
WebスクレイピングをPythonで体験してみた('ω') データ取得&グラフ化。

今日は、PythonでWebスクレイピングを体験してみようと思います。
●ブラウザの自動起動
●ネット上からデータを取得
●グラフ化
これらを全てPyhtonで行いまして・・・・・

こんなグラフを書こうよというお話です。
Webスクレイピング見習いの僕は2日程度しか勉強をしていないので超簡単な事しかできませんが、見てやってください_(._.)_
やること(やってみたこと)
やってみたのは、↓こちらにあるサイトの・・・・
↓以下のデータを取得&グラフ化をPythonで行いました('ω')
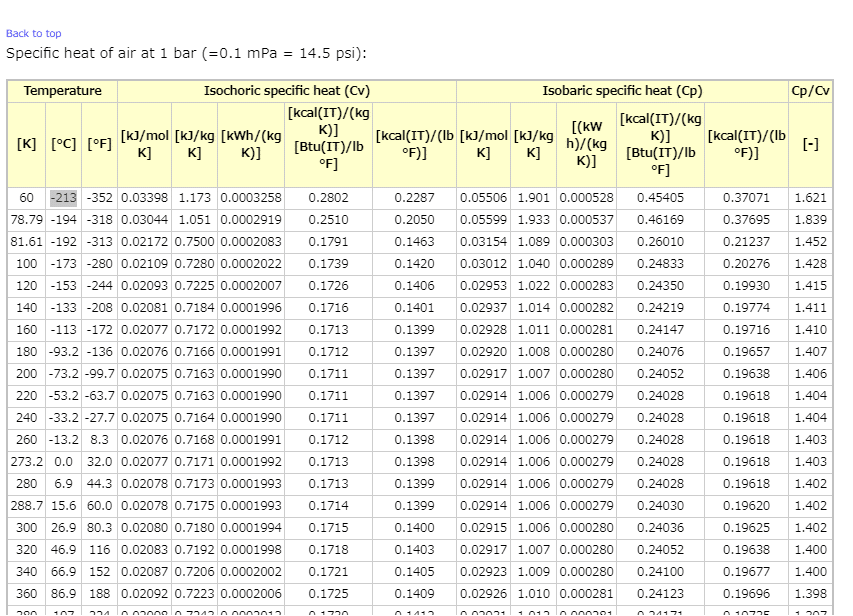
こんな感じでデータがあるわけです。
こちらにあるデータを取得してグラフ化したり分析したりしたいと思います。
【使用環境】
●Python:Google Colaboratoryで使用
●selenium 3.141.0
●Google Chrom:バージョン: 79.0.3945.130(Official Build) (64 ビット)
どうやってWebスクレイピングを勉強したか?
勉強したのは「Udemy」のオンライン講座のみです。
セールのタイミングで講座を購入したので1200円くらいで受講することができました。
とってもわかりやすかったので、2日くらいで受講し終えた、とってもド素人が・・・今、記事を書いています('ω')
では、早速やっていきましょう(^^)/
【全体の流れ】
1.HTMLの構造を理解する
2.ブラウザを起動
3.要素の取得
4.各要素のデータを取得その1
5.各要素のデータを取得その1
6.Padas形式でまとめる
7.データをリスト型に変換
8.データをグラフ化する
1.HTMLの構造を理解する
まずはサイトの構造を理解するところから始めます。
サイト自体はHTMLで書かれているので、その構造を上手く利用することでデータを取得できます。
「右クリック」→「検証」を押して、データがあるクラスやタグを確認します。



ふむふむ・・・( ..)φメモメモ
以下のような構造になっていることがわかりました。

HTMLの構造が理解出来たら、これらの要素を上手くPythonで取得していく必要があります。
2.ブラウザを起動
自動でブラウザを起動するところもやってみましょう(^^)/
Google Colaboratoryの場合は少し特殊で以下のコマンドを打つ必要があります。
(Google Colavoratory上で実行します)
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin詳しくは↓こちらに記載してありました。
Google Colaboratoryでブラウザが起動しなくて、エラー対策は以下の記事を参考にしました。
ここからが本題のPythonのコードとなります。
from selenium import webdriver
from time import sleep
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
#ブラウザの起動
#url = 'https://www.engineeringtoolbox.com/air-properties-d_156.html'
url = 'https://www.engineeringtoolbox.com/air-specific-heat-capacity-d_705.html'
browser = webdriver.Chrome('chromedriver',options=options)
browser.get(url)
# URLを確認する
print(browser.current_url) これでブラウザが起動するのですが、めっちゃくちゃ苦労しました。
3.要素の取得
では、ブラウザが起動したら要素の取得を行っていきます。

●まずはクラス「x-large」を探してきます。

elem_table = browser.find_element_by_class_name('x-large')●次に、「tbodyタグ」を探してきます。

elem =elem_table.find_element_by_tag_name('tbody')●その次が、ややこしいですが「trタグ」の中の「tdタグ」を探してきます。

elems_tr = elem.find_elements_by_tag_name('tr')
elems_td = elems_tr[0].find_elements_by_tag_name('td')
print(elems_td[0].text)
print(elems_td[1].text)
【結果】
60
-213こんな感じで、tdタグは複数あるので、elems_tr[0]の中の、elems_td[0]と書くことで、60という値を取得できます。
4.各要素のデータを取得その1
●「trタグ」の中の「tdタグ」の値をfor文で探し出します。

lists = []
for elem in elems:
lists.append(elem.text)
datas.append(lists)
datas5.各要素のデータを取得その2
●「trタグ」もfor文で繰り返します。

datas = []
for elem_tr in elems_tr:
elems = elem_tr.find_elements_by_tag_name('td')
lists = []
for elem in elems:
lists.append(elem.text)
datas.append(lists)
datasこれでデータの取得が終わりました('ω')

やったー(^^)/
6.Padas形式でまとめる
取り出せたデータの取り扱いは、Pythonのライブラリの中のPandasがめちゃくちゃ便利ですよね!(^^)!
import pandas as pd
df = pd.DataFrame(datas)
df
これでデータが表になりました。
ほとんどサイト内のデータ一覧の見た目が同じですね(^^)/
7.データをリスト型に変換
ここまでできたら、データをグラフ化するだけです。
今回は、「0列目:温度」と「9列目:定圧比熱Cp」の値を取り出してみましょう。
import numpy as np
temp_ = df.iloc[:,0]
cp_ =df.iloc[:,9]
temp = np.array([float(u) for u in temp_])
cp = np.array([float(u) for u in cp_])floatとしているのは、取り出したデータが文字列となっていたので数値に変換する目的で使っています。
これで取り出せました('ω')ノ
8.データをグラフ化する
以上の結果をグラフ化するには、Pythonのライブラリのmatplotlibを使うと良いです(^^)
plt.figure(figsize=(10.0, 8.0))
plt.plot(temp, cp, label = 'spline',color='black', linewidth = 3.0)
plt.scatter(temp, cp, label = 'spline',color='gray', linewidth = 10.0)
plt.xlabel('Temperature[K]',fontsize=18)
plt.ylabel('Cp[kJ/kg K]',fontsize=18)
plt.tick_params(labelsize=18)
plt.grid()
plt.show()
できました(^^)/
全体のコード
では、最後に全体のコードを残しておきましょう('◇')ゞ
まずは、以下のコマンドを打ちます。
(Google Colavoratory上で実行します)
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/binそして以下がPythonコードの全体となります。
#必要なライブラリのインポート
from selenium import webdriver
from time import sleep
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
#ブラウザの起動
url = 'https://www.engineeringtoolbox.com/air-specific-heat-capacity-d_705.html'
browser = webdriver.Chrome('chromedriver',options=options)
browser.get(url)
#要素の取得
elem_table = browser.find_element_by_class_name('x-large')
elem =elem_table.find_element_by_tag_name('tbody')
elems_tr = elem.find_elements_by_tag_name('tr')
#データの取得
datas = []
for elem_tr in elems_tr:
elems = elem_tr.find_elements_by_tag_name('td')
lists = []
for elem in elems:
lists.append(elem.text)
datas.append(lists)
#データをPandas形式に変換
df = pd.DataFrame(datas)
#温度と比熱の列だけを取り出す
temp_ = df.iloc[:,0]
cp_ =df.iloc[:,9]
#取り出したデータ(文字列)を数値に変換
temp = np.array([float(u) for u in temp_])
cp = np.array([float(u) for u in cp_])
#データをグラフ化する
plt.figure(figsize=(10.0, 8.0))
plt.plot(temp, cp, label = 'spline',color='black', linewidth = 3.0)
plt.scatter(temp ,cp, label = 'spline',color='gray', linewidth = 10.0)
plt.xlabel('Temperature[K]',fontsize=18)
plt.ylabel('Cp[kJ/kg K]',fontsize=18)
plt.tick_params(labelsize=18)
plt.grid()
plt.show()
これでネット上のデータの取り扱いの基本的なことがわかりましたね('ω')
しかし、著作権やサイトを徘徊しすぎたりする可能性もあるので十分気をつけて「スクレイピング&クローリング(徘徊)」をしてください。
☟僕はこちらの参考書を購入しました。
Twitter➡@t_kun_kamakiri
ブログ➡宇宙に入ったカマキリ(物理ブログ)
この記事が気に入ったらサポートをしてみませんか?