
Metaが最新言語モデルLlama3.1を発表!脅威のGPT-4o超え!?

こんにちは、スクーティーという生成AIを活用したシステム開発が得意な会社の代表をやっているかけやと申します。
生成AI技術の進化が止まりません!速すぎてついていくのが大変です!
米国時間で2024年7月23日、Meta社の最新のLLMであるLlama3.1が発表され、多くの注目を集めています。Llama 3からLlama 3.1へのマイナーバージョンアップではありますが、大幅に進化したLlama 3.1は、その驚異的な性能とオープンソース化という決断により、生成AIの世界に新たな波を起こしています。
本記事では、Llama 3.1の魅力を余すところなく解説し、その可能性に迫ります。
Llama 3.1 の基礎知識

Llama 3.1 とは?
Llama 3.1は、人間のように自然な文章を生成したり、翻訳、質問応答、対話生成など、様々なタスクをこなすAIです。膨大なデータから学習することで、従来のAIモデルでは不可能だったレベルの精度と自然さを実現しました。
処理できるコンテキストの長さが大幅に拡張され、128,000トークンという驚異的な長文に対応可能になりました。これは、前バージョンの8,000トークンと比べて16倍の長さであり、より複雑で長い文章を理解し、生成できるようになったことを意味します。
また、多言語対応も強化され、英語に加えて、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語の計8言語をサポートしています。この中に日本語は含まれませんが、私が動作を見る限り、日本語の文章に違和感はなく、精度として問題はないと感じました。
さらに、Llama 3.1は、オープンソースライセンスのもとで公開されています。これは、AI開発の歴史における大きな転換点であり、誰でも自由にモデルを利用、改変、再配布することが可能になりました。これにより、世界中の開発者がLlama 3.1の研究開発に貢献できるようになり、AI技術の進化が加速することが期待されています。
Llama 3.1 モデルファミリー
Llama 3.1は、8B、70B、405Bの3つのモデルサイズで提供されており、利用目的に合わせて最適なものを選択できます。
8Bモデル: 軽量で高速な処理が特徴で、モバイルデバイスや組み込みシステムなど、限られた計算資源しかない環境に最適です。
70Bモデル: 性能と効率のバランスが取れており、一般的な自然言語処理タスクに幅広く対応できます。
405Bモデル: 最も大規模で高性能なモデルであり、高度な言語理解や推論が必要なタスクに最適です。
さらに、各モデルサイズには、ベースモデルと指示モデルの2種類が用意されています。ベースモデルは汎用的な言語モデルであり、指示モデルは人間からの指示に対してより忠実に応答するようファインチューニングされています。
提供されているモデルのリスト:
Llama 3.1 の性能評価
ベンチマーク結果 - 驚異的なスコアで従来モデルを凌駕
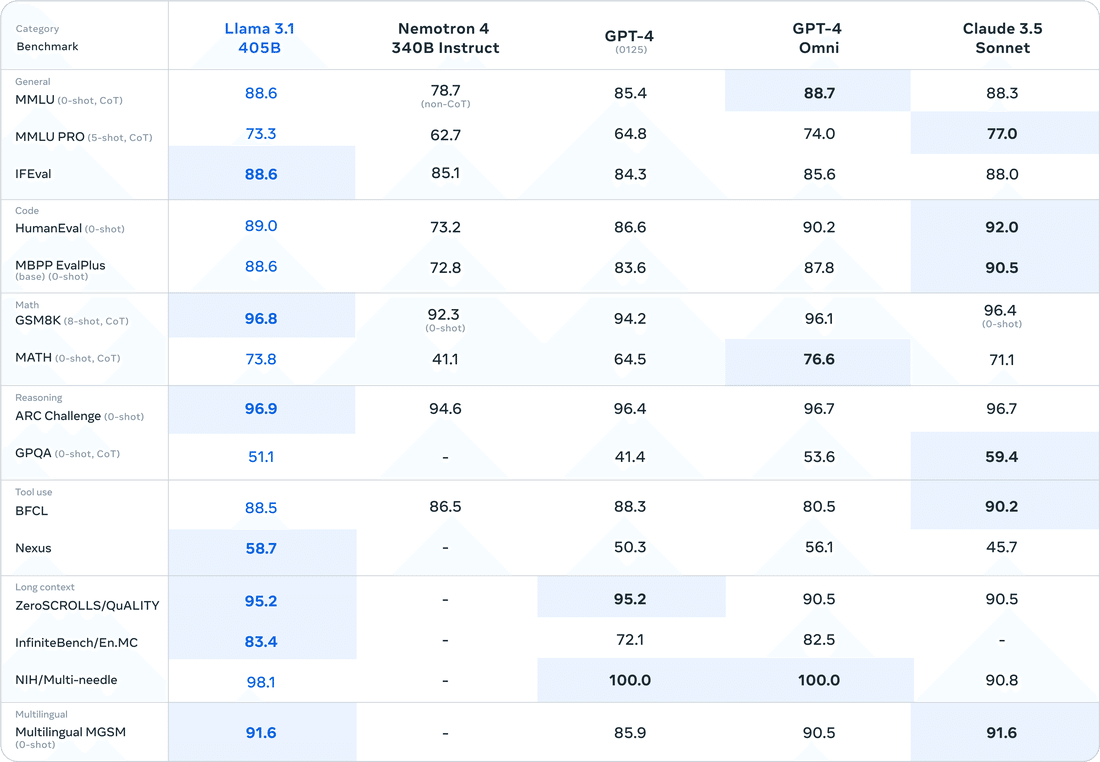

Llama 3.1の性能は、様々なベンチマークで評価されており、その結果は目を見張るものがあります。特に、405Bモデルは全体としてGPT-4oよりも高いパフォーマンスを示し、Claude 3.5 Sonnetとほぼ同等といったところです。
MMLU (Massive Multitask Language Understanding): 57の多様なタスクで構成される言語理解ベンチマークで、Llama 3.1 405Bモデルは87.3%という驚異的なスコアを達成しました。これは、人間レベルのスコア90%に迫るものであり、GPT-4oとほぼ同等の結果です。これはLlama 3.1の高度な言語理解能力を示す結果と言えます。
HumanEval: 与えられた指示に基づいてPythonコードを生成する能力を評価するベンチマークで、Llama 3.1 405Bモデルは89.0%という高いスコアを達成しました。これは、Llama 3.1 405Bが複雑な指示を理解し、正確にコードを生成できることを示しています。こちらもGPT-4oとほぼ同等、先日Anthropicから公開されたClaude 3.5 Sonnetよりは若干劣るという結果です。
GSM-8K: 小学レベルの数学の文章問題を解く能力を評価するベンチマークで、Llama 3.1 405Bモデルは96.8%という驚異的なスコアを達成しました。これは、Llama 3.1 405Bが高度な論理的思考能力と数学的推論能力を持っていることを示しています。
これらのベンチマーク結果は、Llama 3.1が幅広い分野において、極めて高い性能を持つAIモデルであることを証明しています。
参考までに、以下の記事ではGPT-4oとClaude 3.5 Sonnetの性能を評価、比較していますので、ぜひ御覧ください!
参考記事:GPT-4o vs Claude 3.5 Sonnet - 噂の最新言語モデルを徹底検証!
Llama 3.1 のライセンスと商用利用
Llama 3.1 は、「Llama 3.1 Community License」と呼ばれる特別な商用ライセンスのもとで提供されており、以前のバージョンと比べて、より商用利用に寛容になっています。詳細はライセンスの原文をご確認ください。
許可される行為:
モデルの再配布
モデルの微調整
派生作品の 作成
モデル出力を使用して他のLLMを改善すること。(異なるモデルであっても、合成データの生成と抽出が可能)
条件:
月間アクティブユーザー数が7億人を超える製品やサービスでLlama 3.1を利用する場合は、Metaから個別にライセンスを取得する必要がある
派生モデルの名前の先頭に「Llama」を含める
派生作品やサービスには「Built with Llama」と明記する
Llama 3.1 を支える技術
Transformerアーキテクチャ - 高度な言語処理を可能にする革新的な構造
Llama 3.1は、Transformerと呼ばれる深層学習アーキテクチャを基盤としています。Transformerは、2017年にGoogleの研究者によって発表されたもので、自然言語処理の分野に革命をもたらしました。
従来の自然言語処理モデルでは、長い文章を扱うのが苦手で、学習にも時間がかかるという課題がありました。しかし、Transformerは、Attention機構と呼ばれる仕組みを用いることで、これらの課題を克服しました。
Attention機構は、文章中の各単語が、他のどの単語と関連が深いかを計算する仕組みです。これにより、Transformerは、長い文章でも文脈を正確に把握することができ、より高精度な言語処理が可能となりました。
Llama 3.1 は、このTransformerアーキテクチャをベースに、さらに独自の改良を加えることで、従来モデルを超える性能と効率性を実現しています。
自己回帰型言語モデル - 過去のデータから未来を予測
Llama 3.1 は、自己回帰型言語モデルと呼ばれるタイプのモデルです。自己回帰型言語モデルは、過去のデータに基づいて未来のデータを予測するモデルです。
自然言語処理の文脈では、これは「過去の単語列から次の単語を予測する」ことを意味します。例えば、「今日はいい天気」という単語列が与えられたとき、自己回帰型言語モデルは、「です」という単語を予測します。
Llama 3.1 は、膨大な量のテキストデータから学習することで、この予測能力を極限まで高めています。これにより、人間が書いたような自然な文章を生成することができるのです。
大規模データ学習 - 15兆トークンの知識を凝縮
Llama 3.1 は、その驚異的な性能を、膨大な量のデータで学習することによって獲得しています。具体的には、Webサイト、書籍、コードなど、15兆トークンを超えるテキストデータが使用されています。
このような大規模データを用いた学習は、近年のAI技術の発展において、非常に重要な役割を果たしています。従来の機械学習では、人間が設計した特徴量をコンピュータに学習させていましたが、深層学習では、大量のデータからコンピュータ自身が特徴量を学習します。
Llama 3.1 は、この深層学習の力を最大限に活かすことで、従来の言語モデルでは考えられなかったレベルの言語理解能力を獲得したのです。
具体的には、公開されているソースからの約15兆トークンのデータと、公開されている指示データセットに加えて、SFT(Supervised Fine-Tuning)とRLHF(Reinforcement Learning from Human Feedback)によって作成された2,500万を超える合成生成例によって事前学習が行われています。
Llama 3.1 のメモリ要件

Llama 3.1 を実行するためのメモリ要件は、モデルのサイズと使用する精度によって異なります。モデルサイズが大きく、精度が高いほど、多くのメモリが必要となります。
例えば、405BモデルをFP16精度で実行する場合、モデルの重みだけで約800GBのメモリが必要になります。さらに、モデルのコンテキストを保持するためのKVキャッシュにも、コンテキスト長に応じて数百GBのメモリが必要になる場合があります。そのため、405Bモデルを実行するには、大規模なメモリを搭載したGPUサーバーが必要となります。
一方、8Bモデルや70Bモデルであれば、比較的小規模なGPUサーバーでも実行可能です。8BモデルをFP16精度で実行する場合、モデルの重みは約16GB、KVキャッシュは最大で約16GBとなり、合計で約32GBのメモリがあれば実行できます。70Bモデルの場合、モデルの重みは約140GB、KVキャッシュは最大で約140GBとなり、合計で約280GBのメモリが必要となります。
量子化による省メモリ化 - 少ないメモリで高性能を実現
Llama 3.1では、モデルのメモリ使用量を削減するために、量子化されたモデルも用意されています。量子化とは、モデルの重みを表現するデータ型を、精度を落とさずに、より少ないビット数で表現する技術です。これにより、モデルのメモリ使用量を削減し、推論速度を向上させることができます。
Llama 3.1では、FP16 (16ビット浮動小数点数) 精度に加えて、FP8 (8ビット浮動小数点数) 精度やINT4 (4ビット整数) 精度などの量子化モデルも提供されています。FP8量子化モデルは、FP16量子化モデルと比較して、メモリ使用量を約半分に削減することができます。また、INT4量子化モデルは、FP16量子化モデルと比較して、メモリ使用量を約4分の1に削減することができます。
SystemとしてのLlama 3.1 - 安全なAIシステム構築のためのツール群
Llama 3.1は単独で動作するようには設計されておらず、安全かつ効果的に機能させるためには、追加の安全対策を講じる必要があります。Metaは、Llama 3.1と組み合わせて使用することを推奨する、いくつかのツールやガイドラインを提供しています。
Llama Guard 3 - 安全でないコンテンツを検出
Llama Guard 3は、入力されたプロンプトと生成された応答を分析し、安全でない、または不適切なコンテンツを検出する安全対策ツールです。多言語に対応しており、様々な言語で記述されたテキストを分析することができます。Llama 3.1と統合することで、モデルが悪用されるリスクを軽減し、より安全なAIシステムを構築することができます。
Prompt Guard - プロンプトインジェクション攻撃を防ぐ
Prompt Guardは、プロンプトインジェクション攻撃を検出するためのツールです。プロンプトインジェクション攻撃とは、悪意のあるユーザーが入力プロンプトを操作することで、AIモデルの動作を改ざんしようとする攻撃です。Prompt Guardは、このような攻撃を検出することで、AIモデルの安全性を確保します。
Code Shield - 生成されたコードの脆弱性を検出
Code Shieldは、AIモデルによって生成されたコードの安全性を検証するツールです。AIモデルが生成したコードには、セキュリティ上の脆弱性が含まれている可能性があります。Code Shieldは、このような脆弱性を検出することで、安全なAIアプリケーションの開発を支援します。
Llama 3.1 を利用する
クラウドサービスからの利用

Llama 3.1は、主要なクラウドサービスプロバイダーを通じて利用することができ、これにより、開発者は独自のインフラストラクチャを構築することなく、Llama 3.1の強力な機能にアクセスすることができます。
Amazon Web Services (AWS): Amazon SageMaker JumpStartを通じて、Llama 3.1を簡単にデプロイし、利用することができます。
Microsoft Azure: Azure Machine Learningを通じて、Llama 3.1をクラウド上で実行し、スケーラブルなAIアプリケーションを構築することができます。
Google Cloud Platform (GCP): Vertex AIを通じて、Llama 3.1を簡単にデプロイし、カスタムAIソリューションを開発することができます。
これらのクラウドサービスプロバイダーは、Llama 3.1の利用に必要な計算資源、ストレージ、セキュリティを提供しており、開発者はAI開発に集中することができます。
Hugging Face Transformers
Hugging Face Transformersは、自然言語処理モデルを扱うためのオープンソースライブラリです。Llama 3.1もHugging Face Transformersでサポートされており、手軽にモデルをロードして利用することができます。Transformersは、PyTorch、TensorFlow、JAXなどの主要な深層学習フレームワークと連携することができ、様々な開発環境で利用可能です。
HuggingChatでLlama 3.1 405bを無料お試し
HuggingChatでLlama 3.1 405bを無料体験できます。画像生成はできず、テキスト生成のみになりますが、それでも405bの無料で体験できるのは非常にありがたいです・・・!
GroqでLlama 3.1 70bで高速チャット

Groqも早速Llama 3.1に対応していました!まだ8bと70bのみで、405bは未対応ですが、Llama 3.1の動作をGroqの超高速レスポンス環境で楽しめます!
最後に
最後までお読みいただき、ありがとうございます!
弊社では、LLM(大規模言語モデル)やアーキテクチャの選定、技術検証、生成AIを使用したプロトタイピングやシステム開発、お客様社内での啓蒙活動等を対応させていただく「生成AIコンサルティング」サービスを提供しています。
また、業務利用できるChatGPTのような仕組みである「セキュアGAI」や、生成AIとOCRを組み合わせた「AI文書読み取りサービス」といったAIソリューションも提供しています。
ぜひお気軽にお問い合わせください!
この記事は私が経営する株式会社スクーティーのコーポレートブログの下記記事を焼き直したものです。
この記事が気に入ったらサポートをしてみませんか?