【PythonでTwitter分析】「いいね数はいくらで1フォロワー増加するのか」を単回帰分析してみた。

こんにちは(@t_kun_kamakiri)
Twitterのフォロワーを増やすためにはTwitter分析が欠かせないですよね。
現在フォロワー数が1520人ですが、Twitter分析を一度もしたことがありませんでした。
Twitter分析をまともにしたことがなかったので今回はPythonを使って簡単に分析をしたいと思います。
今回は「いいね数はいくらで1フォロワー増加するのか」を単回帰分析で見積もってみようと思います。
Twitterアナリティクスからデータ入手
こちらからcsvファイルが入手できるので今回は「2020年11月~2021年2月」の4か月分だけ入手しました。
このようにcsvファイルをjupyter labのファイルと同じ階層に置いておきます。
Pythonでデータの読み込み
まずは分析に使うPythonライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np次にcsvファイルだけを読み込みたいので以下の記述を書きます。
import glob
csv_files = glob.glob('*csv')
csv_files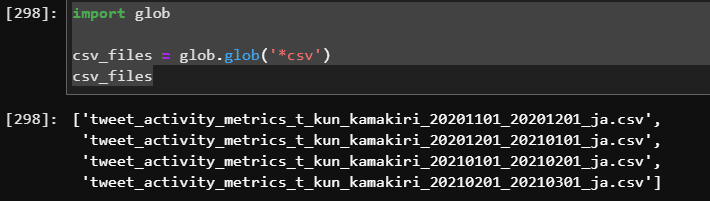
これでcsvファイルがリストになりました。
これら別々のcsvファイルを読み込みながら行方向に合体させる必要があります。
import glob
csv_files = glob.glob('*csv')
csv_files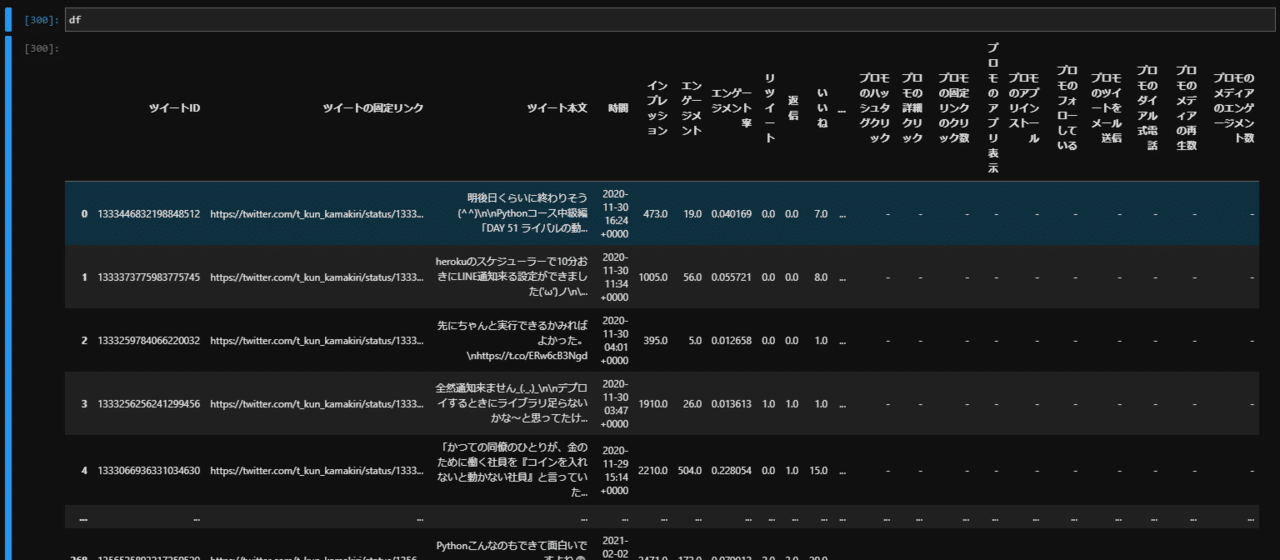
これでデータの結合が終わりました。
データの大きさを確認しましょう。
df.shape# (1291, 40)1291行ありますね。
不必要なカラムが多いのでカラムを全部出力してみましょう。
df.columns
プロモーションなどはしていないので不必要なカラムは削除します。
今回は必要なカラムを以下のみにします。
data_list = ['ツイートID', 'ツイート本文', '時間', 'インプレッション', 'エンゲージメント',
'エンゲージメント率', 'リツイート', 'いいね', 'ユーザープロフィールクリック', 'URLクリック数',
'ハッシュタグクリック', '詳細クリック', 'メディアの再生数', 'メディアのエンゲージメント数']
len(data_list)14項目だけにしました。
日本語だとグラフを書くときに文字化けするので英語にしておきます。
data_list_columns = ['ID', 'text', 'date', 'impression', 'engagement',
'engagement_ratio', 'RT', 'fav', 'profile_click', 'URL_click',
'hashtag_click', 'detail_click', 'media_click', 'media_engagement']
len(data_list_columns)上記をデータフレームのカラムに設定すればよいですね。
df = df[data_list]
df.columns = data_list_columns
df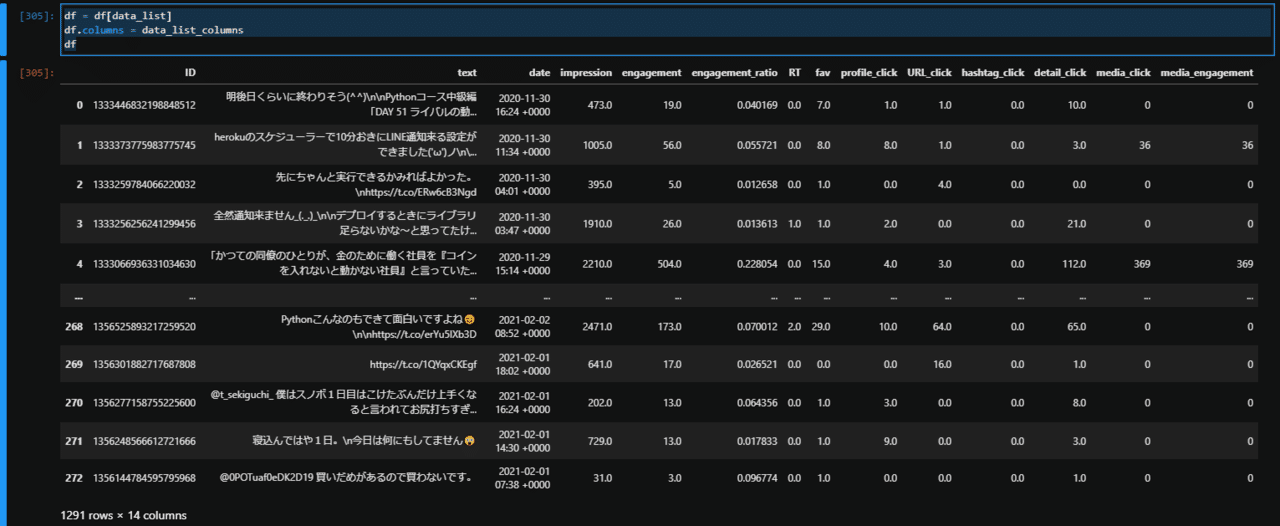
いいね数で並べ替えてどのツイートがウケが良かったのか確認してみましょう。
df.sort_values('profile_click', ascending=False).head(30)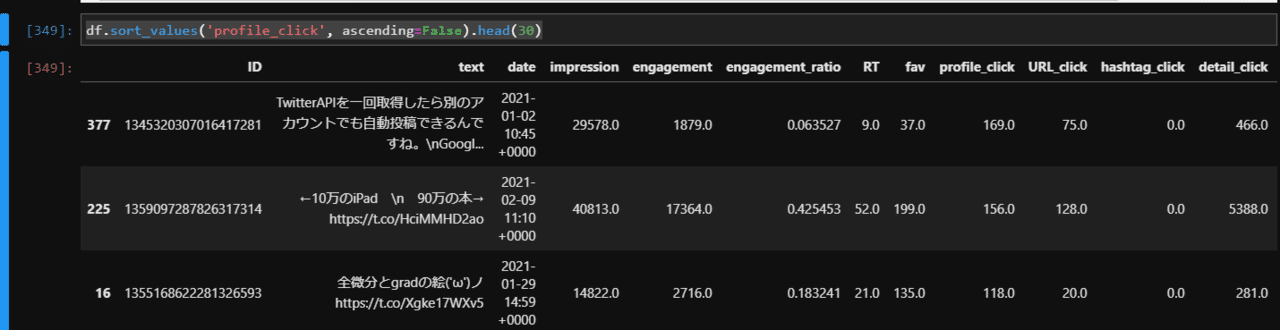
ツイート情報は以下のメソッドで確認できます。
df.info()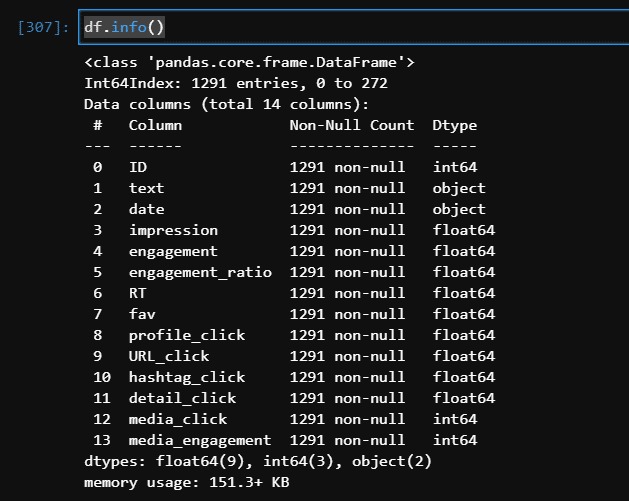
Twitterの可視化をしてみよう
ツイートデータを取得できたらグラフを書いて可視化して眺めてみましょう。
今回、グラフの可視化はseabornを使います。
seabornは超優秀な可視化ライブラリなのでドキュメントを見て色々遊んでみましょう。
まずはライブラリをインポートします。
import seaborn as snsまずは全データの相関を見てみましょう。
sns.pairplot(df.drop('ID', axis=1))
量が多いですが着目する点は「プロフィールクリック数」とどの要素が相関があるかですね。
相関係数を確認
では相関係数を見てみましょう。
corr_data = df.corr()
corr_data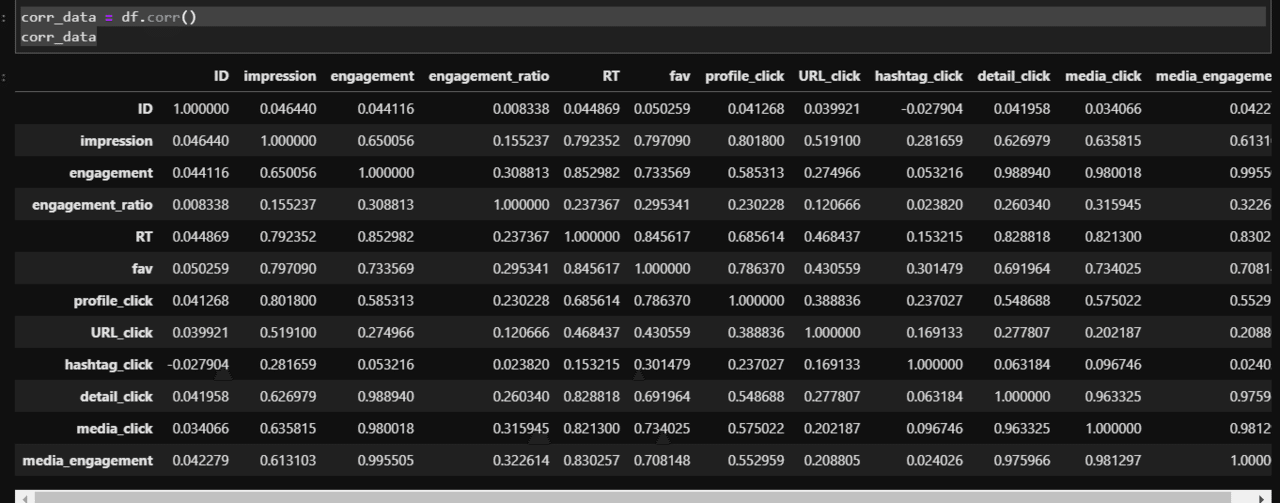
プロフィールクリック数(profile_click)と相関が大きいのは以下の項目であることがわかりました。
●impression:0.801800
●fav:0.786370
●RT:0.685614
なんとなくわかっていたことですがやはり「いいね数(fav)」が多いとプロフィールクリック数も多いのですね。
数字だと見ずらいので相関係数も可視化してみましょう。
plt.figure(figsize=(20,10))
sns.heatmap(corr_data, annot=True)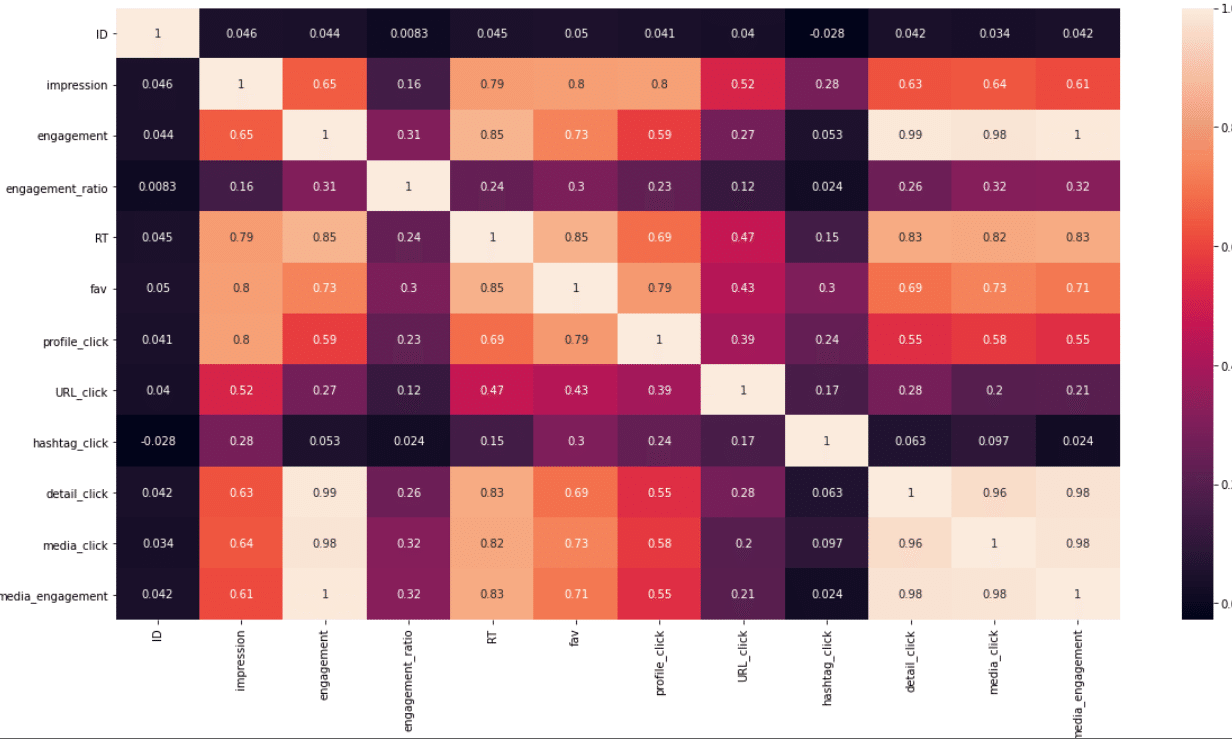
その他の統計量も眺めておきましょう。
df.describe()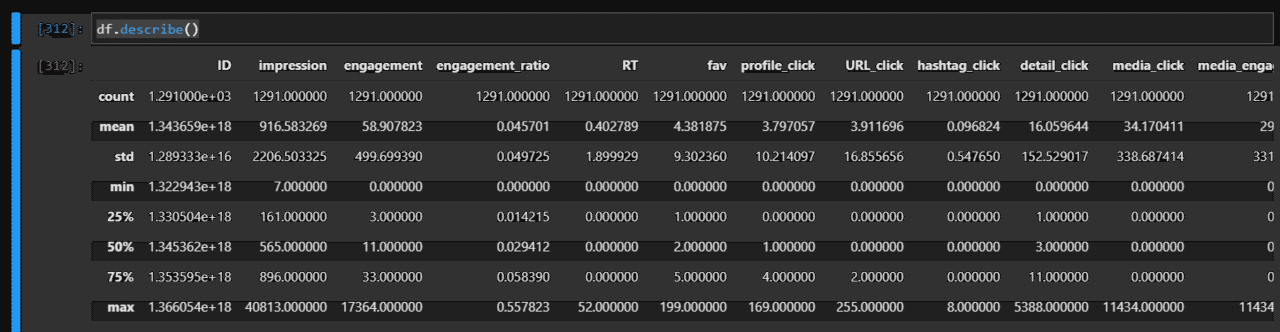
だいたい1ツイートで4いいねくらいが平均だとわかりました。
少ない(笑)
3σ法で外れ値を除去する
もっといいね数が多い場合は平均値のまわりでばらつくので正規分布に従うと考えられます。外れ値(極端にバズっとツイート)などがある場合は、その外れ値に釣られて平均値が大きくなったり、相関係数が大きくなったりするため外れ値は除去しておくのが良いと考えられます。
ぼくの場合はいいね数が少なすぎるので正規分布ではありませんが、一応外れ値を3σで除去しておきます。
正規分布ではないのに3σで外れ値を除去するのはおかしいですがPytonのコードを書く練習だと思ってやってみました。
まずは平均値と標準偏差を出しておきましょう。
fav_mean = df['fav'].mean()
fav_std = df['fav'].std() #不偏標準偏差(母集団の分散が不明であるときの母分散の推定値) https://ai-trend.jp/basic-study/estimator/unbiasedness/
fav_stdそして外れ値を除去するため「平均±3σ」を算出します。
sigma3_p = fav_mean + fav_std*3
sigma3_n = fav_mean - fav_std*3
print(f'外れ値+3σ:{sigma3_p}')
print(f'外れ値-3σ:{sigma3_n}')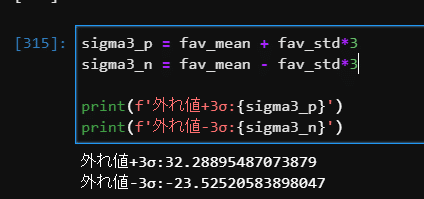
僕の場合はいいね数が32以上は外れ値扱いになってしまいます。
マイナスの方はー23なので、やっぱり3σ法で外れ値を除去するのはおかしいやり方ですが、今回はいいでしょう(笑)
僕のツイートは0いいねも多いので、2いいね以上かつ31いいね以下のものだけをデータとして抽出します。
df_3sigma = df[(df['fav'] <sigma3_p) & (df['fav'] >1)]
df_3sigma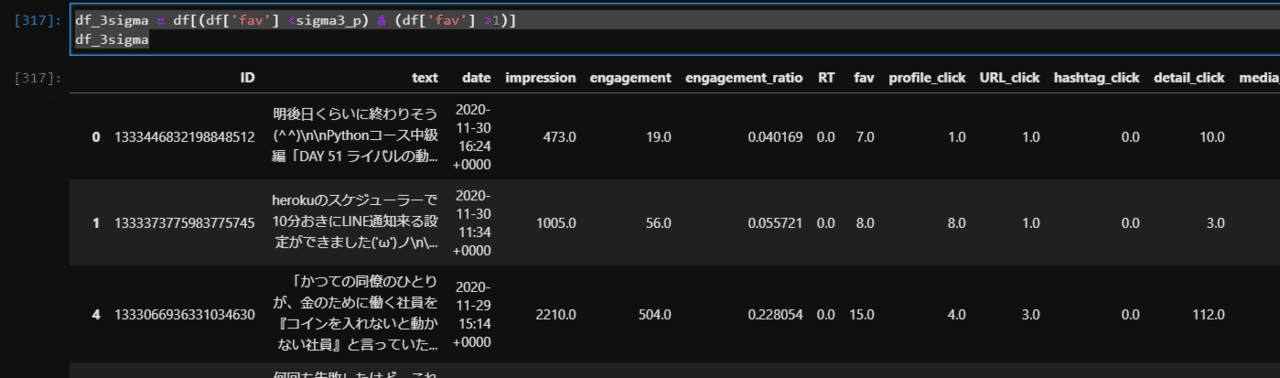
いいね数の数も確認しておきましょう。
df_3sigma['fav'].value_counts()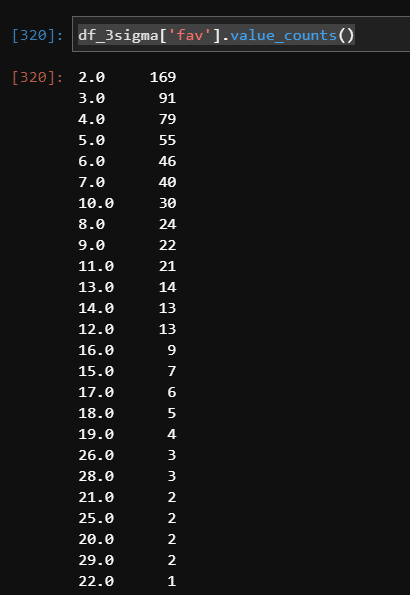
2いいねが大半を占めますね(笑)
もう一度相関図を眺めてみましょう。
corner=Trueとすると無駄な相関のグラフを除いてくれます。
sns.pairplot(df_3sigma.drop('ID', axis=1), corner=True)
plt.figure(figsize=(20,10))
sns.heatmap(corr_data, annot=True)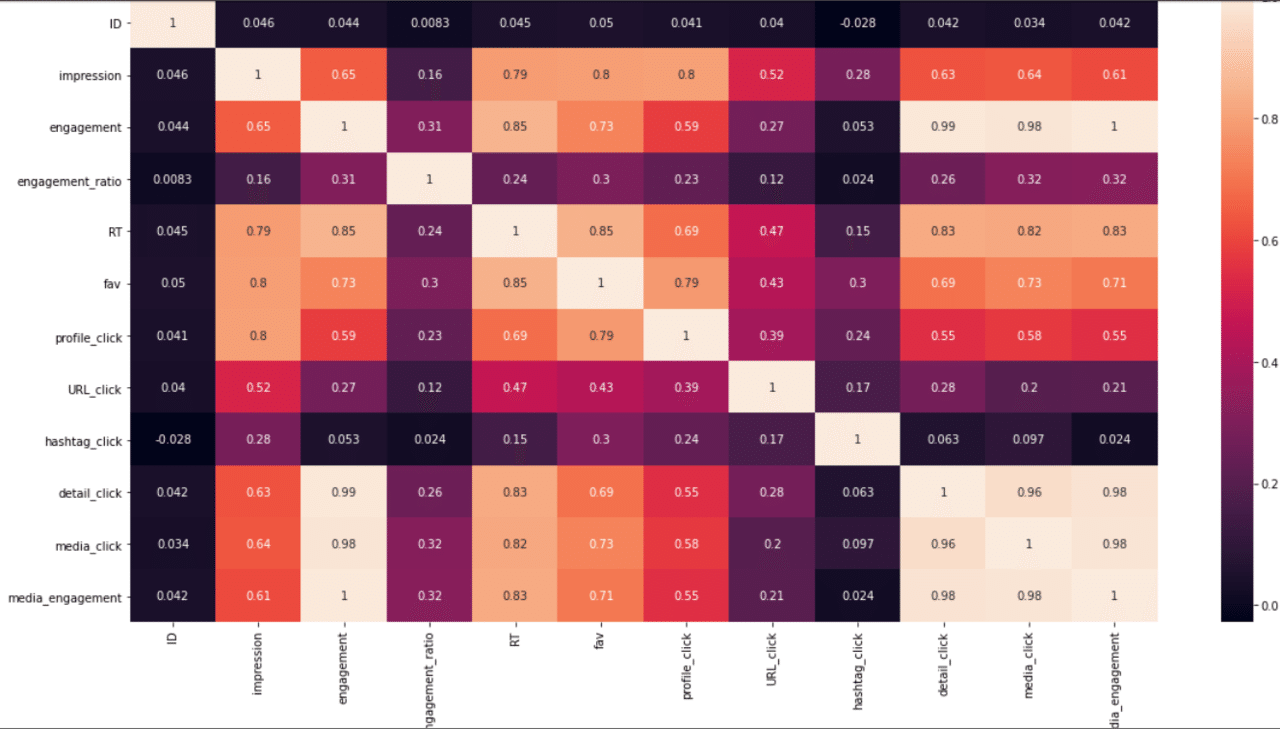
では、次にprofile_clickと相関のありそうな要素との関係性をグラフ化してみましょう。
●impression
●fav
●RT
●hashtag_click
●media_engagement
sns.pairplot(df_3sigma, x_vars=["impression", "fav", "RT",'hashtag_click','media_engagement'], y_vars=["profile_click"],height=5, aspect=.8, kind="reg")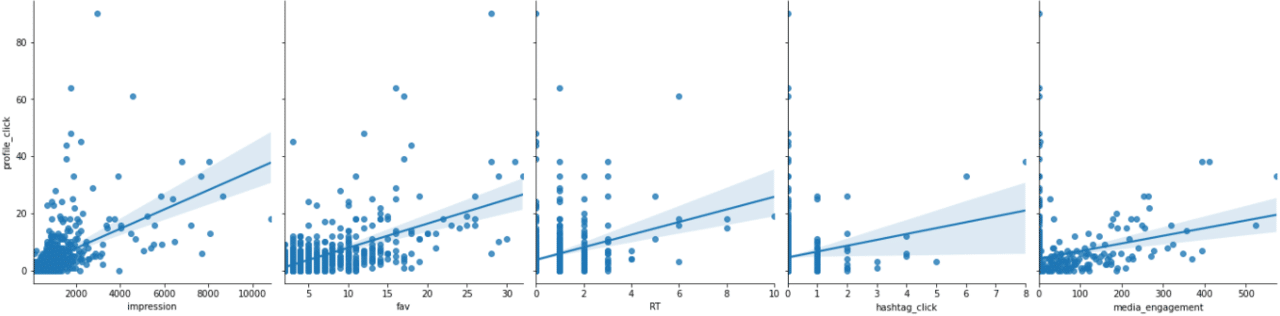
やっぱりimpression数とprofile_clickとの相関は強いですね。
sns.pairplot(df_3sigma, x_vars=["impression", "fav", "RT",'hashtag_click','media_engagement'],
y_vars=["profile_click"],height=5, aspect=.8, kind="reg")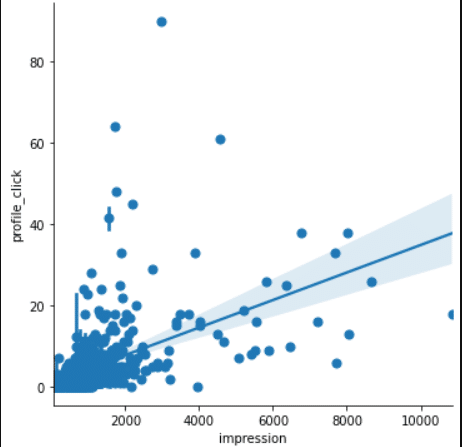
念のため全体のヒストグラムも眺めてみましょう。
df_3sigma.hist(figsize=(20,10))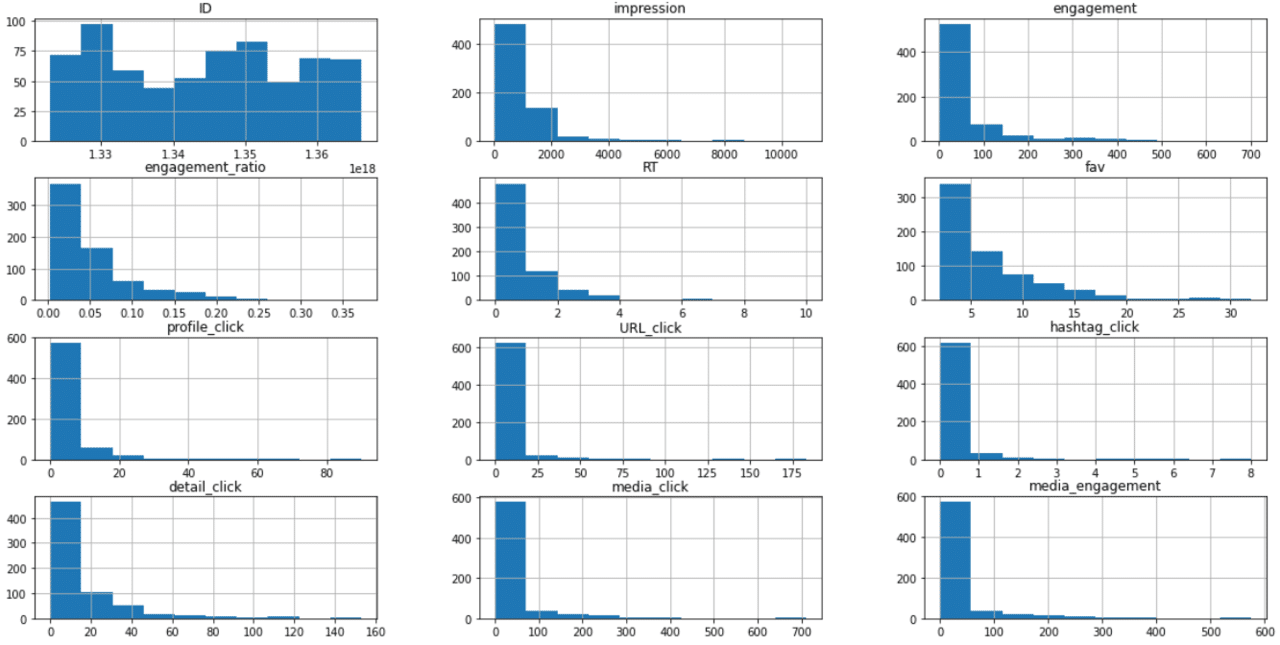
やっぱり僕のツイートは反応が鈍いほうに偏っているのであまり良いデータではありませんがまあ気にしない(笑)
いいね数だけの「ヒストグラム」と「カーネル密度分布」にすることができます。
sns.distplot(df_3sigma['fav'])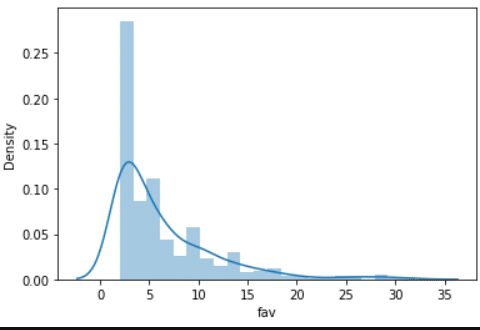
プロフィールクリック数とフォロワー増加を見積もる
どれだけのプロフィールクリック数があればフォロワー増加につながるのでしょうか?
毎日のフォロワー増加がわかれば詳細な分析ができますが、フォロワー増加のデータはcsvで入手ができなかったので、今回はアナリティクスから月単位で手動でフォロワー増加を取得しました。
以下のように辞書型にしておきます。
follower = {
'2020-11':91,
'2020-12':137,
'2021-01':69,
'2021-02':86,
}ここから月単位でのプロフィールクリック数の平均を出すために月単位でまとめることを考えます。
def date_day(x):
return x.split(' ')[0].split('-')[0]+'-'+x.split(' ')[0].split('-')[1]
df_3sigma['year_month'] = df_3sigma['date'].apply(date_day)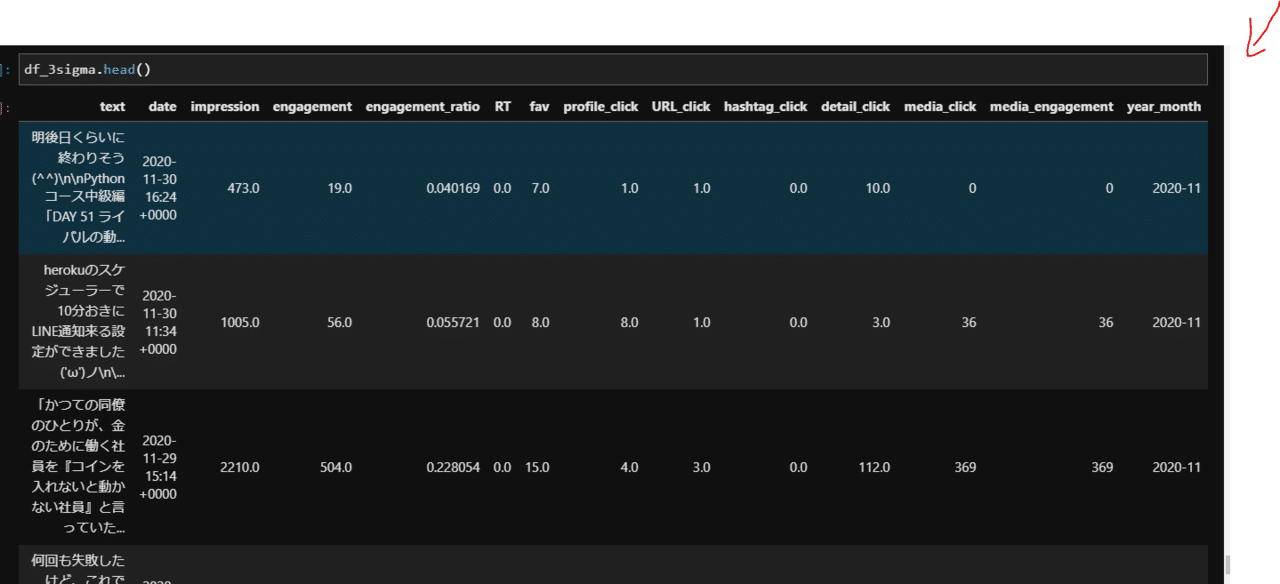
これで年と月だけがラベル付けされた列が追加されます。
次に月単位でグルーピングして月単位でのプロフィールクリック数を計算します。
df_3sigma_month = df_3sigma.groupby('year_month').sum()
df_3sigma_month
このようにすると月のプロフィールクリック数の合計が算出できます。
ここで「フォロワー増加/プロフィールクリック数」とすれば月平均の1プロフィールクリック数あたりのフォロワー増加が算出できるので、それを列に追加します。
df_3sigma_month['followers'] = pd.DataFrame(follower.values(),
index=df_3sigma_month.index)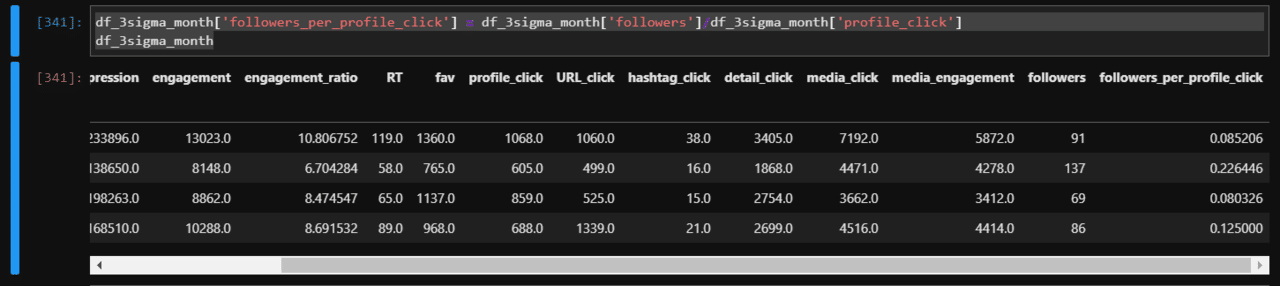
もちろん「プロフィールクリック数/フォロワー増加」が月平均の1フォロワー増加に必要なプロフィールクリック数が算出できます。
1/df_3sigma_month['followers_per_profile_click'].mean()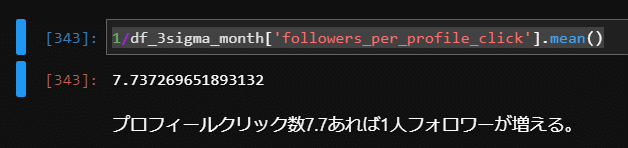
結果はこのようになりました。
プロフィールクリック数が7.7であれば良いという結果です。
いくつインプレッション数があれば1フォロワー増加になるのか?
プロフィールクリック数とフォロワー増加の数字の関係が上記でわかりました。
さらにインプレッション数とプロフィールクリック数は以下のように相関があることがわかっているので、インプレッション数とフォロワー増加の関係性も数字で出せるはずです。
下記のグラフがy=ax+bの関係ならプロフィールクリック数は7.7のときどれくらいのインプレッション数になるか逆算ができますね。
インプレッション数が大きいところではかなり分布がまばらなので短回帰分析をするのにデータ数が十分でない可能性もありますが、あまり気にしないことにします。
単回帰分析や重回帰分析はPythonのsklearnを使えば簡単に係数を計算してくれます。
本来の機械学習では学習データと検証データを分けて学習データで学習をし(パラメータフィッティング)、検証データで精度を確認するといった流れですが、今回は何かを予測するためではなくデータから関係性を予測したいだけなのですべてのデータをパラメータフィッティングに使います。
まずは2つのデータをX,yに格納します。
X = df_3sigma[['impression']]
y = df_3sigma['profile_click']そしてsklearnでパラメータフィッティングを行います。
from sklearn.linear_model import LinearRegression
# 単回帰分析model = LinearRegression()
model.fit(X, y)
y_pred = model.predict(X)
y_pred[:10]これでパラメータフィッティングは終わりました。
超簡単でしたね。
target_profile_click = 1/df_3sigma_month['followers_per_profile_click'].mean()
x_ = (target_profile_click - model.intercept_)/model.coef_[0]
x_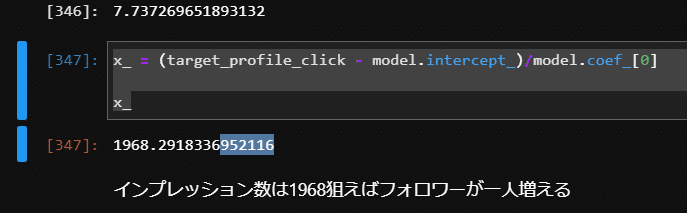
結果は1968インプレッション数でフォロワーがひとり増える計算結果となりました。
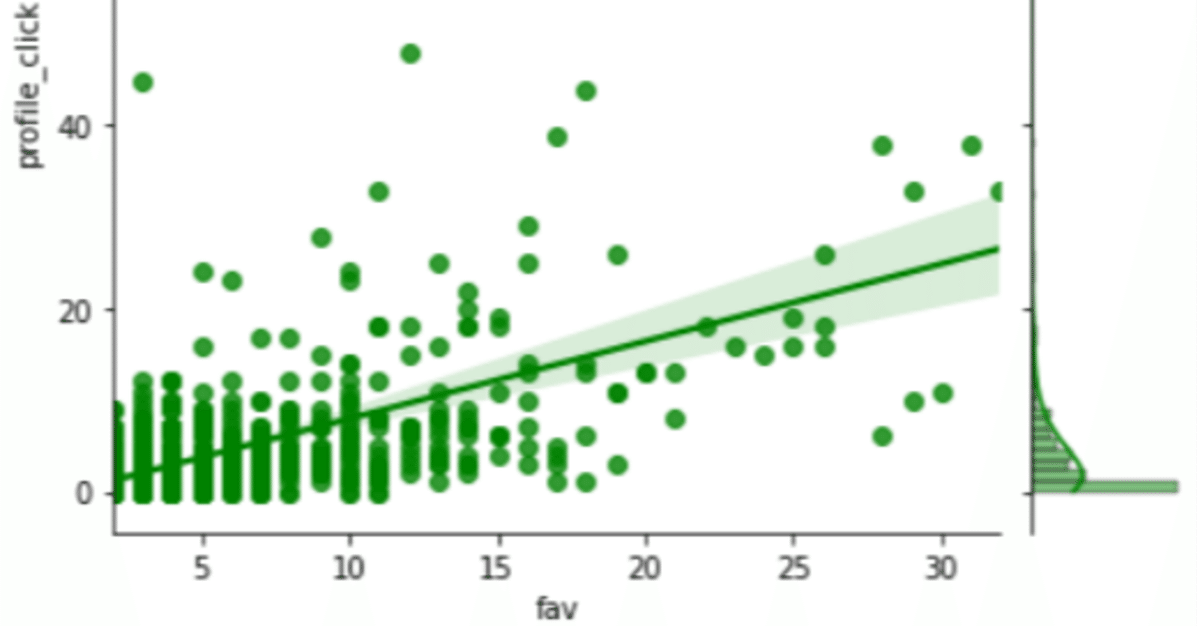
いくつのいいね数があれば1フォロワー増加になるのか?
インプレッション数をあまり確認する人っていないですよね。それよりもいいね数を見てる人が多いのでプロフィールクリック数といいね数の関係性から、いくるのいいね数ならフォロワーが一人増えるのかを計算してみます。
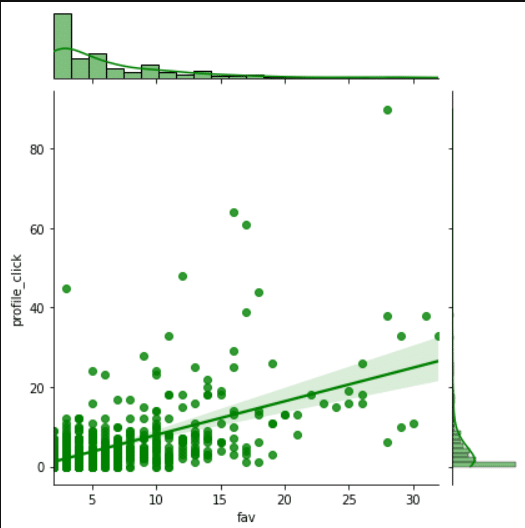
データがばらついていますし、まばらですが細かいことには目をつむってy=ax+bの単回帰分析で処理してみます。
# 単回帰分析
X = df_3sigma[['fav']]
y = df_3sigma['profile_click']
model = LinearRegression()
model.fit(X, y)
y_pred = model.predict(X)
x_ = (target_profile_click - model.intercept_)/model.coef_[0]
x_
1ツイートあたり10いいねを狙えばフォロワーが一人増えるという結果になりました。
いいね数10でフォロワーがひとり増える。
— カマキリ🐲@PythonとDjango勉強中 (@t_kun_kamakiri) March 26, 2021
「データ見なくても感覚的にわかるんじゃないの?」と言われそうな結果。 pic.twitter.com/LXKTlc5CMD
あとは他にフォロワー増加に必要な要素や、フォロワーが何に興味を示しているのかなど細かく分析をしていきたいところです。
まとめ
本日は簡単に単回帰分析だけで分析をしました。
1ツイートあたり10いいねを狙えばフォロワーが一人増えるという結果になりました。
次は、10いいね以上もらえるツイート内容は何なのか?・・・それを調べないといけませんね。
Twitter➡@t_kun_kamakiri
Instagram➡kamakiri1225
ブログ➡宇宙に入ったカマキリ(物理ブログ)
ココナラ➡物理の質問サポートサービス
コミュニティ➡製造業ブロガー
この記事が気に入ったらサポートをしてみませんか?