「Aesthetics Versus Readability of Source Code」 要約

「Aesthetics Versus Readability of Source Code(ソースコードの美学対可読性)」- Ron Coleman, 2018 という海外の論文を読んだため、日本語で要約してみました。こちらが原文のurlになります。https://thesai.org/Publications/ViewPaper?Volume=9&Issue=9&Code=IJACSA&SerialNo=2
かなり難解な部分もあるので、興味のある方は読み飛ばしながら読んでみてください。笑
Introduction(導入)
1979年にCの美化器であるcb(C Beautifier)が含まれるUnix ver7がリリースされた。cbはK&Rスタイルに従ってプログラムを再フォーマットし「美化」したが、cbはコードの美しさとはなにかという存在論には触れずに、より実践的に美しさについて知ることができるものは何かという認識論に焦点が当てられた。cbの導入において期待されたのはコードにおける感性的、美的価値に焦点を当てることでコードの可読性も向上することであった。
このように、美学と可読性が交換可能であると考えられることはよくある(例:「リーダブルコード」 - O'Reily, 2011)。これらにおける問題はいくつかあるのだが、まずこの見解が帰納的に検証されたことがないこと、そして存在論的に検証されたことがないことである。そもそも可読性とは「コードを理解すること」であり、美学とは「コードを評価すること」であるので、それらを混同するのはカテゴリーミスである。また、異なるスタイルがコードの理解の容易さにどう影響するのかは充分に理解されてはいない。プログラマーは好みによってあるスタイルの方が他のスタイルよりも読みやすいと仮定するが、それらはデータに裏付けられてはいない。
この論文ではプログラミングスタイルの「美的ファクター」を研究し、以下の二つの仮説を提示する。
①美しさが増すほどコードは読みやすくなる傾向がある。
②美しさは可読性とは異なるコードの美的価値と呼ばれるユニークな特性を測る。
これらは統計的に意味のある数のファイルの「美しさ」と「可読性」のスコアを評価し、相関関係を分析することで検証される。無相関は①の仮説を否定し、強い相関は②の仮説を否定するので、弱または中程度の相関がある場合のみ両者が論理的に真であると言える。論理的に真であるならば、コードの美的価値とは可読性と直交するものでも代替するものでもなく、「可読性のあるスペクトル」であるということになる。
Realated Work(類似研究)
- プログラムに文字やトークンに相関があることがしめされた - Kokol, et al
- プログラムのスタイルがフラクタルと関連していると主張 - Coleman, Gandhi
- 美しさはエントロピーと弱〜中程度の反相関があると示す - Coleman, Boldt
- 美的モデルが科学的ライブラリの美的価値を予測する - Coleman, Rahtelli
- 「Beautiful Code」 - O'Reily
Theory(前提論)
A. 美学理論
1) 定義
美学は古代からスタイルや好みの問題についても多く議論されてきた。スタンフォード哲学百科辞典によると、「美的」という単語は美、魅力、観賞、美徳、善良さなどと呼ばれる一種の経験的な判断や価値を指している。「美的判断」という言葉を使うときは、他の表現とは異なり感覚的、感情的な判断を指す。私たちがコードを「美しくする」というとき、レイアウトや構造の面で経験に従ってそのスタイルを測定可能な限り向上させることであるが、これは「美しい」という語の歴史的定義の特別なケースである。
2)コードに適用される即時性と非利益のテーゼ
即時性のテーゼ:美的判断は感覚的な見分けであるため即時的であると主張される。その機能を「読む」「理解する」ことを試みることなく、つまり最終的にどのように見えるかだけでそのスタイルを評価できる可能性を示唆している。
非利益のテーゼ:表現の評価は「芸術のための芸術( l'art pour l'art )」に倣い、自己利益的でないと主張される。コードにおいてもプログラマーはK&Rスタイルといったスタイルのルールに「知的及び感情的な満足」を得て感謝する。
3)基本的な教義
美しさのモデルはプログラマーがどのように考えているのか、彼らがスタイルについてどのように感じているのかを認識論的に知っている、あるいは知ることができるかを前提としている。これらの知識は様々な活動で体系的に繰り返し観察することで習得する。
また、観察的研究においてはColemanとGandhiがこの知識ベースを調査し、彼らが「良いプログラミングスタイルの基本的な原則」と呼ぶ3つの一般原則を特定した。それは①空白を慎重に使用する、②ニーモックな名前を選択する、③ドキュメントを含めることである。
4)美のファクター
美のファクターの計測について、意味論的な維持を行いつつソースの様式を変形させることで研究を行う。


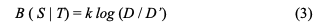
S: ソース
T: 様式
D: フラクタル次元
r: 細網細胞カウンティング
Nr(S): コンポーネント数
B: 美のファクターモデル
もし、Bが0より小さいならSはTによって改善されたと言え、大きいならそうではないといえる。
5)意味論的保存変換
研究に利用するスタイルは、GNUスタイル、K&Rスタイル、Linuxスタイル、それらからインデントを除いたものや、インデントをランダムに変えたものや、コメントを除いたものなど計11種類を用いる。上: 美化様式、下: 脱美化様式


6)BAM
この研究においてはソースコードを■ブロックに変換する(BAM)ことで、フラクタル分析を行う。その目的は、言語的依存性を除去することにある。


B. 可読性理論
プログラム理解に関する文献では、理解階層を介してコードを理解することに認知的負荷がかかることを前提とする。理解性の「ボトムアップ理論」はコードを理解するための最初のステップはコードを読むことであり、そこからプログラムの流れ、組織のテーマ、抽象化、設計パターンなどの高次のメンタルモデルに発展するとしている。可読性モデルでは、認知的負荷は測定可能であり、演算子や被演算子の密度、論理の複雑さ、行数などと関連していると考えている。
つまり、可読性モデルはプログラム理解の最初の一部ではあるが、いくつかの側面をキャッチしていると言える。可読性の研究は歴史的にHalsted統計、機械学習型、散文型の3つの視点から行われてきた。
1)Halstead統計
Halsteadは体積やガス圧などの物理量と関連づけてプログラミングの労力を予測することに興味を持っていた。その結果以下のモデルを提示した。
Nモデル: 演算子N1と非演算子N2の合計
nモデル: ユニークな演算子n1とユニークな非演算子n2の合計
V(Volume)モデル: N logn
Df(Difficulty)モデル: N1 * n1 / 2 * n2
E(Effort)モデル: Df * V
2)機械学習型
BWモデル: BuseとWeimerはHalstead統計を人間の判断に関連づけるために、教師付き機械学習を使用した。
PHDモデル: その後Posnet、Hindle、DevanbuがBWモデルを改良したモデルを提示した。
3)散文型
SRESモデル: 散文の可読性スコアに触発され、平均文長や平均語調から新たな可読性モデルが提示された。
4)全モデル
可読性モデルは全てで8つのモデルに分解される。

METHODS(方法)
実験は非常にシンプルで、各ファイルの美しさと可読性のスコアを生成し、相関関係を分析するというものである。
A. C言語
実験はC言語を用いて行われる。C言語が最も広く使われている言語の一つであり、また他の多くの現代の言語デザインがC言語から影響を受けていることが理由である。
B. 言語集積
Cプログラムを全て直接使うことはなく、プロトタイプや型定義、著作権表示などを削除し、残りを1043個の単機能Cファイルに分解する。このようにすることで研究を単純化し、JavaやPythonなどのC言語に似た言語にも一般化できると考えられる。
C. フラクタル次元
フラクタル次元を推定するために、元々神経組織画像の分析に使用されていたFractopというライブラリを利用する。
D. 結果の基盤
前述のとおり美しさの様式が11、可読性のモデルが8つあるので、これらの組み合わせでスコアを計測する。美学自体や可読性自体を研究しているわけではないため、相関係数のみを計算する。
E. 統計的手法
正規性のKolmogorov-Smirnov検定を用いた結果の分析は、美しさ因子と可読性スコアの分布がガウス分布ではないため、代わりにSpeamanのrhoを用いる。相関の強さについては以下の絶対値指標pを用いる。
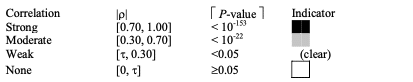
F. コード解析コード
コードを分析するコードはGithub.comで公開され、また残りの統計的部分はMicrosoft Excelで実装されている。
RESULT(結果)
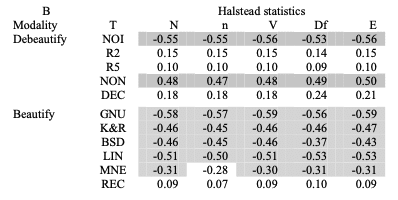
A. 美とHalstead統計
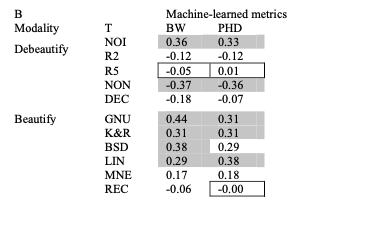
B. 美と機械学習型
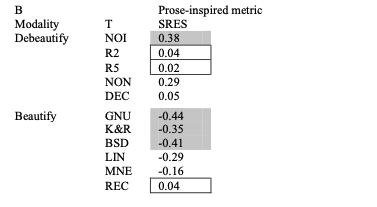
C. 美と散文型
DISCUSSION(議論)
表のデータパターンを要約する。
A. 弱から中程度の相関
表から明らかなように、美しさと可読性は統計的に優位な方法で関連している。また、NOI(インデント除去)とREC(コメント付与)を除いておおむね脱美化処理はHalstead統計と正の相関をもち美化処理は美しさと可読性は負の相関を持つため、仮説①「美しさが増すほどコードは読みやすくなる傾向がある」は支持される。
B. 強い相関の欠如
表のなかには強い相関は見られない。統計的に有意な相関の範囲から美しさのばらつきの少なくとも65%は可読性のばらつきでは説明できないということになり、また代表的な相関の中央値はから美しさのばらつきの10%未満のみが可読性のばらつきで説明できるということになる。これは仮説②「美しさは可読性とは異なるコードの美的価値と呼ばれるユニークな特性を測る」を支持する。
C. 無相関の頻度
無相関が少々見えるが、それらは統計的に有意ではない。
D. 反例指標としてのNOI(インデント除去)
NOIは断定的には脱美化ソースではあるが、統計的には美化ソースのように振る舞っている。ここからは1つの洞察が導かれ、NOIによって多くのテキストが左端に収集されることで表面領域が減少するため、可読性と正の相関が生まれているということだ。
E. 反例指標としてのREC(コメント付与)
コメントが付与されることで、Hastead統計においては可読性の低下を示している。ただし、機械学習型や散文型では統計的に有意ではない。
F. R2(ランダムインデント1-2)やR5(ランダムインデント1-5)
NOIやRECとは異なり、R2やR5の相関は仮説に沿っている。
G. 自己文書的コード
ニーモニックは自己文書化の一形態である。MNE(ニーモニックリファクタリング)のデータはRECよりもニーモニックがスタイルを改善するためのより良いアプローチであることを示される。つまり、少なくとも美学が懸念される限りでは「コメントなし」が支持される。
H. ホワイトスペースによる可読性の向上
GNU、K&R、BSD、LINなどが一貫して可読性の向上に貢献していることから、ホワイトスペースがMNEやRECつまり、ニーモニックやコメントよりも強く可読性と相関関係を持つことを示している。
I. より可読性の高いGNU
K&R、BSD、LINに比べてGNUスタイルが可読性スコアが高く統計的に優位であった。
CONCLUSIONS(結論)
結論として、美の変化の幾らかは可読性の変化によって説明できるが、ほとんどはそのように説明できないことが示唆されていた。言い換えれば、美しさと可読性は関連しつつも、美しさは美的魅力と呼ばれるコードのユニークな特性を測定している。
さらに、データはインデントがニーモニックやコメントよりも可読性と確実に相関しており、4つのスタイルのうちではGNUスタイルが最も可読性と相関していることを示していた。
今後の研究では異なるリポジトリ、異なる言語、異なるスタイルについてこれらの知見を確認する必要がある。
この記事が気に入ったらサポートをしてみませんか?