アノテーションした画像ファイルを自動生成するサンプルコードが沢山落ちていました。
ただ、実際はlabelと座標をpython上で取得したいケースが大半だと思います。良いコードが見つからなかったので、試行錯誤してコードを生成しました。
model = YOLO("runs/detect/train/weights/best.pt") #学習したmodelを読み込み
#適当に推論&表示
import cv2
import glob
import matplotlib.pyplot as plt
path_list=glob.glob("dataset/orignal_set/test/images/*.png")
names=model.names
for path in path_list:
path=path_list[0]
img=cv2.imread(path)
preds = model.predict(img,conf=0.1)
for box in preds[0].boxes:
label=names[box.cls.cpu().numpy()[0]]
conf=box.conf.cpu().numpy()[0]
xmin, ymin, xmax, ymax=box.xyxy.cpu().numpy()[0]
xmin, ymin, xmax, ymax=int(xmin), int(ymin), int(xmax), int(ymax)
# Create the rectangle (bounding box)
cv2.rectangle(img, pt1=(xmin, ymin), pt2=(xmax, ymax), color=(0, 255, 0), thickness=2)
# Add the label
y = ymin - 15 if ymin - 15 > 15 else ymin + 15
cv2.putText(img, label, (xmin, y), cv2.FONT_HERSHEY_SIMPLEX, 2, (0, 255, 0), 2)
cv2.putText(img, str(conf), (xmin, y+25), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
#imgを表示
plt.figure()
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()
testデータについても、無事に予測できました。精度も悪くなさそうです。

この記事が気に入ったらサポートをしてみませんか?