LLMエージェント機能を簡単に構築できるLangGraphを試してみた。RAGチャットボット

こんにちは!株式会社IZAI、エンジニアチームです。
今回は、LLM搭載サービスを開発するときに重要な、条件分岐やループ構造を簡単に構築できると話題の「LangGraph」を試してみます。
LangGraphとは
LangGraphとはLangChainの派生ライブラリで、LangChainの動作に加え、ステートマシンのような計算グラフを作成し条件分岐やループ処理などを行うことができます
LangGraphを使ってみる
LangGraphのグラフは通常の計算グラフ同様NodeとEdgeで構成されています。まずは簡単なチャットボットを作成してみましょう。
1. パッケージのインストール
必要なライブラリをインストールしていきます。今回はOpenAIのGPT-3.5-turboを使うのでlangchain_openaiもインストールします。
pip install httpx
pip install langgraph
pip install langchain_openaifrom typing_extensions import TypedDict, Optional
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph
from langchain_core.pydantic_v1 import BaseModel, Field2. Stateの定義
Stateクラスは辞書型のオブジェクトで、各ノードはStateオブジェクトを引数として受け取ります。各ノードはそれをもとに処理を行い、Stateを更新していきます。
これから作るのは簡単なチャットボットなのでkeyはmessageのみとしておきましょう。
class State(TypedDict):
message: Optional[str] = None
graph_builder = StateGraph(State)3. グラフの構築
次にノードを定義します。
def chat(State):
if State["message"]:
return {"message": llm.invoke(State["message"])}
return {"message": "No user input provided"}グラフを構築するにはノードのほかにスタートとゴール、そしてそれらをつなぐエッジを指定する必要があります。今回はノードが一つしかないのでエッジを追加する必要はありません。
graph_builder.add_node("chatbot", chatbot) # ノードの名前とノードに使用する関数を追加
graph_builder.set_entry_point("chatbot") # スタート位置の指定
graph_builder.set_finish_point("chatbot") # ゴール位置の指定
graph = graph_builder.compile() # グラフを構築作成したグラフを図示してみましょう。
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))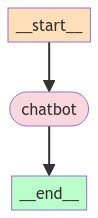
4. グラフの実行
では、実際にこのチャットボットを動かしてみましょう。
response = graph.invoke({"message": "LangGraphとは何ですか?"})
print(response["message"].content)LangGraphは、言語の特性や関係をグラフ構造で表現するためのツールやフレームワークのことを指します。言語の構造や接続関係を視覚的に理解するために使用され、自然言語処理や機械翻訳などの言語関連の研究や開発に役立ちます。LangGraphは、単語や文法規則などの要素をノードとして表現し、それらの要素間の関係をエッジで表現します。これにより、言語の構造や意味をより理解しやすくすることができます。
無事レスポンスが返ってきました。
複雑なグラフの構築
それでは、さらに複雑なグラフも構築してみましょう。
今回はユーザーのメッセージの属性が「会話」か「検索」かを判定し、「検索」だった場合はRAGを用いてドキュメントから回答を作成するチャットボットを実装してみます。
社内ナレッジ搭載ChatGPTなどで想定される挙動ですね。
それでは試していきましょう!
1. パッケージのインストール
pip install langchain_community
pip install pypdf
pip install faiss-cpu2. RAGドキュメントの作成
FAISSを用いてRAGデータベースを作成します。使用するドキュメントは Kolmogorov–Arnold Networks についての論文です。
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
length_function=len,
)
file_path = (
"./KAN.pdf"
)
loader = PyPDFLoader(file_path)
data = loader.load()
split_docs = text_splitter.split_documents(data)
db = FAISS.from_documents(split_docs, embedding=OpenAIEmbeddings())3. Stateの定義
Stateなどを定義していきます。MessageTypeはメッセージ判定の出力のフォーマットに使用します。
class State(TypedDict):
message_type: Optional[str] = None
message: Optional[str] = None
class MessageType(BaseModel):
message_type: str = Field(description="The type of the message", example="search")次にLLMモデルの設定です。
llm = ChatOpenAI(model="gpt-3.5-turbo")
classifier = llm.with_structured_output(MessageType)4. グラフ構築
さらにそれぞれのノードも設定します。
def classify(State):
# プロンプトの作成
classification_prompt = """
## You are a message classifier.
## If the user are searching for information regarding the KAN model, respond with 'search'.
## Otherwise, respond with 'chat'.
## user message: {user_message}
"""
if State["message"]:
return {
"message_type": classifier.invoke(classification_prompt.format(user_message=State["message"])).message_type,
"message": State["message"]
}
else:
return {"message": "No user input provided"}
def chat(State):
if State["message"]:
return {"message": llm.invoke(State["message"])}
return {"message": "No user input provided"}
def search(State):
# RAG用のプロンプト
rag_prompt = """
## Respond to the user query according to the relevant documents.
- User query: {query}
- Relevant documents: {docs}
"""
#テキスト部分を抽出
docs = [doc.page_content for doc in db.similarity_search(State["message"])]
return {"message": llm.invoke(rag_prompt.format(query=State["message"], docs=docs))}
def response(State):
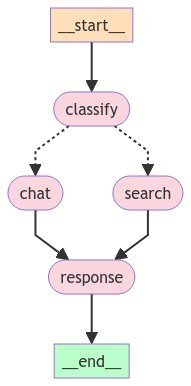
return Stateエッジを追加しグラフを構築していきます。ここで、add_conditional_edgesを使うことにより、条件分岐を追加することができます。
graph_builder = StateGraph(State)
# ノードの追加
graph_builder.add_node("classify", classify)
graph_builder.add_node("chat", chat)
graph_builder.add_node("search", search)
graph_builder.add_node("response", response)
# エッジの追加
graph_builder.add_edge("chat", "response")
graph_builder.add_edge("search", "response")
# 条件分岐
graph_builder.add_conditional_edges("classify", lambda state: state["message_type"], {"chat": "chat", "search": "search"})
# 開始位置、終了位置の指定
graph_builder.set_entry_point("classify")
graph_builder.set_finish_point("response")
# グラフ構築
graph = graph_builder.compile()構築したグラフを図示してみましょう。
5. グラフの実行
では、実際に試してみましょう。最初に比較対象としてRAGなどを使用していないGPT3.5-turboの回答を確認します。
response = llm.invoke("how well did KAN perform compared to MLP?")
print(response.content)It is difficult to compare the performance of KAN and MLP without specific context or data. Performance can be measured in various ways such as financial performance, market share, customer satisfaction, etc. Without specific information on these metrics for both KAN and MLP, it is not possible to determine how well one performed compared to the other.
あまり要領を得ない回答が返ってきました。
RAGを使用した回答はどうでしょうか。
response = graph.invoke({"message": "how well did KAN perform compared to MLP?"})
print(response["message"].content)Based on the provided information, it seems that KANs (Kolmogorov-Arnold Networks) perform better compared to MLPs (Multi-Layer Perceptrons) in various tasks such as regression and PDE solving. KANs display more favorable Pareto Frontiers than MLPs and can work in continual learning without catastrophic forgetting. In the comparison between KANs and MLPs on five toy examples, KANs almost saturate the fastest scaling law predicted by the theory while MLPs scale slowly and plateau quickly. Additionally, KANs are shown to be more efficient and accurate in representing special functions than MLPs. Therefore, overall, KANs seem to perform better than MLPs in the tasks and comparisons mentioned in the provided documents.
きちんと論文の内容が取得できているようです。
最後にKANとは全く関係ない質問をしてみます。
response = graph.invoke({"message": "What is the best code editor?"})
print(response["message"].content)There is no definitive answer to this question as it ultimately depends on personal preference and the specific needs of the user. Some popular code editors among developers include Visual Studio Code, Sublime Text, Atom, and JetBrains IntelliJ IDEA. Each of these editors has its own set of features and capabilities, so it is recommended to try out a few different options to see which one works best for you.
質問の種類によって回答の生成のされかたが違うことがわかりますね。
今回の例ではRAGを用いて簡単なチャットボットを作成しましたが、RAGで情報が見つからなかった場合にWeb検索で情報を取得したり、Function Callingを用いてRAGで取得したデータをもとに関数を呼んでみたりと便利でしょう。
最後に
LangGraphを使うと、複雑な条件分岐やループ処理を持つ一連の流れを簡単に開発できることが分かります。
AIエージェントを実装する際にも、LangGraphを使用することでフローチャートから簡単に実装することや、Function Callingなどを利用して他アプリと連携することが簡単にでき、作業の自動化に使えそうです。
以上、参考になった方はいいねやコメント頂けると嬉しいです!
株式会社IZAIでは、自然言語処理・音声合成・ロボティクス技術の研究開発・サービス提供をしております。興味をお持ちいただいた方はお気軽にお問い合わせください。それではまた!
参考
[1] LangGraph overview
[2] How to return structured data from a model
[3] Introduction to LangGraph: A Beginner’s Guide
この記事が気に入ったらサポートをしてみませんか?