
Webスクレイピング Part 3: TOEIC単語を例文の中で覚える ~ スクレイピング技術を活用して英語学習アプリを作ってみる!

正規表現、「なんちゃら」パターンのおさらい
前回のPart2では、"critical"という単語をもとに、WordHippoという辞書サイトから例文を抽出するプログラムを書いてみました。
でも当然疑問に思うのは「他のサイトでも同じコードが使えるの?」ということです。答えは残念ながらNOです。「なんちゃら」パターンでテキストを抽出できる正規表現はとても便利なのですが、そのパターンは当然サイトごとに変わってきます。
試しに別の辞書サイト、YourDictionaryを見てみましょう。
このサイトで"critical"の例文を取得するには、このURLを使います。
⇒ https://sentence.yourdictionary.com/critical
このページを開いたら、Part2でやったのと同様、ブラウザの検証ツールを使って最初の例文のHTMLがどうなっているかをチェックしてみます。
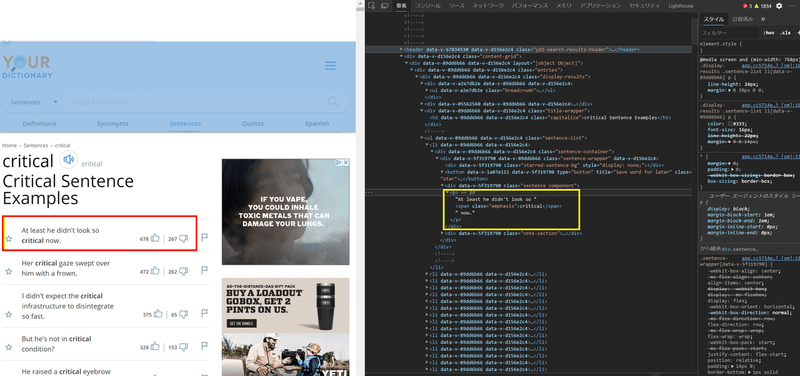
【例文】

【HTML】
<p>At least he didn't look so <span class="emphasis">critical</span> now.</p>
前回は、まず例文全体は<td>タグで囲まれ、単語のところは太字にする<b>タグでした。しかしここでは例文は<p>、単語は<span>が使われています。何が違うのかを理解するにはHTMLの知識が必要ですが、ここではそれは必要ありません。問題なのは「タグが違う」という事実です。このため「なんちゃら」パターンはこんな感じになります。
<p>なんちゃら<spanなんちゃら>なんちゃら</span>なんちゃら</p>
そして、これまた前回と同様、正規表現のところのコードはこうなります。
<p>.*?<span.+?>.+?</span>.+?</p>
行全体はこうなります。
var matches = Regex.Matches(html, @"<p>.*?<span.+?>.+?</span>.+?</p>");ということは、この正規表のコードはサイトごとに用意しないといけないということです。今回は英語の例文を抽出するのが目的なので、せいぜい2つか3つのサイトから例文が抽出できれば数百くらいの例文は簡単にゲットできます。ただ、いくつものサイトからデータを取り出したい場合、できれば一つのコードで全部対応できればそれが一番です。そこで有効なのがXPathという技術ですが、それは後のパートで解説していきます。今回のPartではまずは基本的なアプリの形を作っていきます。
英単語と例文データで何ができる?
正規表現を使って英単語と例文の取得ができるようになったので、それを活用したアプリを作ってみます。アイディアは皆さん次第ですが、ここでは次のようなアプリを作ってみます。
【英語例文100本ノックアプリ】
概要:TOEICなどの試験対策として英単語の理解をサポートするアプリ。ウェブサイトから英単語リストをリアルタイムでスクレイプし、それをもとにランダムに選んだ単語の例文を見ていきながら、文脈の中で単語の意味を覚える。
操作フロー:コンソールアプリ
❶ 開始するとコード内で指定したサイトから単語リストを取得
❷ その中からランダムに単語を1つ選択
❸ 単語に応じた例文を表示
✅ 日本語の辞書サイトから例文を取得する
✅ 英語例文を見た後に日本語訳が確認できるようにする
まずはこんなシンプルな仕様から始めてみます。機能拡張はあとからいくらでもできますので、最初はベースラインを固めることが大切です。
ではさっそく作業を開始していきます。

ステップ1:TOEIC英単語をコードでスクレイピング
Part 1ではParseHubというツールを使ってTOEIC英単語のスクレイピングをやりましたが、せっかくなのであれをプログラミングでやってみましょう。
【1】ターゲットページのHTMLを見てみる
ここもPart 2のおさらいですが、まずは英単語をスクレイプしたいサイトのHTMLを見てみます。サイトはこれでした。
まずは検証ツールで見るとこんな感じです。
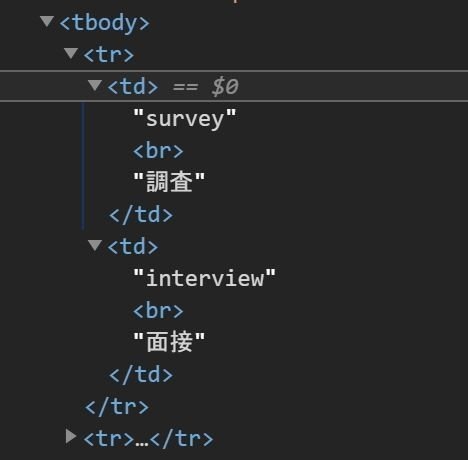
ここでの「なんちゃら」パターンはものすごく単純です。
<td>なんちゃら<br>なんちゃら</td>
だとすると正規表現はこれで決まりです。
<td>.+?<br>.+?</td>ただ、もう気が付いていると思いますが、最初のなんちゃらは英語の単語とマッチし、次のなんちゃらは日本語訳にマッチします。ここでは英単語だけを取得したいので、前半だけを抽出しないといけません。それを踏まえてコードを考える必要があります。
【2】基本コードを書いてみる
では英単語を抽出するところまでを書いてみましょう。Part2でのコードをほぼそのまま流用できます。変更した箇所はたったの3行です。どこかわかりますか?
using System;
using System.Net;
using System.Text.RegularExpressions;
namespace WebScrapingPart2
{
class Program
{
static void Main(string[] args)
{
//================================
//Webサイトを開いてHTMLを読む。
//================================
//単語サイトのURLを変数urlに入れる
string url = @"https://toiguru.jp/toeic-vocabulary-list";
//HTMLを読み込むWebClientを作る
var wc = new WebClient();
//WebClientのDownloadStringメソッドでHTMLを読み込む
string html = wc.DownloadString(url);
//================================
//単語のパターンを抽出する
//================================
//<td>なんちゃら<br>なんちゃら</td>に合致したテキストを取り出す
var matches = Regex.Matches(html, @"<td>(.+?)<br>.+?</td>");
//合致したものをすべて表示する
foreach (Match match in matches)
{
//マッチから英単語のところだけ抽出する
string sample = match.Groups[1].Value;
Console.WriteLine(sample);
};
Console.ReadLine();
}
}
}まずはターゲットとなるサイトが異なるのでここは変更します。
//単語サイトのURLを変数urlに入れる
string url = @"https://toiguru.jp/toeic-vocabulary-list";次に正規表現が異なるのでここも変更。
//<td>なんちゃら<br>なんちゃら</td>に合致したテキストを取り出す
var matches = Regex.Matches(html, @"<td>(.+?)<br>.+?</td>");ただしパターン文字列に関して一点異なるところに気が付きましたか?正規表現の最初のマッチ箇所に括弧を付けてあります。これは次の抽出コードを見れば理由が分かります。
//マッチから英単語のところだけ抽出する
string sample = match.Groups[1].Value;前回はタグのゴミがあったのでここではRegexのReplaceでゴミタグを取り除きましたが、今回はその必要はありません。正規表現で括弧を使う理由は「そこだけ抽出したい」という指定だからです。正規表現をもう一度見てみると、
<td>(.+?)<br>.+?</td>
ここになんちゃらが二か所あるのでマッチする部分は3か所あるのです(そうです2か所ではなく3か所なのです)。
1つ目は、<td>.+?<br>.+?</td>という全体のマッチ
2つ目は最初の.+?、つまり<td>.+?<br>.+?</td>のところ
3つ目は次の.+?、つまり<td>.+?<br>.+?</td>のところ
つまり正規表現は一般に全体と部分のマッチをすべて教えてくれて、コードではGroupsという属性を使って自由にそれを取り出すことができます。
1つ目はmatch.Groups[0].Value
2つ目はmatch.Groups[1].Value
3つ目はmatch.Groups[2].Value
英単語は[1]のところに入っています。ちなみにこの配列の数字を2に変えて実行してみてください。そして正規表現のところで二つ目の.+?にも括弧をいれてください。
@"<td>(.+?)<br>(.+?)</td>")これでアプリを実行すると今度は訳語だけが出てきました。
括弧を付けることでマッチ文字を自由自在に抽出できます。正規表現がいかにパワフルなツールか実感してきましたか?
ステップ2:単語をランダムにピックアップする
単語リストを抽出したら、そこから単語を一つ、ランダムに選択して、それをユーザーに示します。とりあえずこんなメッセージを出すのはどうでしょう?
「XXXという単語の例文を表示していきます」
using System;
using System.Collections.Generic;
using System.Net;
using System.Text;
using System.Text.RegularExpressions;
namespace WebScrapingPart2
{
class Program
{
static void Main(string[] args)
{
Console.OutputEncoding = Encoding.UTF8;
//================================
//Webサイトを開いてHTMLを読む。
//================================
//英単語サイトのURLを変数urlに入れる
string url = @"https://toiguru.jp/toeic-vocabulary-list";
//HTMLを読み込むWebClientを作る
var wc = new WebClient();
//WebClientのDownloadStringメソッドでHTMLを読み込む
string html = wc.DownloadString(url);
//================================
//単語のパターンを抽出する
//================================
//単語リストの変数を作る
var words = new List<string>();
//<td>なんちゃら<br>なんちゃら</td>に合致したテキストを取り出す
var matches = Regex.Matches(html, @"<td>(.+?)<br>(.+?)</td>");
//合致したものを単語リストに入れていく
foreach (Match match in matches)
{
//英語を単語リストに加える
words.Add(match.Groups[1].Value);
};
//================================
//単語リストからランダムに一つ選ぶ
//================================
Random r = new Random();
string word = words[r.Next(0, words.Count - 1)];
Console.WriteLine("次の単語の例文を表示します:" + word);
Console.ReadLine();
}
}
}
まず、抽出した単語を入れておく変数を用意します。ここでは文字列のList変数を使います。
//単語リストの変数を作る
var words = new List<string>();そしてスクレイピングで単語をゲットしたら、それをこの変数に一つ一ついれていきます。
//合致したものを単語リストに入れていく
foreach (Match match in matches)
{
//英語を単語リストに加える
words.Add(match.Groups[1].Value);
};これまではforeachループで単語を表示させていましたが、そのかわりにList変数に追加していくだけです。
ここまでで単語リストが完成です。その次はそのリストの中からランダムに1つ選択して画面に表示させます。
//================================
//単語リストからランダムに一つ選ぶ
//================================
Random r = new Random();
string word = words[r.Next(0, words.Count - 1)];
Console.WriteLine("次の単語の例文を表示します:" + word);ここでどうやって1000個もの単語の中からランダムに一つ選ぶかですが、Listから要素を一つ選ぶならList変数の中から一つを決め打ちすることができます。例えば12番目のものを選びたいとしたら、
words[12]のように数字を入れてあげればよいだけです(ちなみに12番目の要素インデックスは本当は11です)。でもここではその数字をランダムに決めてほしいわけです。そこでRandomというクラスを使って、0から1000までの間で適当に一つ選んでもらいます。それがこのコードです。
r.Next(0, words.Count - 1)
Randmoクラスrから、Nextというメソッドを呼び出すとランダムに数字を選んでくれます。ただ、今回は単語リストの数の中から選ぶようにするため、最低は0、最大は1000-1(インデックスが0から始まっているので)。ただ、1000という数字も決め打ちしないで、単語数はList変数から調べるようにします。それがwords.Count()というメソッドです。
これを実行するとこんな画面表示が出てきます。
次の単語の例文を表示します:foundationもちろんランダムなので、皆さんの画面には別の単語が表示されているはずです(偶然同じだったら1000分の1の確率でラッキーですね!)。これで「例文1000本ノック」を受ける単語が確定しました。次は例文を表示するステップをやってみますが、その部分は次のPart 4で解説していきます。
次回のPart 4では・・・
ランダムに選択された単語をもとに、例文サイトからスクレイプしてサンプル文章をどんどんと表示していきます。そこで、どのサイトを利用するかですが、仕様でも示した通り、できれば英文の日本語訳も表示させたいです。そこで日本の辞書サイトから次のものを選びました。
皆さんもこのサイトから英文とその訳文をスクレイプするにはどうしたらよいか、HTMLをじっくり研究してみてください。
この記事が気に入ったらサポートをしてみませんか?