Deep Learningのフレームワーク、どれを選んだらいい?~なぜ研究者はPyTorchが好きなのか~

この記事はCA22のadvent calendar 2021の記事です。
https://adventar.org/calendars/6671
はじめに
この記事は機械学習とdeep learningに興味があるけどまだ全然手を出していないかあまり手を出していない方向けです。
Deep learningに興味があって手を出してみたい人はまずdeep learning用の環境を用意しないといけないです。一番重要なものはdeep learningのフレームワークです。世の中には色々なdeep learningフレームワークがあるから、どれを選んだらいいのか迷う人がたくさんいるでしょう。この記事ではメジャーなフレームワークを紹介して、それぞれのメリットとデメリットについて書きたいと思います。
Deep learningフレームワークとは?
まず、deep learningフレームワークって一体何なのかと、あまりわからない人もいるかもしれません。それを理解するためにdeep learningは何なのかを理解する必要があります。Deep learning(深層学習)は機械学習の一種です。Deep learningのシステムの中身は、簡単に言うとたくさんの関数とパラメータでできています。それに、目的関数を最小化、あるいは最大化するために、普段微分によってパラメータを最適化する必要があります。Deep learningフレームワークでは、中身の数学関数を簡単にプログラミング言語で定義するための関数や、deep learningモデルの構築やデータの前処理や後処理に役立つ関数などが入っているライブラリです。
メジャーなフレームワーク
世の中にはかなり多くのdeep learningフレームワークがあります。まずは、現在人気なフレームワークと昔割とメジャーだったフレームワークをいくつか単簡に紹介します。
TensorFlow
現在、使用率が一番高いフレームワーク。Googleによって開発されている。
PyTorch
TensorFlowの次に一番人気なフレームワーク。特に研究者の中で人気。Facebook AI Research Lab (FAIR)によって開発されている。
Keras
独立したフレームワークではなく、普段のモデル構築と学習をより単純化するAPI。TensorFlow 2.0以降からTensorFlowにも含まれている。バックエンドフレームワークはTensorFlow以外にTheanoもCNTKも対応されていたが、マルチバックエンド対応は終了した。Googleのリサーチャー・エンジニアFrancois Cholletによって開発された。
MXNet
Amazonが主に使っているフレームワーク。今はAWSとMicrosoftが開発したGluonというKerasのようなhigh-level APIも提供されている。
CNTK
Microsoftによって開発されたフレームワークだが、人気が出ず開発終了。
Chainer
PFNが開発したフレームワーク。昔、日本で人気1位を争ったと思われる。海外でも一部の研究者が使っていた。TensorFlowやTheanoではすべての計算グラフを事前に構築してから実行していたが(Define-and-Run)、それと違ってChainerでは都度必要な計算グラフだけを構築して即座に実行する動的な計算グラフが使われている(Define-by-Run)。そのおかげ、もっと柔軟にモデルを構築できて、複雑な仕組みのモデルも実装しやすい。今人気なPyTorchも最初から動的な計算グラフを使っていて、Chainerが参考になったと明言されている。Define-by-Runは今TensorFlowやMXNetでも使われている。PFNが開発者とユーザーコミュニティがより多いPyTorchに移行するため2019年に開発終了。
Theano
2007年からモントリオール大学で開発されていた数値計算ライブラリ。2015~2016年くらいまでよく使われていたけど、TensorFlowやPyTorchなどの企業が開発した新しいフレームワークのブームのため、開発を継続する必要がないという判断によって2017年に開発終了。
Caffe
2013年辺りに公開された、UCバークレーのフレームワーク。開発が終了している。
Caffe2
Facebookが2017年に発表したCaffeの進化版。2018年にPyTorchに統合された。
Sonnet
DeepMindによる複雑なネットワークを簡単に構築できるためのTensorFlowの高水準ライブラリ。
PaddlePaddle
バイドゥのフレームワーク。コミュニティはほとんど中国圏だけど、多くの人気なモデルを提供しているし、バイドゥの新しいSOTAのモデルがPaddlePaddleで書かれているから、英語圏でも認知された。
今一番使われているフレームワークはほとんど2015年以降に公開されたものです。2015年以前のフレームワークは大体大学の研究施設で開発されたものだったが、2015年以降はAIのブームのためITの大企業が開発の中心になりました。

https://www.researchgate.net/publication/349108714_DLBench_a_comprehensive_experimental_evaluation_of_deep_learning_frameworks
フレームワーク選び
フレームワークを選ぶときに、とても重要なのがそのフレームワークのユーザーコミュニティです。コミュニティが小さいフレームワークだと、バグやエラーで困ったときにかなり解決しにくいです。そのため、コミュニティが大きいフレームワークを選んだ方が無難です。また、Githubなどでコードを公開する予定であれば、コミュニティが大きいフレームワークだと他の人が使ったりフォークしたり星を付けたりするチャンスがマイナーフレームワークより大きいです。
かなり古いけど、2018年のユーザーデータを見てみると、TensorFlow、KerasとPyTorchが一番人気だとわかります。

https://towardsdatascience.com/deep-learning-framework-power-scores-2018-23607ddf297a
さらに、2019年の成長のスコアとArXivの論文の実装のデータを見ると、PyTorchの使用率が上がってることが確認できます。


ユーザーコミュニティのサイズを踏まえて、今から機械学習に手を出してみたい人はTensorFlowかPyTorchかKerasを選ぶべきです。
しかし、KerasはTensorFlowの高水準APIなので、結局の所、TensorFlowかPyTorchかという二択になります。
TensorFlow
Googleによって開発されて、2015年に一般公開されたフレームワークです。
昔はDefine-and-Runの静的計算グラフしかなくて、複雑なモデルが作りにくかったです。しかし、より柔軟にモデル構築ができるためにPyTorchなどで使われている動的な計算グラフが求められて、TensorFlowにもeager executionという名前でオプションとして導入されました。
2019年に公開されたTensorFlow 2では動的な計算グラフがデフォルトになりました。
しかし、今もPyTorchの方が使いやすいと思います。単にPyTorch慣れてるからそう思う可能性もあるけど、学習ループのコードはPyTorchの方がシンプルでわかりやすいと思います。
メリット
公開されたときからプロダクション重視で、学習済みモデルを簡単にデプロイするために色々なツールが提供されている。
学習が速い。
低レベルな変更もできる。
エコシステムが充実している。
TPU(Tensor Processing Unit)で学習できる。
デメリット
Kerasのラッパーを使わない場合、重み、バイアスなど、色々自分で定義しないといけないのでコードが少しややこしくなる。(Keras使えばいいだけの話だが)
若干デバグしにくい。TensorFlowのsessionかdebuggerを使わないといけない。
多くのモデルが公開されているが、PyTorchの方がより多い。
Keras
2015年にTheanoとTensorFlowの高水準APIとして公開されました。その後、CNTKやMXNetのバックエンドも対応しはじめたが、今はTensorFlowの一部としてTensorFlowのパッケージに含まれていて、他のバックエンドは対応していません。
メリット
簡単なAPI。シンプルなモデル構築と学習をする場合は、生のTensorFlowより書きやすい。
ドキュメンテーションがわかりやすくて、サンプルコードも多い。
デメリット
複雑な仕組みのモデルや、特殊な学習方法を使いたい場合は、TensorFlowで書かないといけない可能性がある。
たまにTensorFlowより遅いことがある。
PyTorch
Facebook AI Research (FAIR)で開発されて2016年に公開されたフレームワークです。最初からDefine-by-Runアプローチを使っていて、複雑なモデルも当時TensorFlowより書きやすかったため、新規なモデルや学習方法の研究をしていた人が特にTensorFlowよりPyTorchを使うようになりました。Define-by-Runのおかげで実行中も色々変更することができます。
TensorFlowよりpythonicな書き方が使われていて、そのおかげもコードがTensorFlowよりわかりやすいと思います。
シンプルなことがやりたいときは、Kerasのような高水準ラッパーPyTorch Lightningが使えます。
メリット
柔軟性が高い。かなり低レベルでも色々いじることができる。
シンプルなことを簡単にやる方法も提供されている。
デバグしやすい。普通のPythonのコードと同じようにデバグできる。
学習が速い。
TensorFlowよりPythonらしい書き方。OOP性が強い。
多くのモデルがネットで公開されている。
TPUで学習できるようになった。
デメリット
最初はあまりデプロイに注目せず、デプロイ用のツールの開発がTensorFlowより遅れていて、TensorFlowの方が優れている
エコシステムが充実しているが、TensorFlowの方がより充実してる。
コード比較
学習ステップ・ループのコードのサンプルの比較。
まず、TensorFlowのtraining step関数。自動微分のためのtf.GradientTapeが使われています。Optimizer.apply_gradients()で計算されたgradientを使ってパラメータを更新します。
デコレーターのtf.functionでTensorFlowのグラフにコンパイルされて最適化されます。
@tf.function
def train_step(x, y):
with tf.GradientTape() as tape:
logits = model(x, training=True)
loss_value = loss_fn(y, logits)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
train_acc_metric.update_state(y, logits)
return loss_valuePyTorchはシンプルなダブルfor-loop。Outer loopは学習のepoch数。Inner loopはデータローダーを使ってtraining batchをロードします。Backward関数で微分を行います。Optimizer.step()ですべてのパラメータを更新します。
for epoch in range(num_epochs):
for i, (data, labels) in enumerate(train_loader):
# Zero the parameter gradients
optimizer.zero_grad()
# Converting to CUDA parameters if using GPU
data = data.to(device=device)
labels = labels.to(device=device)
# Forward propagation
output = model(data)
loss = criterion(output, labels)
# Backward propagation
loss.backward()
optimizer.step()研究界隈ではPyTorchが優勝
TensorFlowがPyTorchの先に公開されたが、静的計算グラフを使っていたため、複雑なモデルや特殊な学習が実装しにくくて、学習ループや低レベルなコードが少しややこしかったです。
PyTorchが最初から動的計算グラフを使っていて、多くの人が求めてた柔軟性がありました。その上、学習ループのコードの書き方もTensorFlowよりわかりやすくてpythonicアプローチに忠実でした。
TensorFlowの問題を解決して、より柔軟性のあるフレームワークを提供するために、2019年にTensorFlow 2が公開されました。しかし、TensorFlow 2がTensorFlow 1より柔軟で書きやすいフレームワークになったのに、PyTorchへの移行の勢いが強すぎてそのまま続きました。
以下のグラフがML, CV, NLPのトップカンファレンスに採択された論文の実装のPyTorchとTensorFlowの比率を表しています。2018年はPyTorch率が25~50%だったけど、2020年からは70~90%くらいに上がってます。
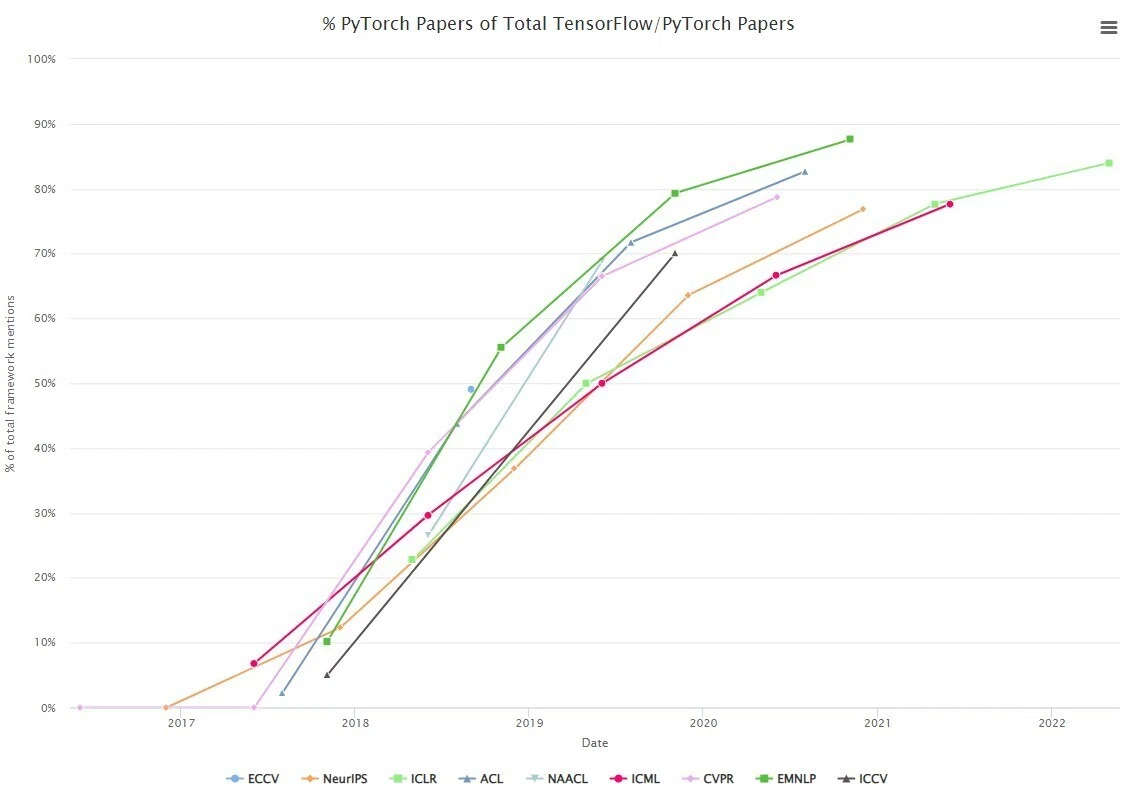
http://horace.io/pytorch-vs-tensorflow/
2018年にTensorFlowを使って論文を出した研究者の55%が2019年にPyTorchを使って論文を出しました。一方、2018年にPyTorchを使っていた研究者の85%が2019年にもPyTorchを使っていました。TensorFlowからPyTorchへの移行のトレンドが確認できます。

https://www.assemblyai.com/blog/pytorch-vs-tensorflow-in-2022/
Papers with Codeという論文実装のデータベースでもTensorFlowからPyTorchへの移行が見られます。

https://paperswithcode.com/trends
最後に
PyTorchもTensorFlowも非常に優れたdeep learningフレームワークです。両方とも多くの人によって開発されていて、メンテナンスされていて、ユーザーコミュニティもとても大きいです。
プロダクション目的で、モバイルやウェブアプリなどに使ってみたかったら、デプロイしやすいTensorFlowの方が適切かもしれません。
SOTAのモデルを触ってみたければ、ほとんどがPyTorchだからPyTorchを勉強した方がいいでしょう。
この記事が気に入ったらサポートをしてみませんか?