
ロシア製画像生成AIモデルKandinsky 2.2の概要とColabノートの紹介

今年4月に、ロシア製画像生成AIモデルのKandinsky 2.1が公開されました。このモデルは、多言語対応なので、日本語指示でそのまま画像生成することもできます。
また、今年の7月には、新モデルの Kandinsky 2.2が公開されました。この新モデルの概要についても説明し、同モデルをGoogle Colabで利用するためのノートを紹介します。(2023.7.14追記)
※表紙の画像は、実際にGoogle ColabでKandinsky 2.2モデルを使用して生成したものです。
1.Kandinsky 2.1用のGoogle Colabノート
最初に、モデル設定用のコードを準備します。
モデル設定用のコードは以下のとおりです。このコードをColabノートにコピーし、ランタイムのタイプをGPUに設定して、セルを実行してください。
3分ほどで終了します。
!pip install 'git+https://github.com/ai-forever/Kandinsky-2.git'
!pip install git+https://github.com/openai/CLIP.git
from kandinsky2 import get_kandinsky2
model = get_kandinsky2('cuda', task_type='text2img', cache_dir='/tmp/kandinsky2', model_version='2.1', use_flash_attention=False)次に、画像生成を実行します。
画像生成実行用のコードは以下のとおりです。「ここに指示を記入」のところに描きたい画像の指示を記入し、このコードをColabノートにコピーし、セルを実行してください。指示は、日本語でも問題ありません。
1分ほどでコードの下に画像が1枚表示されます。気に入った画像であれば、自分で右クリックして保存してください。
指示を書き換えて実行すれば、何度でも画像生成することができます。
images = model.generate_text2img('''ここに指示を記入''', num_steps=100,
batch_size=1, guidance_scale=4,
h=768, w=768
,sampler='p_sampler', prior_cf_scale=4,
prior_steps="5",)
images[0]【画像生成の例】

Google Colabなどの使い方がよく分からない方は、以下の記事を参考にしてください。
2.Kandinsky 2.1モデルの概要
Kandinsky 2.1モデルのアーキテクチャーは以下のとおりです。
Kandinsky 2.1は、Dall-E 2と潜在拡散モデルからベストプラクティスを継承しつつ、いくつかの新しいアイデアを導入しています。
また、多言語対応で、英語、ロシア語のほか、日本語指示でもそのまま画像生成できます。
Kandinsky 2.1は、テキストと画像のエンコーダーとして、CLIPモダリティの潜在空間でCLIPモデルと拡散画像プライアー(マッピング)を使用しています。このアプローチは、モデルの視覚的性能を向上させ、画像のブレンドやテキスト誘導による画像操作に新たな地平を切り開きます。
潜在空間の拡散マッピングには、num_layers=20、num_heads=32、hidden_size=2048のトランスフォーマーを使用しています。
また、その他のアーキテクチャ部分は以下のとおりです。
テキストエンコーダー (XLM-Roberta-Large-Vit-L-14) - 560M
拡散画像プライアー - 1B
CLIP画像エンコーダー(ViT-L/14) - 427M
潜在拡散U-Net - 1.22B
MoVQエンコーダー/デコーダー - 67M
Kandinsky 2.1は、大規模な画像-テキストデータセットのLAION HighResで学習し、我々の内部データセットでファインチューニングしました。

Kandinsky 2.1は、以下のように画像生成AIの性能評価指標のFIDで、DALL-E 2やStable Diffusion 2.1を超えるスコアを出しています。

3.Kandinsky 2.2
(1) 新モデルの概要
今月、ロシア最大の銀行ズベルバンク(Sberbank)のAI研究チームが画像生成AIのKandinsky 2.2モデルを発表しました。
【参考】SberbankのKandinsky 2.2公式ページ(ロシア語)
Kandinsky 2.2のパラメータは46億、学習に利用したデータセットは画像とテキストの15億ペア、解像度は1024×1024で、任意のアスペクト比に対応しており、3ヶ月前に発表されたKandinsky 2.1モデルよりも画像の品質とフォトリアリズムが改善しています。また、画像生成プロセスを効果的に制御できるControlNetもサポートしました。
アーキテクチャーの主な変更点は、画像エンコーダーをより強力なCLIP-ViT-Gに置き換え、生成画像の品質を向上させたことです。画像エンコーダーの入れ替えのために、様々な解像度、アスペクト比の画像モデルを再学習し、U-Netの拡散部分をファインチューニングしています。
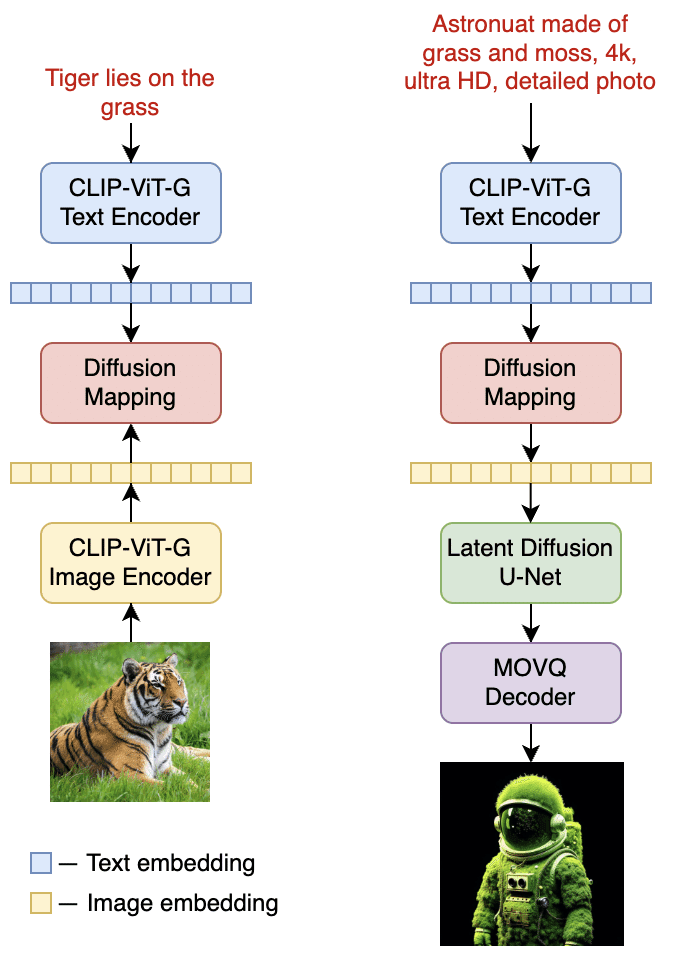

(2) Kandinsky 2.2用のGoogle Colabノート
camenduruさんが以下のページでKandinsky 2.2用のGoogle Colabノートを紹介しています。同じページには、Kandinsky 2.0、2.1用のColabノートへのリンクもあり、比較することができます。
Colabノートへのリンクをクリックし、ランタイムのタイプをGPUに設定して、セルを実行してください。
2つ目のセルのpromptを書き換えることによって自分の好みの画像を生成することができます。
Kandinsky2.2用Colabノート
Kandinsky2.1用Colabノート
Kandinsky2.0用Colabノート



この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?