SBI証券の資産推移をグラフで表示する方法を考えてみる日記【その10】

さて、前回はローカルPCにダウンロードしてGoogle Driveに同期していた資産保有データのCSVファイルを、Googl Colabから読み込むところまでいきました。
今回は、このデータを加工していきます。必要なデータは、「株式(現物/特定預り)」の場合、「株式(現物/特定預り)」の次の行から、「株式(現物/特定預り)合計」の前の行までのデータです。必要なデータだけを新しいDataFrameに入れてあげれば良さそうです。
ということで、コードを追加していきます。
import pandas as pd
import os
import pprint
data_dir = '/content/drive/My Drive/資産管理/株式/PortFolioData/'
files = os.listdir(data_dir)
#pprint.pprint(files)
col_names = [ 'c{0:02d}'.format(i) for i in range(10) ] #CSVファイルの列数が10
accounts = ['株式(現物/特定預り)','投資信託(金額/特定預り)']
for i, file in enumerate(files):
base, ext = os.path.splitext(file) #ベース名と拡張子名を取得
if ext == ".csv" and i == 0: # CSVファイルの場合のみデータを読み込む
print(file)
df = pd.read_csv(data_dir + file, encoding="cp932", names = col_names)
for account in accounts:
index_from = df[df['c00'].str.contains(account)].index + 1
display(df)
index_to = df[df['c00'].str.contains(account + '合計')].index - 1
print(account)
print("from:" , index_from)
print("to:" , index_to)とりあえず1つ目のCSVファイルのみ実行するように変更しました。実行してみます。
株式(現物/特定預り)
from: Int64Index([7], dtype='int64')
to: Int64Index([], dtype='int64')index_fromにデータを取得する開始行、index_toにデータを取得する最終行を取りたいのですが、index_toの方が取得できていませんね。
データをよく見てみると・・・。
株式(現物/特定預り)
株式(現物/特定預り)合計
丸括弧が全角と半角でした・・・。文字列の後ろに「合計」を付与して検索しても見つからないわけですね。思い込みは怖いです。という訳でaccountsを2次元配列にして、口座ごとに始まりの文字列と終わりの文字列を入れるようにコードを修正します。
import pandas as pd
import os
import pprint
data_dir = '/content/drive/My Drive/資産管理/株式/PortFolioData/'
files = os.listdir(data_dir)
#pprint.pprint(files)
col_names = [ 'c{0:02d}'.format(i) for i in range(10) ] #CSVファイルの列数が10
accounts = [['株式(現物/特定預り)','株式(現物/特定預り)合計'],['投資信託(金額/特定預り)','投資信託(金額/特定預り)合計']]
for i, file in enumerate(files):
base, ext = os.path.splitext(file) #ベース名と拡張子名を取得
if ext == ".csv" and i == 0: # CSVファイルの場合のみデータを読み込む
print(file)
df = pd.read_csv(data_dir + file, encoding="cp932", names = col_names)
for account in accounts:
print(account[0])
index_from = df[df['c00'].str.contains(account[0])].index + 1
print("from:" , index_from)
print(type(index_from))
print(account[1])
index_to = df[df['c00'].str.contains(account[1])].index - 1
print("to:" , index_to)実行してみます
PortFolio20200907.csv
株式(現物/特定預り)
from: Int64Index([7], dtype='int64')
<class 'pandas.core.indexes.numeric.Int64Index'>
株式(現物/特定預り)合計
to: Int64Index([], dtype='int64')
/usr/local/lib/python3.6/dist-packages/pandas/core/strings.py:1954: UserWarning: This pattern has match groups. To actually get the groups, use str.extract.
return func(self, *args, **kwargs)あれ、toが取得できていないですね。pandas.Series.str.containsを見ると、第一引数は文字列か正規表現を使うとなっています。口座の終わり文字列に含まれる半角括弧が正規表現の特殊記号とみなされているようです。regex=Falseのオプションを指定すると正規表現で検索されないらしいので追加します。
あと、index_from, index_toは[]がついてリスト形式(?)で返ってきている様なので、0番目のindexを取得する様にします。
import pandas as pd
import os
import pprint
data_dir = '/content/drive/My Drive/資産管理/株式/PortFolioData/'
files = os.listdir(data_dir)
#pprint.pprint(files)
col_names = [ 'c{0:02d}'.format(i) for i in range(10) ] #CSVファイルの列数が10
accounts = [['株式(現物/特定預り)','株式(現物/特定預り)合計'],['投資信託(金額/特定預り)','投資信託(金額/特定預り)合計']]
for i, file in enumerate(files):
base, ext = os.path.splitext(file) #ベース名と拡張子名を取得
if ext == ".csv" and i == 0: # CSVファイルの場合のみデータを読み込む
print(file)
df = pd.read_csv(data_dir + file, encoding="cp932", names = col_names)
for account in accounts:
print(account[0])
index_from = df[df['c00'].str.contains(account[0], regex=False)].index[0]+1
print("from:" , index_from)
print(type(index_from))
print(account[1])
index_to = df[df['c00'].str.contains(account[1], regex=False)].index[0]
print("to:" , index_to)
print(type(index_to))
df = df[index_from:index_to]
display(df)実行してみます。株式の方はうまくいきましたが、投資信託の方でエラーが出ています。
IndexError: index 0 is out of bounds for axis 0 with size 0index 0がないと言っています。index_fromからindex_toでdfを上書きしているので、次のループでindex 0が見つからないのは当然ですね・・・。DataFrameを初期化している処理を一個下の階層に移動させます。
import pandas as pd
import os
import pprint
data_dir = '/content/drive/My Drive/資産管理/株式/PortFolioData/'
files = os.listdir(data_dir)
#pprint.pprint(files)
col_names = [ 'c{0:02d}'.format(i) for i in range(10) ] #CSVファイルの列数が10
accounts = [['株式(現物/特定預り)','株式(現物/特定預り)合計'],['投資信託(金額/特定預り)','投資信託(金額/特定預り)合計']]
for i, file in enumerate(files):
base, ext = os.path.splitext(file) #ベース名と拡張子名を取得
if ext == ".csv" and i == 0: # CSVファイルの場合のみデータを読み込む
print(file)
for account in accounts:
df = pd.read_csv(data_dir + file, encoding="cp932", names = col_names)
print(account[0])
index_from = df[df['c00'].str.contains(account[0], regex=False)].index[0]+1
print("from:" , index_from)
print(type(index_from))
print(account[1])
index_to = df[df['c00'].str.contains(account[1], regex=False)].index[0]
print("to:" , index_to)
print(type(index_to))
df = df[index_from:index_to]
display(df)実行してみます。
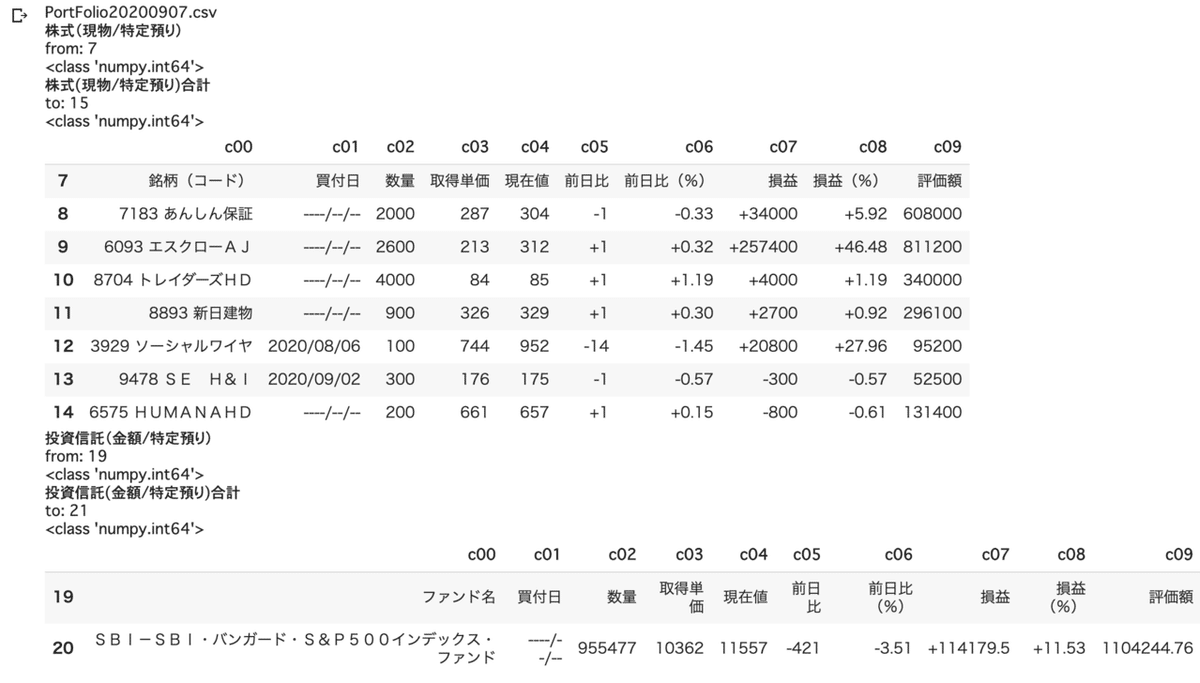
上手くいきましたね。カラム名がDataFrame初期化の際に暫定的に付与したカラム名のままなので、変更していきます。0行目をカラム名にして、その後0行目を削除すれば良いはずです。削除は0行目という形で指定してもなぜか上手くいかず、indexで指定すると上手くいきました。色々調べてみましたが原因はわかりませんでした。が、まぁいいでしょう。
コードはこんな感じになりました。
import pandas as pd
import os
import pprint
data_dir = '/content/drive/My Drive/資産管理/株式/PortFolioData/'
files = os.listdir(data_dir)
col_names = [ 'c{0:02d}'.format(i) for i in range(10) ] #CSVファイルの列数が10
accounts = [['株式(現物/特定預り)','株式(現物/特定預り)合計'],['投資信託(金額/特定預り)','投資信託(金額/特定預り)合計']]
for i, file in enumerate(files):
base, ext = os.path.splitext(file) #ベース名と拡張子名を取得
if ext == ".csv" and i == 0: # CSVファイルの場合のみデータを読み込む
print(file)
for account in accounts:
df = pd.read_csv(data_dir + file, encoding="cp932", names = col_names)
print(account[0])
index_from = df[df['c00'].str.contains(account[0], regex=False)].index[0]+1
index_to = df[df['c00'].str.contains(account[1], regex=False)].index[0]
df = df[index_from:index_to]
df.columns = df.iloc[0]
df.drop(index_from, inplace=True)
display(df)実行してみます。

上手くいきましたね。
次回は以前スクレイピングで取得したデータの書式に合わせるため、「年月日」のカラムを追加したり、不要な項目を削除していきたいと思います。以前スクレイピングで取得したデータの処理とほとんど同じような感じなのでそんなに苦労しないと思います。
では、今回はこの辺にしておきます。
この記事が気に入ったらサポートをしてみませんか?