
【実装編】Diffusion Model(拡散モデル)とは?

前の記事に引き続き、生成AIをPythonで実装していきます。
・AutoEncoderはこちら:https://note.com/itsuka_someday/n/nc2fd241f5fd8
・GANはこちら:https://note.com/itsuka_someday/n/nb2b8bd298cb3
今回はStable Diffusionの登場により一気に生成AIの主流になった、Diffusion Model(拡散モデル)を実装していきます。
チュートリアルがないため、ChatGPTに聞きながら実装していきます。
必要なライブラリをインポート
# ライブラリのインストール
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm # 進捗バー表示用データセットのダウンロード
# データセットのロード
(x_train, _), (_, _) = mnist.load_data()
x_train = x_train.astype(np.float32) / 255.0 # 0-1に正規化
x_train = np.expand_dims(x_train, axis=-1) # チャンネル次元を追加いつものごとくMNIST(手書き文字画像)です。
モデルの定義
# モデルの定義
def build_model(input_shape):
inputs = layers.Input(shape=input_shape)
x = layers.Conv2D(64, (3, 3), padding='same', activation='relu')(inputs)
x = layers.Conv2D(128, (3, 3), padding='same', activation='relu')(x)
x = layers.Conv2D(128, (3, 3), padding='same', activation='relu')(x)
x = layers.Conv2D(1, (3, 3), padding='same')(x) # 1チャネルに出力
model = tf.keras.Model(inputs, x)
return modelシンプルなコードになるように、最低限の構成にしています。
モデルを定義したら可視化して確認してみましょう。
# モデルを構築
model = build_model(input_shape=(28, 28, 1))
# モデルの概要を表示
model.summary()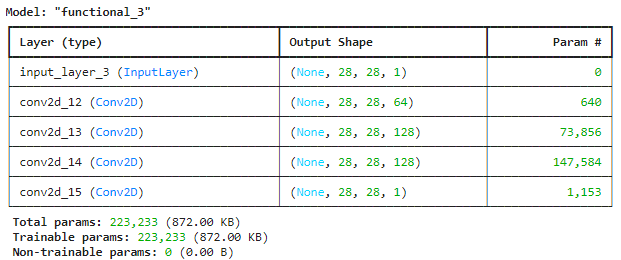
MNISTを使用しているため、入力サイズは28×28としています。
以下のように計算が進む過程で、モデルは元画像に追加されたノイズを予測し、最終的にはノイズのみを表わした28×28の画像を一枚出力します。
入力画像 28×28×1
↓
1層目 28×28×62
↓
2層目 28×28×128
↓
3層目 28×28×128
↓
最終層 28×28×1
最終層から生成されたノイズを、入力画像から引き算することで、ノイズを除去し元々の画像が復元できるというのがDiffusion Modelの主なコンセプトとなります。
学習
### 学習
# 変数の宣言
x0 = x_train
num_steps = 1
epochs = 100
batch_size = 64
# 最適化関数と損失関数の宣言
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)
mse_loss = tf.keras.losses.MeanSquaredError()
# 学習ループ
for epoch in range(epochs):
print(f"Epoch {epoch + 1}/{epochs}")
pbar = tqdm(total=len(x0), desc="Training") # tqdmを使用して進捗バーを作成
for i in range(0, len(x0), batch_size):
x_batch = x0[i:i+batch_size]
# 学習画像にノイズを付与(フォワード・ディフュージョン)
xt, noise = forward_diffusion(x_batch, num_steps)
# ノイズを予測し、損失関数を計算
with tf.GradientTape() as tape:
pred_noise = model(xt, training=True)
loss = mse_loss(noise, pred_noise)
# 勾配の計算とパラメータの更新
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
pbar.update(batch_size) # バッチごとに進捗バーを更新
pbar.set_postfix({"Loss": loss.numpy()}) # 現在の損失を表示
# 途中経過を表示
validation(xt, model, num_steps=10, shape=(1, 28, 28, 1))
# 進捗バーを閉じる
pbar.close()
print(f"Epoch {epoch + 1} completed with Loss: {loss.numpy()}\n")学習の経過を確認できるようにするために、少しコードが長くなってしまいました。
諸々の関数と共に、全体の流れを説明していきます。
1. 学習画像にノイズを付与
# 入力画像にノイズを追加
def forward_diffusion(x0, num_steps, beta_start=1e-4, beta_end=0.02):
betas = np.linspace(beta_start, beta_end, num_steps)
alphas = 1.0 - betas
alphas_cumprod = np.cumprod(alphas, axis=0)
noise = np.random.randn(*x0.shape)
xt = np.sqrt(alphas_cumprod[num_steps-1]) * x0 + np.sqrt(1.0 - alphas_cumprod[num_steps-1]) * noise
return xt, noiseノイズと、ノイズを付与した画像を返しています。
2. ノイズを予測し、損失関数を計算
ノイズ付き画像をモデルに入力し、付与されたノイズを予測します。
その後、実ノイズと予測ノイズを比較し、損失を計算します。
3. 勾配の計算と、パラメータの更新
算出された損失から勾配を計算し、モデルを学習(最適化)します。
4. 途中経過の表示
# 途中経過を表示
def validation(x, model, num_steps, shape):
# ノイズ付き画像を表示
y = sample(x, model, num_steps=num_steps, shape=shape)
# 画像を横に並べて表示
fig, axes = plt.subplots(1, 2, figsize=(3, 1.5))
axes[0].imshow(x[0, :, :, 0], cmap='gray')
axes[0].set_title('Noisy Image')
axes[0].axis('off')
axes[1].imshow(y[0, :, :, 0], cmap='gray')
axes[1].set_title('Restored Image')
axes[1].axis('off')
plt.show()ノイズ付き画像と、学習中のモデルから生成された復元画像を並べて表示させています。
※画像の生成は以下の関数で実施
# 画像生成
def sample(x, model, num_steps, shape):
betas = np.linspace(1e-4, 0.02, num_steps)
alphas = 1.0 - betas
alphas_cumprod = np.cumprod(alphas, axis=0)
for t in reversed(range(num_steps)):
x = x - model(x) / np.sqrt(1.0 - alphas_cumprod[t])
if t > 0:
x = x + np.sqrt(betas[t]) * np.random.randn(*shape)
return x段階的にノイズ画像からノイズを除去しています。
モデル自体はノイズを予測するものなので、予測されたノイズをノイズ画像から除去することで、元画像を生成しています。
実行例
Google Colabで実行すると、以下のように途中経過を表示しながら学習していきます。

まとめ
以上、今回は話題のDiffusion Modelの実装を行いました。
モデル構成をより複雑にする、学習回数を増やす、Pytorchを用いる、、など条件を変えて色々試してみてはいかがでしょうか?
その他の主流な生成AIは、過去の記事を参考にしてみてください。
・AutoEncoderはこちら:https://note.com/itsuka_someday/n/nc2fd241f5fd8
・GANはこちら:https://note.com/itsuka_someday/n/nb2b8bd298cb3
ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?