
SDXL 1.0をGoogle Colabで利用する方法

7月27日、Stability AIが最新画像生成AIモデルのSDXL 1.0を発表しました。
そこで、このモデルをGoogle Colabで利用する方法について紹介します。
※2023/09/27追記 他のモデルの使用法をFooocusベースに変更しました。BreakDomainXL v05g、blue pencil-XL-v0.5.2、Emiを追加しました。
1.SDXL 1.0の概要
(1) SDXL 1.0の特徴
SDXL 1.0は、標準で1024×1024ピクセルの画像を生成可能です。
既存のモデルより、光源と影の処理などが改善しており、手や画像中の文字の表現、3次元的な奥行きのある構図などの画像生成AIが苦手とする画像も上手く生成できます。
また、プロンプトの理解力も向上し、短いプロンプトでも高品質な画像を生成できると言います。
(2) SDXL 1.0の仕組み
SDXL 1.0は、35億のパラメーターを持つベースモデルと66億のパラメーターを持つリファイナーモデルの2種類のモデルで構成されています。
フルモデルは、潜在拡散のための混合エキスパート・パイプラインで構成されており、最初のステップで、ベースモデルがノイズの多い潜在データを生成し、それを最終的なノイズ除去ステップに特化したリファイナーモデルで処理する仕組みです。
SDXL 1.0は、この2段階のアーキテクチャーを採用したことにより、過剰な計算リソースを必要とせず、速度を失わずにロバストな画像生成が可能となっています。
このため、SDXL 1.0は、8GBのVRAMを搭載したコンシューマー向けGPUでも問題なく動作します。

ベースモデルは単独で使用することもできます。
SDXL 1.0は、CreativeML OpenRAIL++-Mライセンスを採用しており、基本的に商用可能です。
2.Diffusersによる方法
Diffusersを使用し、Google ColabでSDXL 1.0を利用します。
Hugging Face上のSDXL 1.0のモデルカードや、npakaさんとしろさんのnote記事を参考にしました。
(1) ベースモデル単独
最初に、ベースモデル単独で利用します。
以下のコードをGoogle Colabのノートブックのセルにコピーし、GPUを設定して、セルを実行してください。
!pip install diffusers --upgrade
!pip install invisible_watermark transformers accelerate safetensors
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16"
)
pipe.to("cuda")画像生成する際には、以下のコードの所定の場所にプロンプトを入力し、セルにコピーして実行してください。
prompt = "自分の生成したい画像のプロンプトを入力"
image = pipe(prompt=prompt).images[0]
image.save("output.png")
image実行結果▼


(2) ベースモデル+リファイナーモデル
次は、ベースモデルとリファイナーモデルを組み合わせたフルモデルを利用します。
以下のコードをGoogle Colabのノートブックのセルにコピーし、GPUを設定して、セルを実行してください。
!pip install diffusers --upgrade
!pip install invisible_watermark transformers accelerate safetensors
from diffusers import DiffusionPipeline
import torch
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
base.to("cuda")
refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
)
refiner.enable_model_cpu_offload()画像生成する際には、以下のコードの所定の場所にプロンプトを入力し、セルにコピーして実行してください。
prompt = "自分の生成したい画像のプロンプトを入力"
n_steps = 50
high_noise_frac = 0.8
image = base(
prompt=prompt,
num_inference_steps=n_steps,
denoising_end=high_noise_frac,
output_type="latent",
).images
image = refiner(
prompt=prompt,
num_inference_steps=n_steps,
denoising_start=high_noise_frac,
image=image,
).images[0]
image.save('output_refiner.png')
image実行結果▼


3.ComfyUIを使う方法
(1) Google ColabでComfyUIを使用する方法
ComfyUIは、入出力やその他の処理を表すノード(黒いボックス)を線で繋いで画像生成処理を実行していくノードベースのウェブUIです。
今回は、camenduruさんが作成したsdxl_v1.0_comfyui_colabのノートブックを使用します。
上のバナーをクリックすると、sdxl_v1.0_comfyui_colabのノートブックが開きます。そこで、GPUを設定して、セルを実行してください。
3分ほどでhttps://measured-fd-downtown-colour.trycloudflare.comのようなCloudflareのリンクが現れ、モデルとVAEのダウンロードが終了したら、このリンクをクリックしてください。
ComfyUIの操作画面が開きます。

次に、以下のファイルをダウンロードして自分のパソコンに保存し、そのファイルをComfyUIの操作画面にドラッグしてください。
すると、以下のワークフローが表示されます。
上がリファイナーモデルをプラスしたフルモデルの画像、下がベーシックモデル単独の画像になります。

(2) ComfyUIの操作方法
ノード(ボックス)は自由に動かせるので、自分が使いやすい位置に動かしてください。

Positive PromptとNegative Promptのノードにプロンプトを入力します。Image Sizeのノードで横(width)と縦(height)の大きさを設定(1024が標準)し、batch_sizeで生成する画像の枚数を設定します。

2つあるKSamplerのノードでは、ベースモデルとリファイナーモデルのそれぞれについて、ステップ数やSamplerの種類の変更ができます。
最後に、一番右端のボックスのQueue Promptをクリックすると、画像生成が開始し、上のRESULT WITH REFINERにフルモデルの画像、下のRESULT WITHOUT REFINERにベーシックモデル単独で生成した画像が表示されます。
(3) ControlNetが使えるComfyUI
GoogleColab版のComfyUIでも構図指定やポーズ指定のできるControlNetが使えるようになりました。
上のバナーをクリックすると、sdxl_v1.0_controlnet_comfyui_colabのノートブックが開きます。そこで、GPUを設定して、セルを実行してください。
モデルなどのダウンロード終了後に、https://xxxxxxxx.trycloudflare.comのようなCloudflareのリンクをクリックすると、ComfyUIの操作画面が開きます。
次に、以下のファイルをダウンロードして自分のパソコンに保存し、そのファイルをComfyUIの操作画面にドラッグしてください。
すると、以下のワークフローが表示されます。

【ControlNetの使い方】
例えば、輪郭線を抽出するCannyを使用する場合は、左端のLoad Imageのノードでchoose file to uploadをクリックして、輪郭線を抽出する元画像をアップロードします。
次に、2つの(Prompt)ノードの上に通常のプロンプト、下にネガティブプロンプトを入力します。
そして、Load ControlNet ModelのノードでCannyのモデルを選択し、右端のボックスのQueue Promptをクリックすると画像生成が開始し、真ん中に輪郭線を抽出した白黒画像、右端に輪郭線を同じにして新たに生成した画像が表示されます。
(4) 生成した画像例



4.Stable Diffusion WebUIを使う方法
(1) 利用方法
今回使用するのは、camenduruさんが作成したsdxl_v1.0_webui_colabのノートブックです。
上のバナーをクリックすると、sdxl_v1.0_webui_colabのノートブックが開きます。そこで、GPUを設定して、セルを実行してください。
その後、Public WebUI Colab URL:の後に続くリンクが4種類現れますので、この内の一つを選んでクリックしてください。
見慣れたStable Diffusion WebUIの操作画面が開きます。

(2) 生成した画像例



5.StableSwarmUIを使う方法
次は、Stability AIが発表した新しいウェブUIのStableSwarmUI(α版)を使用してみます。
(1) 利用方法
以下のバナーをクリックすると、StableSwarmUI のノートブックが開きます。
そこで、GPUを設定して、2つのセルを上から順番に実行してください。2つ目のセルを実行すると、途中で、https://inline-chronicles-inter-syndication.trycloudflare.comのようなCloudflareのリンクが現れますので、これをクリックしてください。
すると、最初にStableSwarmUI Installerと書かれたページが現れますので、画面の指示に従って、ウェブUIのテーマ、バックエンド(None)、モデル(XL 1.0)などを選択し、最後に、Yes, I'm sure (Install Now)をクリックしてください。
※このノートブックでは、ComfyUIがインストール済みなので、バックエンドはNoneを選択します。
しばらく待つと、インストールが終了し、StableSwarmUI の操作画面が開きます。
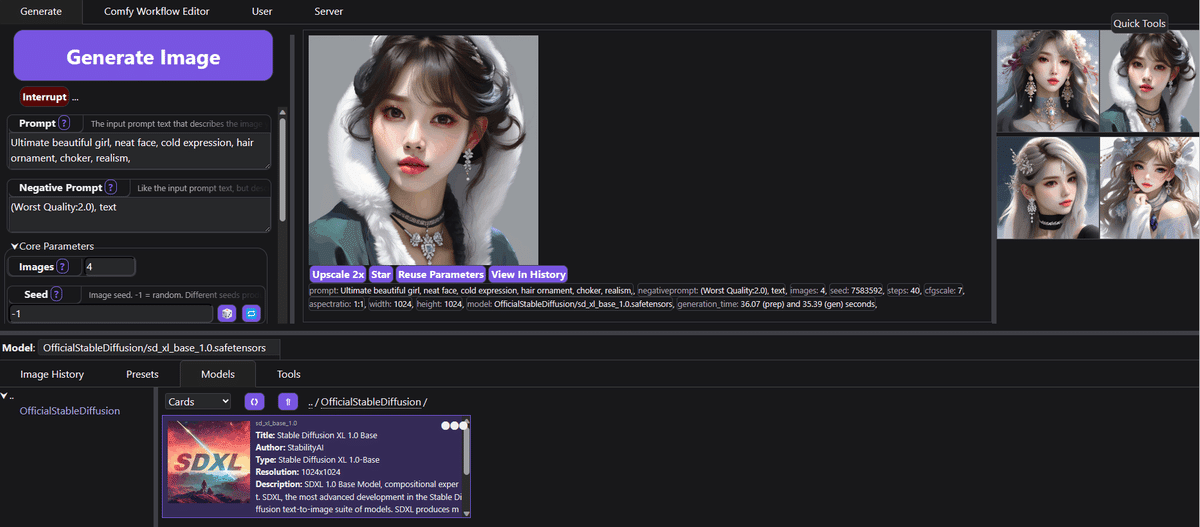
ここでPromptとNegative Promptを入力し、ステップ数、生成枚数などを設定し、Model:欄でsd_xl_base_1.0.safetensorsを選んで、Generate Imageをクリックすると、画像が生成されます。
なお、Comfyワークフローのエディター画面に切り替えることもできます。
(2) 生成した画像例


6.Fooocusを使う方法
次は、ControlNetを開発したlllyasviel氏が発表した、プロンプトを入力して1クリックするだけで、簡単にSDXLベースの画像生成ができるFooocusを紹介します。
(1) 利用方法
今回は、camenduruさんの作成したFooocus用のColabノートを使用します。以下のバナーをクリックすると、ノートが開きます。
そこで、GPUを設定して、セルを実行してください。しばらくすると、最後にhttps://xxxxxxxx.gradio.liveのようなGradioのリンクが現れますので、これをクリックすると、Fooocusの操作画面が開きます。
※途中で「RESTART RUNTIME」というボタンが表示されることがありますが、クリックせずに無視してください。

ここで入力欄にプロンプトを入力し、Generateボタンをクリックするだけで2枚の画像が生成されます。画像生成に必要な操作はこれだけです。
画像を保存するには、画像の上でマウスを右クリックして、「名前を付けて画像を保存」を選択してください。
次に、左下のAdvancedにチェックすると、以下のAdvancedモードの操作画面に移ります。

Advancedモードでは、ステップ数30のSpeedとステップ数60のQualityの2種類の生成方法を選択できるほか、サイズ、枚数、シード値、ネガティブプロンプトを設定できます。
また、Styleタブをクリックすると、以下の中から画像スタイルを選択することができます。

〇 Fooocus全105スタイルの画像一覧
次に、以下のAdvancedタブを開いて、追加でダウンロードした他のモデルに切り替えたり、LoRA(既存モデルを少数の画像で追加学習することによりファインチューニングできる仕組み)を設定したりすることができます。
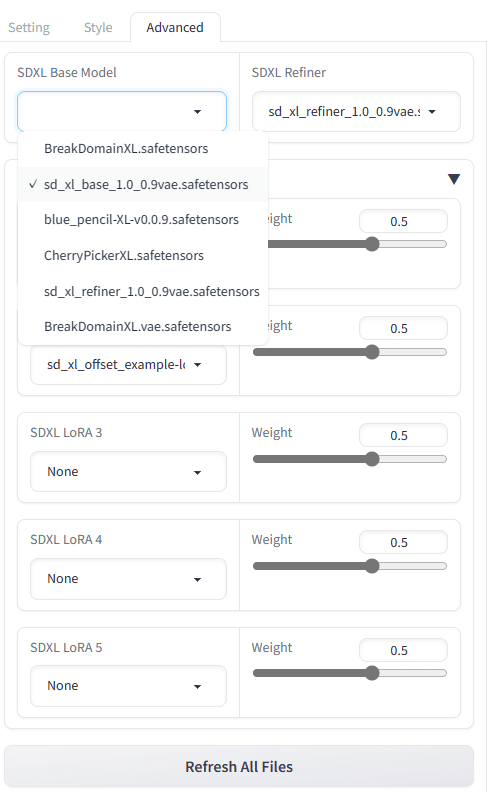
〇 SDXL 1.0以外のモデルの追加方法
以下の例では、上から3~5行目を追加して、Fuduki Mix v1.5とEmiのモデルを追加しています。
%cd /content
!git clone https://github.com/lllyasviel/Fooocus
!apt -y install -qq aria2
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/Kotajiro/fuduki_mix/resolve/main/fuduki_mix_v15_fp16.safetensors -d /content/Fooocus/models/checkpoints -o fuduki_mix_v15_fp16.safetensors
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/alfredplpl/emi/resolve/main/emi.safetensors -d /content/Fooocus/models/checkpoints -o emi.safetensors
%cd /content/Fooocus
!pip install pygit2==1.12.2
!python entry_with_update.py --share
このように、例えばFuduki Mix v1.5を追加する場合は、以下のようなコードを追加します。(Fooocus-MREの場合は、太字部分がFooocus-MREに変わります。)
!apt -y install -qq aria2 !
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/Kotajiro/fuduki_mix/resolve/main/fuduki_mix_v15_fp16.safetensors -d /content/Fooocus/models/checkpoints -o fuduki_mix_v15_fp16.safetensors
https://huggingface.co/Kotajiro/fuduki_mix/resolve/main/fuduki_mix_v15_fp16.safetensorsは、このモデルのダウンロードリンクです。ダウンロードリンクは、下記(4)に記載したほか、モデルが掲載されているCivitaiのサイトでも調べることができます。

(2) 生成した画像例
① None

② cinematic-default

③ artstyle-impressionist

④ sai-anime

(3) Fooocus MoonRide Edition
Fooocusにimg2imgモード、各種パラメータのカスタマイズ、メタデータの表示・保存・読込などの機能を追加したムーンライド・エディション(Fooocus-MRE)が公開されました。
ムーンライド・エディションの新機能
1.img2imgモードをサポート
2.カスタマイズ可能なサンプラー
3.カスタマイズ可能なスケジューラー
4.カスタマイズ可能なステップ、ベース/リファイナー切り替えポイント
5.カスタマイズ可能なCFG
6.CLIPスキップのカスタマイズ
7.生成された画像のフルメタデータをUIに表示。
8.生成された画像のフルメタデータをJSON又はPNGに埋め込む機能
9.JSONファイルやPNGファイルからプロンプト情報を読み込む機能
10.UI設定のデフォルト値を変更する機能
11.デフォルトパスの変更機能
12.SDXL解像度の公式リスト
13.コンパクトな解像度とスタイルの選択
ムーンライド・エディションを利用するには、以下のバナーをクリックし、GPUを設定して、セルを実行してください。利用方法は、上記(1)のFooocusの利用方法と基本的に一緒です。

Metadataタブを開くと、以下のように生成された画像のメタデータを見ることができます。

〇 img2imgモード
Load Image(s)をクリックして、元画像をアップロードします。
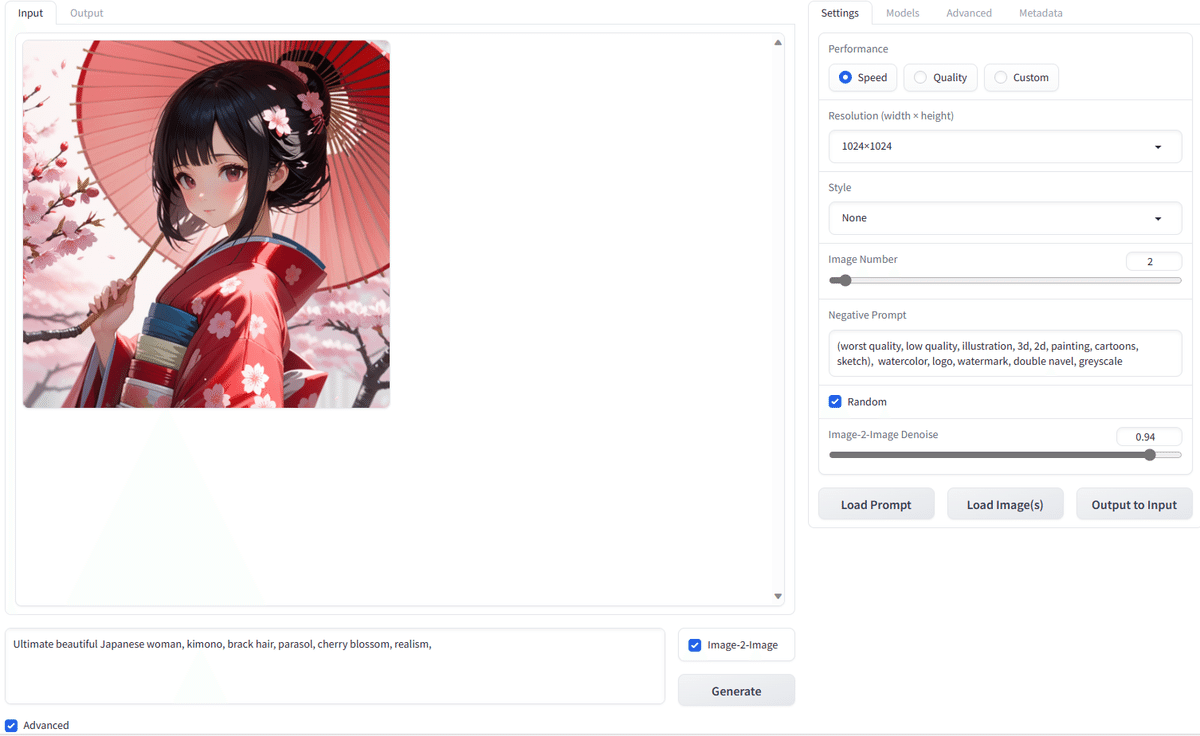
次に、Image-2-Imageにチェックマークを入れて、プロンプトを入力し、Generateをクリックすると、元画像を参照した新しい画像が生成されます。

(4) Fooocusをベースにした他のモデルなどの使用
以下のコードを書き換えて、他のモデルを使用することができます。
%cd /content
!git clone https://github.com/lllyasviel/Fooocus
!apt -y install -qq aria2
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/Kotajiro/fuduki_mix/resolve/main/fuduki_mix_v15_fp16.safetensors -d /content/Fooocus/models/checkpoints -o fuduki_mix_v15_fp16.safetensors
%cd /content/Fooocus
!pip install pygit2==1.12.2
!python entry_with_update.py --share他のモデルを使用するには、4行目の!aria2cで始まるコードを、それぞれのモデルに対応したコードに書き換えてセルを実行してください。複数のモデルを同時にインストールすることも可能です。
上の例では、Fuduki Mix v1.5のモデルが入っています。
【参考】FooocusのColabノート (Official Version)
【参考】Fooocus-MREのColabノート
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/gsdf/CounterfeitXL/resolve/main/CounterfeitXL-V1.0.safetensors -d /content/Fooocus/models/checkpoints -o CounterfeitXL-V1.0.safetensors
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/jayparmr/DreamShaper_XL1_0_Alpha2/resolve/main/dreamshaperXL10.safetensors -d /content/Fooocus/models/checkpoints -o dreamshaperXL10.safetensors
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/bluepen5805/blue_pencil-XL/resolve/main/blue_pencil-XL-v0.5.2.safetensors -d /content/Fooocus/models/checkpoints -o blue_pencil-XL-v0.5.2.safetensors
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://civitai.com/api/download/models/161009 -d /content/Fooocus/models/checkpoints -o CherryPickerXL-v2.6.safetensors
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://civitai.com/api/download/models/164360 -d /content/Fooocus/models/checkpoints -o BreakDomainXL-v05g.safetensors
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/Linaqruf/animagine-xl/resolve/main/animagine-xl.safetensors -d /content/Fooocus/models/checkpoints -o animagine-xl.safetensors
ComfyUIで使用する場合のAnimagine XL用JSONファイル
(以下のファイルをダウンロードして、ComfyUIの操作画面にドラッグ)
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/Kotajiro/fuduki_mix/resolve/main/fuduki_mix_v15_fp16.safetensors -d /content/Fooocus/models/checkpoints -o fuduki_mix_v15_fp16.safetensors
⑧ Emi
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/alfredplpl/emi/resolve/main/emi.safetensors -d /content/Fooocus/models/checkpoints -o emi.safetensors※Colabでこのモデルをダウンロードする場合は、非公式クローンのダウンロードリンク先からでないと、上手くダウンロードできません。

上記3.のComfyUIでも同様に他のモデルを追加できます。その場合は、以下のようにComfyUIのコードを書き換えます(Animagine XL 1.0の場合)。
base = "https://huggingface.co/Linaqruf/animagine-xl/resolve/main/animagine-xl.safetensors"
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M {base} -d /content/ComfyUI/models/checkpoints -o animagine-xl.safetensors
生成した画像例▼
以下は、それぞれ①CounterfeitXL、②DreamShaper XL1.0、③blue pencil-XL、④waifu-diffusion-XL(SDXL 0.9ベース)で生成した画像です。



7.おすすめノート(自分用)
以下のコードをcolabノートの新しいセルにコピーし、GPUで実行します。
最後にgradioのリンクをクリックすると操作画面が開きます。
モデルは、Cherry PickerXL v2.6、BreakDomainXL v05g、Fuduki Mix v1.5
%cd /content
!git clone https://github.com/lllyasviel/Fooocus
!apt -y install -qq aria2
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://civitai.com/api/download/models/161009 -d /content/Fooocus/models/checkpoints -o CherryPickerXL-v2.6.safetensors
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://civitai.com/api/download/models/164360 -d /content/Fooocus/models/checkpoints -o BreakDomainXL-v05g.safetensors
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/Kotajiro/fuduki_mix/resolve/main/fuduki_mix_v15_fp16.safetensors -d /content/Fooocus/models/checkpoints -o fuduki_mix_v15_fp16.safetensors
%cd /content/Fooocus
!pip install pygit2==1.12.2
!python entry_with_update.py --share8.SDXL 1.0を無料で試せるサイト
以下のClipdropのサイトで、SDXL 1.0を無料で試すことができます。アカウント登録すれば、生成できる画像の枚数を増やすことができ、有料会員になれば、さらに枚数を増やすことができます。