
GPT-4で社会人基礎力(経産省)をもとに日報を評価できるか?

1.目的
「社会人基礎力」とは、「前に踏み出す力」、「考え抜く力」、「チームで働く力」の3つの能力(12の能力要素)から構成されており、「職場や地域社会で多様な人々と仕事をしていくために必要な基礎的な力」として、経済産業省が2006年に提唱したものです。
2018年には、「新社会人基礎力」が再定義され、今までの社会人基礎力に加えて、「目的」「学び」「組合せ」の3つのバランスをとることが、重要であると提唱されています。



(株)リフレクトの提供する、リフレクトは、システム上で日報を書くことができ、ChatGPTのAIコーチが日報に対してアドバイスや問いかけをすることで、従業員のオンボーディングや業務効率化をサポートします。
従業員の書く日報に対して、質を定量化できれば、自分の強み・弱みを把握して、日々の行動を変えていくことができます。
しかし、日報を人間が毎回複数指標にて評価することはコストや時間の観点で厳しいのが現実です。
そこで、ChatGPTで人間の代わりに日報を評価ができるのならば、日々の人の成長を可視化でき、成長を加速できるのではないかと考え、検証することにしました。
2.検証ステップ
まず、12の能力を評価するためのルーブリック設問を用意しました。各設問で1〜5段階尺度で定義されています。

次に、リフレクトの振り返りデータから、研究の許諾が得られているものから100サンプルをランダムで抽出。振り返りデータは、出来事・学び・アクションのセクションに分かれて書かれています。
そして、日々の振り返りデータについて、ルーブリックを参考に、「主体性」「課題発見力」「柔軟性」について、人間(私と、弊社石川)が5段階尺度で評価、さらにGPT−4を用いて5段階尺度で評価させました。
イメージは下記の通りです。実際には、評価者がお互いに影響を受けない様に、GPT-4、三好、石川の評価は別々のデータテーブルに記述していき、最後にデータを統合しています。
※今後、検証のためのサンプルサイズは増やしていく予定です。
※人間が評価をすると、初めの方につけていた際の尺度や後の方でつけていた尺度が変わっていったり、疲労で評価精度が変動することも実感しました。日報の内容を見ながら、ルーブリック設問の基準と照らし合わせながら評価するのはかなり骨が折れます。

3.精度検証
・まず、基礎集計として平均値と標準偏差を比較したところ、主体性でGPT-4が高め、課題発見力は三好が高め、柔軟性は石川が低めという特徴がありました。標準偏差を見ると明らかに三好はばらつきが高い傾向です。
マン・ホイットニーU検定を使用したところ、有意差がそれぞれの指標でありました。
GPT-4と人間の間でも差がありますが、三好と石川の間でも同じ評価基準があるものの差があるという結果でした。

次に、GPT-4、三好、石川の3指標における評価の相関係数を見ていくと、GPT−4と人間の評価の相関係数はおおよそ0.4−0.6でした。
・今回は載せていませんが、 GPT-3.5と人間の評価の相関係数よりも、GPT-4と人間の相関係数の方が高い結果でした。
・傾向として、人間同士の方が、人間・GPT-4の組み合わせよりもやや相関が高い様です。
・また、GPT−4との相関は三好よりも石川の方が高い傾向でした。仮説ですが、今回私は若干疲労している中評価していたため、もしかするとキチンと評価をしている石川の方が相関係数が高くなっているのかもしれません。

・ちなみに、課題発見力における石川とGPT-4相関係数0.64ですが、クロス集計をしてみると下記の様になります。5段階尺度のうち、±1の範囲に98%が収まる形になっていました。

次に弊社開発チーム8名、237件の振り返りデータを抽出して、GPT-4にて指標化させました。そして、それぞれの指標間の相関係数を確認しました。
柔軟性と、傾聴力は、振り返り内容から推計されることがやや少なく、サンプルサイズが小さかったため、除外しています。
・すると比較的、大カテゴリ内での相関が高いことが確認できました。前に踏み出す力の中では、主体性と実行力が0.67、考え抜く力の中では課題発見力と計画力が0.6、チームで活躍する力の中では、状況は握力と規律性が0.62。
・前に踏み出す力の中にある、働きかけ力はチームに関係する項目のため、状況は握力や規律性と相関が高めに出ているのは、整合が取れていそうです。

4.評価結果
では、ある程度人間の評価と相関がある、GPT-4による社会人基礎力の推計値をどのように使えばよいのでしょうか?
引きつづき、開発メンバーにおいての事例で見ていきます。
一つは、メンバー別に集計をして、強み・弱みを分析し、各個人の強みを活かしたり、改善ポイントを明らかにし改善をしていくことです。
例えば、A-Eさんまでを比較して見てみると、主体性がチーム全員高いのはよいことです。また、Aさん以外は、エンジニアで個人的なタスクを行なっており、各個人において課題発見をし、規律を持って実行できているのはよい点です。しかし、個人商店的になっているためか、現状働きかけ力が低いのが課題です。今後、チームワークが必要とする場面が増えていくので、「働きかけ力」を改善する必要があるという課題を可視化できました。

もう一つの使い方は、個人別に時系列変化を見ることで、能力のモニタリングをし、成長に活かすという使い方です。
下のダッシュボードをみると、Bさんは、6月になってから振り返りの文字量がだんだんと増えていき、それに伴い実行力、課題発見力、計画力、言語化力など上がっていく様子が確認できます。Bさんは元外資系銀行出身であり、弊社環境に慣れ始めてからそのポテンシャルを発揮されているのがわかります。ただ、この中で言うと「働きかけ力」はまだ伸ばせる余地があるため、本人とディスカッションをして伸ばしていこうと思っています。
なお、振り返りに、職種として傾聴力の「人の話をよく聞いた」などの話が出にくかったり、人との折衝が少ない職種では意見の違いや立場の違いを理解する力「柔軟性」について出にくかったりと、記述が少ない評価項目は推計されないこともあります。各人の環境、その職種にとって必要なスキル、強み弱みを勘案して、データを見ながら能力を伸ばしていくのがよいかと思います。

Aさんの場合は、5/31、6/6は体調を崩しており、その分振り返りの文字数も少なく、その日は評価が低くなっています。Aさんはマネジメント・営業系のタスクを行なっており働きかけ力は他の人に比べて評価されています。一方、振り返りが事実ベースに終始しているものが多く、創造力が低いことが課題であることが可視化できました。
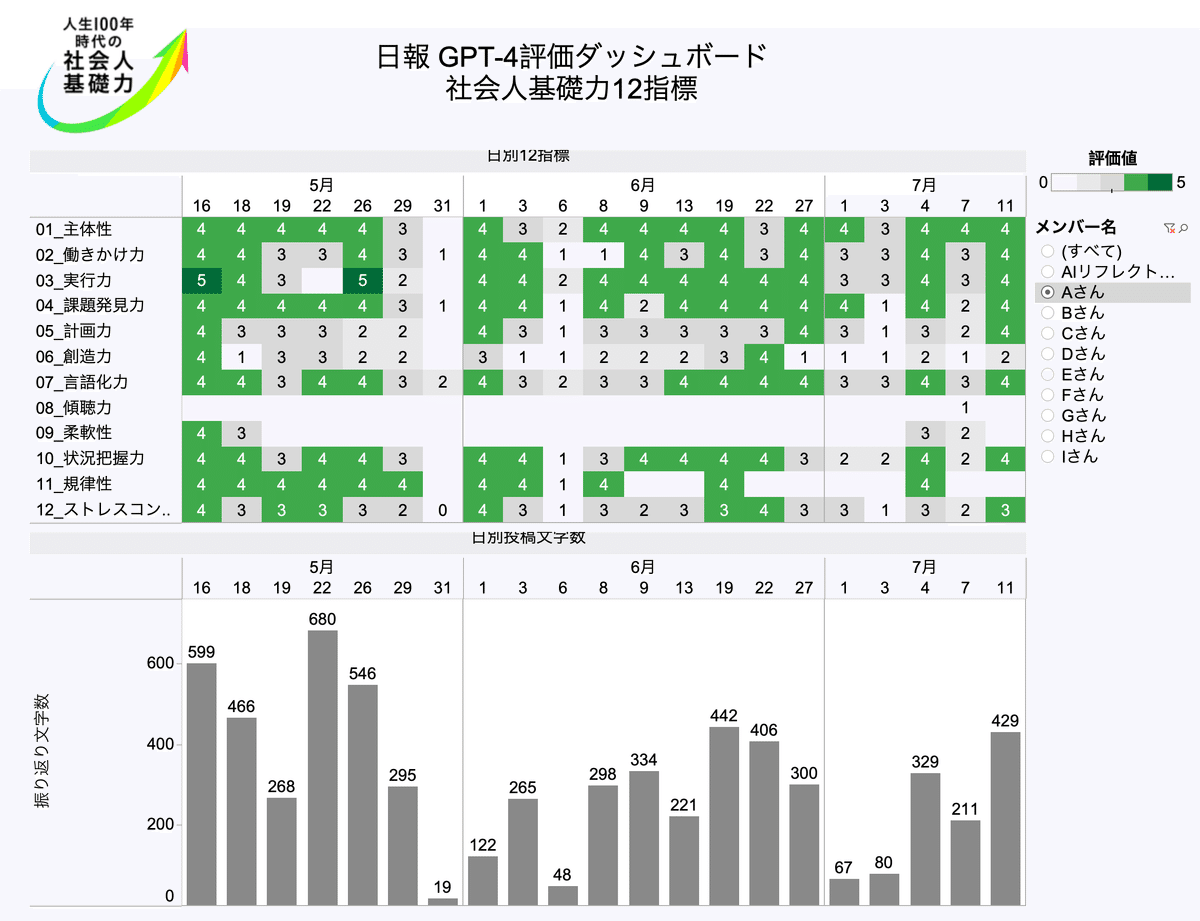
Fさんは、新人のシステムエンジニアです。かなり真面目に振り返りを続けており、文字量も多いです。着実に業務を進めており、主体性、実行力、課題発見力が高く評価されています。また、自分なりにストレスをコントロールする力も評価されています。一方業務特性もありますが、働きかけ力が低いため、これから開発をするにあたりこの力を上げることが課題であることがわかりました。

5.AI評価のメリット、デメリット
このようにAI評価(GPT-4)の事例を挙げて見ましたが、AI評価のメリット、デメリットをまとめます。
メリット
評価者の知識・経験のばらつきに左右されない
評価者の疲労などコンディションに左右されない
リアルタイムで評価を出せるため、鮮度高く行動につなげられる
評価のプロセスが標準化されているため、評価自体の改善もしていきやすい
デメリット
AI評価に抵抗感がある人には説明が必要
インプットするデータ、学習されたデータからしか評価できない
6.最後に
研究開発中の要素もありますが、大きな傾向を見る上では、AI評価の可能性が見えてきました。今後も検証のサンプルサイズを増やすなど研究開発を進めていきます。
日報に対して、ChatGPTのAIコーチがサポートするリフレクトは2023年8月に、日々の振り返りを経済産業省の社会人基礎力の12指標で評価する機能をリリースする予定です。
先行して、試されたい方は下記のホームページよりお問合せください。優先的にご案内差し上げます。
webサイトより資料請求や2週間無料のトライアル利用のお申込みが可能です。
また、社内にある従業員の日報や振り返りテキストデータから、社会人基礎力を指標化することも可能です。ご興味のある方は合わせてご相談ください。
または、下記のQRコードをスキャンしていただくとホームページを開くことができます。

この記事が気に入ったらサポートをしてみませんか?