
【(後編)Python】別々のフォルダ内のcsvファイルをグラフ化する。

脱エクセルを目指してPythonを学んでいます。
前回に引き続き、今回は後編としてnoteを書いています。
【前回の内容】
1.複数のディレクトリを作成
2.データを作成
3.データをデータフレームに入れる
4.csvファイルを作成してフォルダに保存する
5.2~4を関数にまとめて複数のデータを各フォルダに保存する
今回やることは、以下の内容です。
【今回の内容】
1.フォルダ内から「data_A,data_B,data_C,data_D」のフォルダのみ取得
2.フォルダにあるcsvファイルのみ取得
3.csvファイルをpandasで読み込む
4.csvファイルのヘッダーを取得
5.ひとつグラフを書いてみる
6.複数のグラフを書く
7.2~6を関数にしてまとめる
8.7で作成した関数を使って各フォルダにあるcsvファイルを作成する
【使用環境】
Pythonの使用環境はGoogle colaboratoryをしようしています。
Google のアカウントひとつでPythonが使用できるを作ることができます。
コードの詳細の説明はブログで解説します。
このnoteでは「Python初心者」に毛が生えた程度の人を想定しています
前回のおさらい
前回のコードを書いておいた方がわかりやすいと思いますので、こちらに載せておきます。
まず、各フォルダを作成
import os
path = os.getcwd()
dirs = ['data_A','data_B', 'data_C', 'data_D']
for dir in dirs:
os.mkdir(dir)
print(path)
print(os.listdir())次に各フォルダにcsvファイルを作成する関数を用意
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def make_csv(i):
time = np.linspace(0,100,101)
x1 = np.sin(time*random.randint(0,5))
x2 = np.sin(time*random.randint(0,5))
x3 = np.sin(time*random.randint(0,5))
x4 = np.sin(time*random.randint(0,5))
df_t = pd.DataFrame(time)
df_x1 = pd.DataFrame(x1)
df_x2 = pd.DataFrame(x2)
df_x3 = pd.DataFrame(x3)
df_x4 = pd.DataFrame(x4)
df = pd.concat([df_t, df_x1,df_x2,df_x3,df_x4], axis=1)
df.columns = ['time(sec)', 'x1(m)','x2(m)','x3(m)','x4(m)']
#csvで保存する
save_dir = dirs[i] + '/test.csv'
df.to_csv(save_dir,index=False, header=df.columns)作成した関数をfor文で繰り返せばフォルダにcsvファイルが作成されます。
for i, dir_ in enumerate(dirs):
make_csv(i)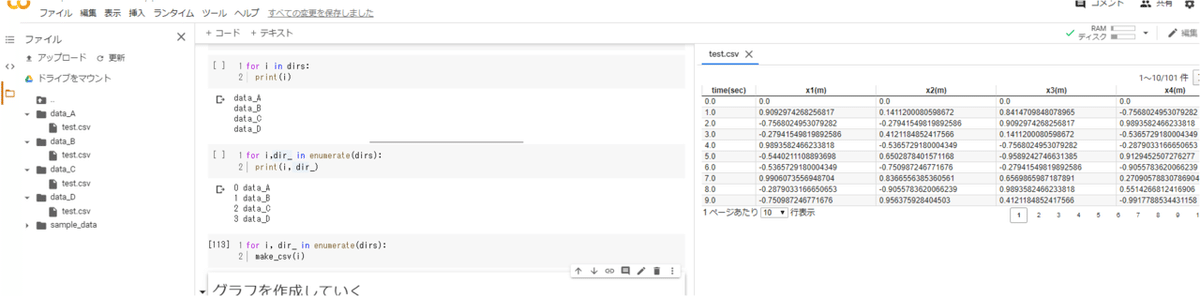
では、さっそく今回の内容に入っていきます。
1.フォルダ内から「data_A,data_B,data_C,data_D」のフォルダのみ取得
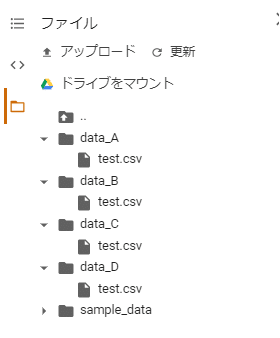
フォルダ内にはいろいろな「ファイル」だったり「フォルダ」が存在しますよね。
↓こんな感じで。
今取得したいフォルダは「data_A,data_B,data_C,data_D」だけです。
これを取得します。
import os
path ='./'
files = os.listdir()
files_dir = [f for f in files if os.path.isdir(os.path.join(path, f))]
files_dir = [dir_ for dir_ in files_dir if dir_[:4]=='data']
files_dir =sorted(files_dir)
files_dir
取得できました。
2.フォルダにあるcsvファイルのみ取得
さらにフォルダの中にはいろいろな形式のファイルがありますよね。
例えばエクセルデータやパワポや動画など・・・・そのなかでcsvファイルのみを取得します。
csv_lists = os.listdir('./'+ files_dir[0])
for csv_list in csv_lists:
if csv_list[-4:] == '.csv':
csv_file=csv_list
dir_csv_file = files_dir[0]+ '/'+ csv_file
dir_csv_file 
files_dir[0]とすることで「data_A」のフォルダを指定しています。
3.csvファイルをpandasで読み込む
では、各フォルダにあるcsvファイル読み込んでpandasで表形式にで表示しています。
data = pd.read_csv(dir_csv_file,encoding='cp932',skiprows=0)
df = data
df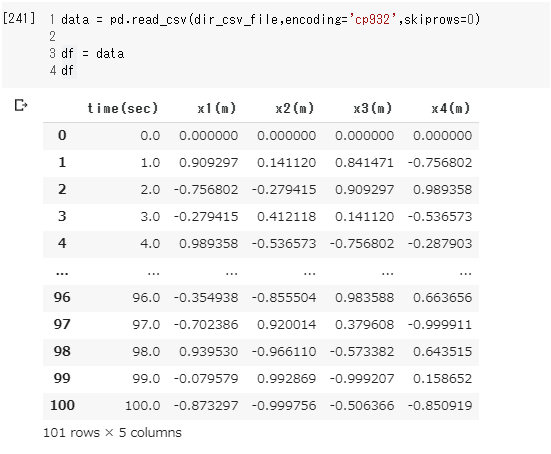
このようにpandasを使えば簡単にエクセルのような表を作成することがでできます。
4.csvファイルのヘッダーを取得
これは後で使うのでcsvファイルのヘッダーを取得しておきます。
前回のコードで
「 df.columns = ['time(sec)', 'x1(m)','x2(m)','x3(m)','x4(m)']」
と書いている部分でヘッダーを指定しています。
今回はこれを使います。
headers = df.columns
headers
ヘッダーの取得ができました。
5.ひとつグラフを書いてみる
今回は「data_A,data_B,data_C,data_D」という4つのフォルダに、「x1,x2,x3,x4」という4つのデータを扱うので、
4×4のグラフの枠を用意しておきます。
いきなり全部のグラフを描くのはややこしいのでひとつだけグラフを描いています。
fig, axes = plt.subplots(2,2,figsize=(20,12))
axes[0,0].legend(files_dir,bbox_to_anchor=(0, 1.3), loc='upper center')
fig.subplots_adjust(wspace=0.4, hspace=0.5)
axes[0,0].set_title(files_dir[0])
axes[0,0].grid()
axes[0,0].set_xlabel(headers[0],fontsize=10)
axes[0,0].set_ylabel(headers[1] ,fontsize=10)
axes[0,0].plot(df[headers[0]], df[headers[1]], label=files_dir[0])
うまくいきました。
今は、「data_A」のフォルダのcsvファイルの「x1」だけのデータを読み込んでグラフしたことになります。
6.複数のグラフを書く
では、ひとつグラフが描けたら4つグラフを描くこともできます。
fig, axes = plt.subplots(2,2,figsize=(20,12))
axes[0,0].legend(files_dir,bbox_to_anchor=(0, 1.3), loc='upper center')
fig.subplots_adjust(wspace=0.4, hspace=0.5)
axes[0,0].set_title(files_dir[0])
axes[0,0].grid()
axes[0,0].set_xlabel(headers[0],fontsize=10)
axes[0,0].set_ylabel(headers[1] ,fontsize=10)
axes[0,0].plot(df[headers[0]], df[headers[1]], label=files_dir[0])
axes[0,1].set_title(files_dir[0])
axes[0,1].grid()
axes[0,1].set_xlabel(headers[0],fontsize=10)
axes[0,1].set_ylabel(headers[2] ,fontsize=10)
axes[0,1].plot(df[headers[0]], df[headers[2]], label=files_dir[0])
axes[1,0].set_title(files_dir[0])
axes[1,0].grid()
axes[1,0].set_xlabel(headers[0],fontsize=10)
axes[1,0].set_ylabel(headers[2] ,fontsize=10)
axes[1,0].plot(df[headers[0]], df[headers[3]], label=files_dir[0])
axes[1,1].set_title(files_dir[0])
axes[1,1].grid()
axes[1,1].set_xlabel(headers[0],fontsize=10)
axes[1,1].set_ylabel(headers[3] ,fontsize=10)
axes[1,1].plot(df[headers[0]], df[headers[4]], label=files_dir[0])
「axes」は配列になっているので行と列を指定すればどの領域にグラフを描くかが指定できます。
ただ、これだとめちゃくちゃ効率が悪いコードの書き方なのでfor文を使ってまとめてやります。
fig, axes = plt.subplots(2,2,figsize=(20,12))
axes[0,0].legend(headers,bbox_to_anchor=(0, 1.3), loc='upper center')
fig.subplots_adjust(wspace=0.4, hspace=0.5)
for i , header in enumerate(headers[1:]):
axes[i//2,i%2].set_title(files_dir[0])
axes[i//2,i%2].grid()
axes[i//2,i%2].set_xlabel(headers[0],fontsize=10)
axes[i//2,i%2].set_ylabel(headers[i+1] ,fontsize=10)
axes[i//2,i%2].plot(df[headers[0]], df[headers[i+1]], label=files_dir[0])axes[i//2,i%2]と書いていますが、
●i//2:2で割ったときの商
●i%2:2で割ったときの余り
を意味しています。
for i , header in enumerate(headers[1:]):
の部分でiが「0,1,2,3」と順番に代入されます。
★[0,0]
→0を2で割ったときの商:0
→0を2で割ったときの余り:0
★[0,1]
→1を2で割ったときの商:0
→1を2で割ったときの余り:1
★[1,0]
→2を2で割ったときの商:1
→2を2で割ったときの余り:0
★[1,1]
→3を2で割ったときの商:1
→3を2で割ったときの余り:1
としていればうまくaxesの配列に当てはまっています。
7.2~6を関数にしてまとめる
では、今までやったことを関数にまとめておきます。
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
path ='./'
files = os.listdir()
files_dir = [f for f in files if os.path.isdir(os.path.join(path, f))]
#フォルダ全体から「data_A~data_D」を取得
files_dir = [dir_ for dir_ in files_dir if dir_[:4]=='data']
files_dir =sorted(files_dir)
def data_graph(data_dir):
#フォルダの中からcsvファイルを取得
csv_lists = os.listdir('./'+ files_dir[data_dir])
for csv_list in csv_lists:
if csv_list[-4:] == '.csv':
csv_file=csv_list
#./フォルダ名/csvファイル
dir_csv_file = files_dir[data_dir]+ '/'+ csv_file
#ファイルの読み込み
data = pd.read_csv(dir_csv_file,encoding='cp932',skiprows=0)
df = data
#ヘッダーの取得
headers = df.columns
#axes[0,0].legend(files_dir[data_dir],bbox_to_anchor=(0, 1), loc='upper center')
fig.subplots_adjust(wspace=0.4, hspace=0.5)
for i , header in enumerate(headers[1:]):
axes[i//2,i%2].plot(df[headers[0]], df[headers[i+1]], label=files_dir[data_dir])
axes[0,0].legend(bbox_to_anchor=(0, 1, 0.5, 0.5)) fig, axes = plt.subplots(2,2,figsize=(20,12))
data_graph(0)とすれば「data_A」の「x1,x2,x3,x4」のデータをグラフ化してくれます。
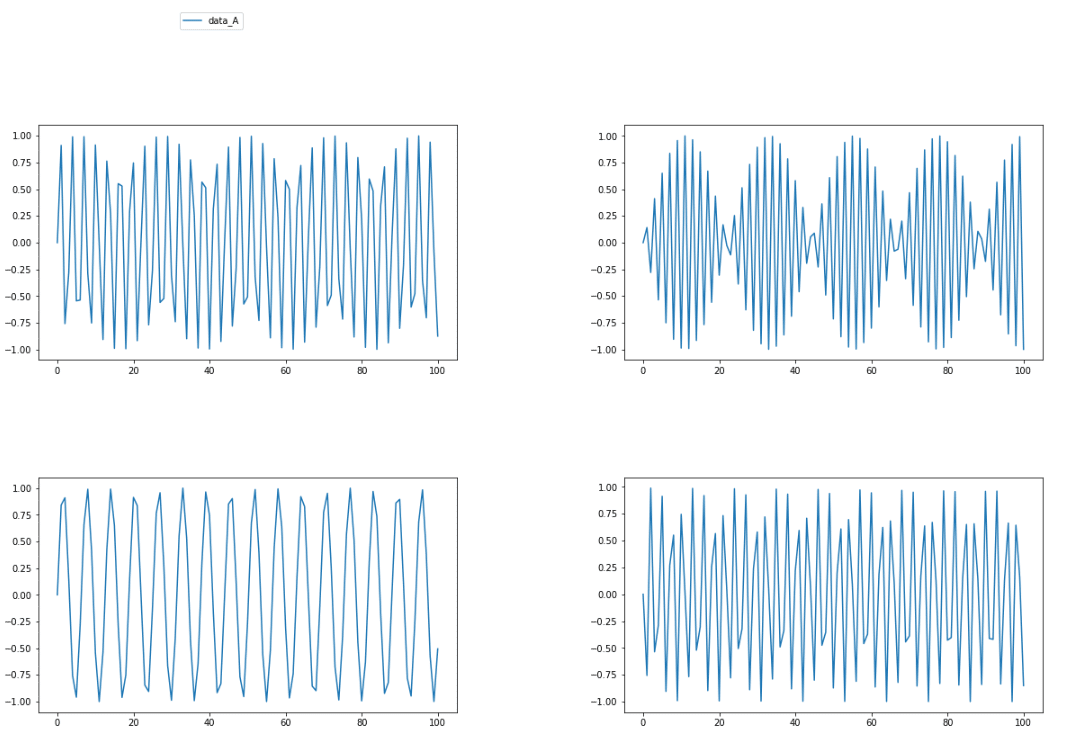
うまくいきました。
これで大まかな流れはできました。
8.7で作成した関数を使って各フォルダにあるcsvファイルを作成する
あとは、関数をfor文で「data_A,data_B,data_C,data_D」のフォルダを繰り返して全てのデータをグラフ化することができます。
fig, axes = plt.subplots(2,2,figsize=(20,12))
for i , file_dir in enumerate(files_dir):
axes[i//2,i%2].set_title(headers[i+1])
axes[i//2,i%2].grid()
axes[i//2,i%2].set_xlabel(headers[0],fontsize=10)
axes[i//2,i%2].set_ylabel(headers[i+1] ,fontsize=10)
data_graph(i)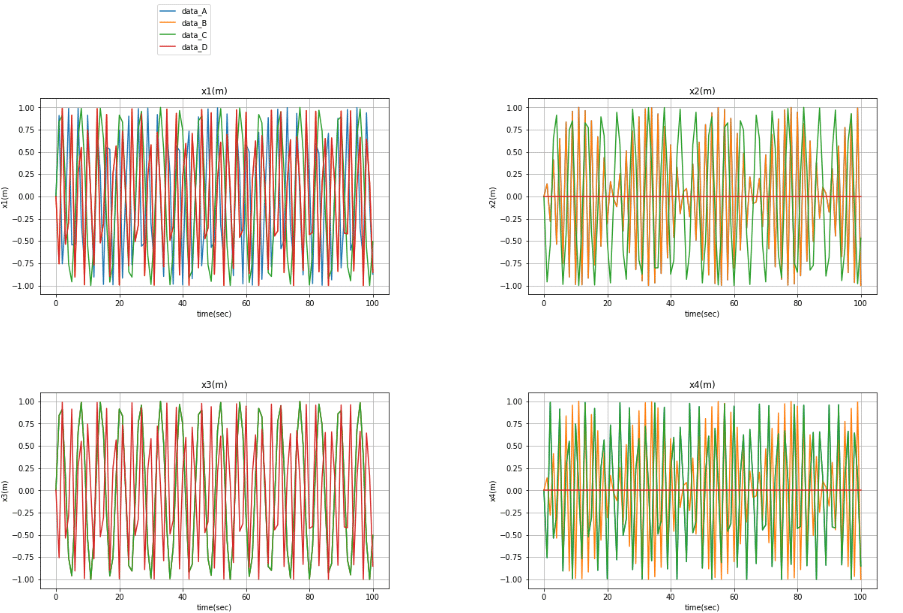
できました(^^)/
一応適当に「凡例(label)」「軸」「タイトル」などをつけておきました。
全体のコード
全体のコードを載せておきます。
フォルダ内に「csvファイル」があってそれをまとめてグラフ化したいというときに使ってください。
↓こんな状況で・・・・
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
path ='./'
files = os.listdir()
files_dir = [f for f in files if os.path.isdir(os.path.join(path, f))]
#フォルダ全体から「data_A~data_D」を取得
files_dir = [dir_ for dir_ in files_dir if dir_[:4]=='data']
files_dir =sorted(files_dir)
def data_graph(data_dir):
#フォルダの中からcsvファイルを取得
csv_lists = os.listdir('./'+ files_dir[data_dir])
for csv_list in csv_lists:
if csv_list[-4:] == '.csv':
csv_file=csv_list
#./フォルダ名/csvファイル
dir_csv_file = files_dir[data_dir]+ '/'+ csv_file
#ファイルの読み込み
data = pd.read_csv(dir_csv_file,encoding='cp932',skiprows=0)
df = data
#ヘッダーの取得
headers = df.columns
#axes[0,0].legend(files_dir[data_dir],bbox_to_anchor=(0, 1), loc='upper center')
fig.subplots_adjust(wspace=0.4, hspace=0.5)
for i , header in enumerate(headers[1:]):
axes[i//2,i%2].plot(df[headers[0]], df[headers[i+1]], label=files_dir[data_dir])
axes[0,0].legend(bbox_to_anchor=(0, 1, 0.5, 0.5)) fig, axes = plt.subplots(2,2,figsize=(20,12))
for i , file_dir in enumerate(files_dir):
axes[i//2,i%2].set_title(headers[i+1])
axes[i//2,i%2].grid()
axes[i//2,i%2].set_xlabel(headers[0],fontsize=10)
axes[i//2,i%2].set_ylabel(headers[i+1] ,fontsize=10)
data_graph(i)はい、グラフ完成(^^)/
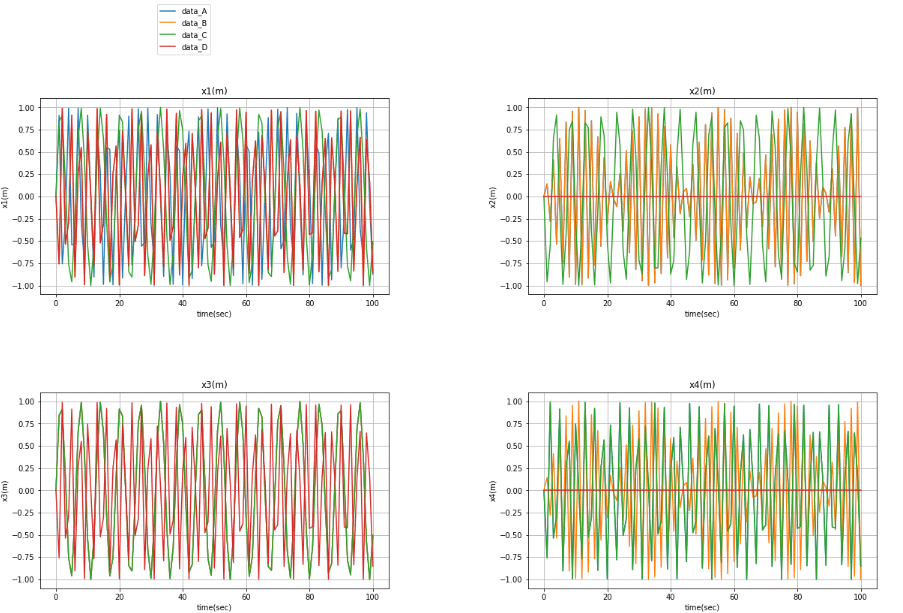
今回は以上です。
Twitter➡@t_kun_kamakiri
ブログ➡宇宙に入ったカマキリ(物理ブログ)
この記事が気に入ったらサポートをしてみませんか?