
NotebookLMに論文を食わせて質問攻めにしてみた

1. NotebookLM日本公開!
GoogleのGeminiベースのサービスであるNotebookLMが日本でも利用可能になったので、早速触ってみた。

NotebookLMについて簡単に説明しておくと、こちらが提示したソースに従って情報の抽出や要約、議論ができるサービス。これが必要とされる背景として、生成AIを検索サービスに絡めると、LLM一般で問題とされるハルシネーションだけではなく、Redditなどに落ちてる真偽不明な情報に引っ張られるという問題があって(代表例としてGoogleのAI Overviewで「ピザに接着剤を入れる」など)、その対策として、アップロードしたソースの中のみから情報を抽出するサービスを作ったというイメージ。
自分で書いた文章じゃないと何の情報が書かれているか定かではなくなるので、今回は実験として今年僕が書いた論文やpreprintから3本:
J. Niimi (2024a) “Multimodal Deep Learning of Word-of-Mouth Text and Demographics to Predict Customer Rating: Handling Consumer Heterogeneity in Marketing” arXiv (cs.CE.), e-print: 2401.11888. https://doi.org/10.48550/arXiv.2401.11888
J. Niimi (2024b) “An Efficient Multimodal Learning Framework to Comprehend Consumer Preferences Using BERT and Cross-Attention”, arXiv (cs.CE). e-print: 2405.07435. https://doi.org/10.48550/arXiv.2405.07435
新美 潤一郎 (2024) 「異なる次元数のデータを同時に投入した行動的ロイヤルティ推計手法の提案 —Source-Target Attention Transformer と特徴融合によるマルチモーダル深層学習—」『応用統計学』53(1). pp. 15-32. https://doi.org/10.5023/jappstat.53.15
を使ってみることに。いずれも基本的にはマルチモーダル学習で消費者の行動予測や嗜好の把握を行うもので、マルチモーダルにはオンライン上のレビュー文章を使うものもあれば行動ログを使うものもある。
問1. 3つの資料の共通点
まず最初にやりたいのはやっぱりこれですよね。大量の文献から共通点と相違点を抽出できたら本当に便利。
この3つの論文はいずれも深層学習を使って顧客の行動を予測した論文です。この3つに共通して使われている手法はありますか?

まあ、最新のarXivの論文では特徴融合は比較モデルとして使われてるだけで、メインはCross-Attentionなんだけどねー。
この注釈[1]とかを押すと各ソースの中での根拠の記述に飛ぶ。似たようなのでPerplexityがあるけど、パープレだと出典になった文献を示すだけなので中身は自分で探さないといけなかった。
生の原文を参照していることもあれば、NotebookLM側で自動的に作ったソースガイド(概要)に参照が貼られていることもある。


この辺はかなりいいまとめになってますね。
ちなみに、3つのうち2つの論文における共通点(データセット)についても一応考えてくれました。…「3つのうち2つの」とか明示してくれるとありがたいんだけどね。

問2. 比較モデルについて
モデル自体も大事だけど、僕らの分野でそれ以上に大事なこととして、何と比較した場合について議論しているのかというのがある。なのでその辺についても聞いてみる。
この論文では提案モデルの有用性を示すためにどんな参照モデルと比較を行なっていますか?

かなり分かりづらくなってるけど要約は一応できている。
NotebookLMおもしれー(自分の最近の論文を食わせて質問攻めにしてみた)
— Jun, "Jack" N.🐾 (@JvckAndersen) June 7, 2024
自分の論文だから分かるけど、書いてないことはちゃんと書いてないって言ってくれるねえ pic.twitter.com/ddBJtsW5Yy
なかなかおもしろい。
問3. ちょっとメタ的な質問
せっかくなので直近10年の論文を全部食わせた上で、論文の内容ではなく著者に関する質問をしてみた。
これらの論文はいずれも新美 潤一郎 (Junichiro Niimi) による論文です。新美はどのようなことを専門とする研究者ですか?
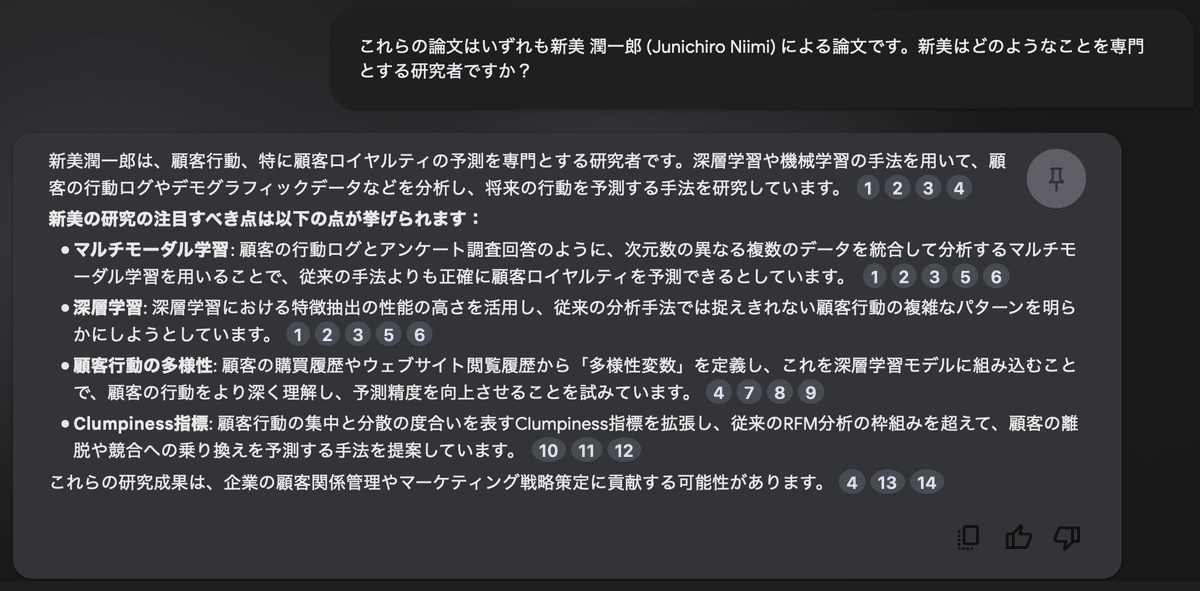
専門分野としてはそれなりに正しそうですね。ただ、人工知能学会の論文の「特徴抽出の高さを活かして」というのは統計解析と比較した場合に限る話で、どちらかというと「現状の特徴抽出だけで何もかも考慮できるわけではないので人間が作った特徴量も組み合わせて初めて最良なモデルになる」って話なんだけどねー。
これらの論文の所属をもとに、新美の過去の学歴や職歴を可能な限りまとめて時系列順に示してください。

あー、これは人工知能学会論文誌の最後に載ってる著者経歴だけですね。

ソースガイドあたりを見てもわかるんだけど、これはどうもRAGの時点で情報を落としちゃった可能性がありますね。Xで誰かも言ってたけど、所詮はRAGベースでやってるだけだから、有料版にしてちゃんと全文検索できるようにしてほしいですねー。
他の論文で試す
いま書いている論文ではいよいよ計算言語学(computational linguistics)に片足を突っ込みつつあり、手法自体の勉強は一通りしたとはいえ、いざ論文の体系的なレビューとなるとまた話が変わってくる。センチメント分析は辞書(lexicon)を用いたルールベースの手法、機械学習手法、ディープラーニング、LLMと手法が日々多様化していて、全部レビューするのはかなり大変だったりする。
たとえばルールベースの代表手法であるVADER、SO-CAL、RubEの提案論文とレビュー論文2本を突っ込んで特徴をまとめてもらうと、

もちろんこれで完全とは全く思わないけど、レビューの足がかりにするにはかなり有用だと思う。
使ってみた所感
使ってみてまず思ったのは、原文になるべく忠実に文章を生成しようとする(しすぎる)ことにより、要約というよりはあくまでも情報抽出っていう感じ。とはいえ、ソースとして指定する文書を増やしたり、そもそもソースの分量が多くなればもう少し自然な文章になりそうな感じもある。ともかく該当する箇所を明示してくれるのがかなり便利ではある。
これだけ文書内からの情報のretrieveが簡単になるなら、もしかすると今後は論文での引用でももっと細かく出典元の具体的にどの部分を引用したのか、たとえば本の引用だと(Niimi, 2024; p.100)とかよくやるわけで、ああいう感じでより具体的に示すようになる時代が来るかもなあ。
多くの方は既に実感として持っていると思うけど、LLMだと言及されていないことでも自分で勝手に考えて提示してくることがよくある。特に、LLMが出してくる追加的な意見というのは多くの場合に大したことのない一般論ばかりで参考にならなくて、そんな程度のことなら長文でだらだら書かずにさっさと切り上げてくれよと思うことが結構ある。
そんななかで、NotebookLMは書いていないことにはちゃんと言及されていないと返してくるし、これがかなり重要なんじゃないかと思う。
だから、先にも書いたとおり大量の文書から情報を抽出するのに有用で、これは論文のレビューが相当捗る。活用例でいうと特にこれ(https://note.com/genkaijokyo/n/nb4ab0d79b2b2)とかね。
ただ勘違いしてはいけないこととして、こういう便利なものが次々出てくることで僕らの生活が楽になるかというとそんなことは全くなくて、今まで以上に「まだ読んでません」が許されない時代が来るだけなんじゃないかと思っている。歴史的にみても省人化は一個人が負うべき責任の範囲を増やし続けてきたし、今までは週1冊読んでれば許された勉強量が週7冊になるだけなんじゃないかな。
本当はもうちょっと質問責めにしてるんだけど、いままさに学会運営中でちょっと文章に起こす余裕がないので、また追記するつもりです。
この記事が気に入ったらサポートをしてみませんか?