
[イベントレポート]ノンプロ研Python初心者講座第5期卒業LT大会

久しぶりにnote書きます。今回は2021年6月14日に行われた、ノンプロ研のPython講座卒業ライトニングトーク(LT)大会のイベントレポートです。

卒業LT大会というのは、講座を受講してきた方が、講座で学んだ成果を発表するイベントで、ノンプロ研ではどの講座でも卒業LT大会があります。
受講者が講座の感想や、卒業制作、今後の目標などを熱く語る会となっております。
今回は受講者7名+TA(ティーチング・アシスタント)+Zoom準備などの運営を担当頂くホストの方+講師の計10名がそれぞれ発表しました。
当日の様子は以下、Togetterでもツイートまとめをしています。
ではいってみましょう~
ノンプロ研とは
ノンプロ研とは、ノンプログラマーがプログラミングをはじめとするITスキルを学び合うコミュニティ「ノンプログラマーのためのスキルアップ研究会」の略です。
現在、約140名のメンバーが所属していて、それぞれプログラミング言語やITツールの勉強や情報交換をしたり、遊んだり、飲んだりしています。
VBA・GAS・Pythonのプログラミング講座や、技術ライティング講座も開催されています。今回はPython初級講座の卒業イベントになります。
参加者の卒業LTまとめ
ノンプロ研には、成長にブーストをかけたくて入ったとのことです。もともとVBAは使われていて、今回は営業事務の仕事をPythonで自動化したくて、講座を受けたそうです。まずは自社のネットショッピングサイトをスクレイピングしてみたとのこと。講座でやっていないtkinterも自力で調べて使われていました。今後Pythonの活用法を探しているとのことで、ぜひノンプロ研を活用しながら改善を継続していって頂ければと思います。
スライドはプロレスネタ多め。パイソン・スミスって誰w
そして最後はゴングで終了。ネタ仕込みすぎwww
それはさておき、受講動機を振り返ってみたり、miroやSWOTを使って現状分析してみたりされていました。環境構築に苦労されたようですが、今後はPythonを活かして、職場で募集しているデータサイエンティスト育成に応募しようかとしているとのこと。ご活躍をお祈りしております~
普段からブログでも講座の内容をアウトプットされていました。講座と並行して、スクレイピングの副業案件をやってみたとのこと。Webサイトのデータをcsvに保存して、さらにJSONに変換するコードを作っていました。スクレイピングの副業はみんな興味があるらしく、懇親会でもいろいろ聞かれていました。私もスクレイピングの副業やってみたい。
なんとこれでノンプロ研全講座制覇とのこと。GAS講座でもTAされているので、つよつよ勢です。作ったツールをpyinstallerというライブラリでexe化したそうで、めっちゃ簡単にできた!とのことです。なんか単体で動くとツール作った感ありますね。そして講座と並行してデータサイエンス講座も受けていたとのことで、機械学習勉強中とのこと。さすがですね~
経理のお仕事でPythonを活用して、時間がかかる作業を自動化されていました。講座は楽しかった!とのこと。ノンプロ研の講座は受講者の横のつながりというか、一体感があっていいですね。頑張っている人に影響されるのがコミュニティのいいところです。講座の宿題はSlackで提出するのですが、他の人が書いたコードも見れるのもいいですよね。
くぼさん
普段は全くPCを使わない仕事をしているそうですが、「Pythonを少し使えるようになりました」と言えるようになったのが嬉しい。講座は初級のはずなのに他の人のレベルが高い問題。これはノンプロ研あるあるですね。特にPython講座はVBAやGASできる方が流れてくることが結構あるので、気にせずマイペースでやって頂ければよいと思います。今後画像認識をやってみたいとのことで、画像のスクレイピングにチャレンジしていました。今後の成長が楽しみです。
今回は、TA(ティーチング・アシスタント)として参加頂きました。宿題の添削や質問の回答など、大変お世話になりました。
発表はAPI活用とデータ整理ということで、APIを学ぶためのオススメコンテンツの紹介や、データ整理に使えるpandasの紹介をして頂きました。あと、オススメの本の紹介や、Webアプリを簡単に作れるStreamlitも紹介されていました。今後Pythonをさらに学んでいくためのヒントを頂けました。
なんとノンプロ研3講座同時受講という強者。宿題が大変だったとのこと。(そりゃそうだ)
ノンプロ研メンバー限定販売サイトをスタートするにあたって、ノンプロ研在籍ステータスを自己紹介サイトをスクレイピングすることで判定させたとのこと。gspreadライブラリでPythonからスプレッドシートを扱うのもやっていました。今流行りのPower Automate DesktopはMACで使えないので、Pythonでのスクレイピングはありがたいとのことです。夢は機械学習!
今回はZoomのホスト担当など、運営側として参加頂きました。社内のピープルアナリストというのに応募したら合格しちゃったとのことで、なんと4月からデータサイエンティスト(仮)見習い?らしい。いろいろツール作っているけど、「まだ何も分析してない」ということで、まずはできることから、そして今後は機械学習とかやりたいとのことです。今後が楽しみです~
私も発表しました!
今回のPython講座は、私も講師として参加していましたので、私も発表しました。
Python講座のゴールは「Pythonで実務で使える簡単なツールを作る」でしたので、ツール化するにあたってのインターフェースについて説明しました。
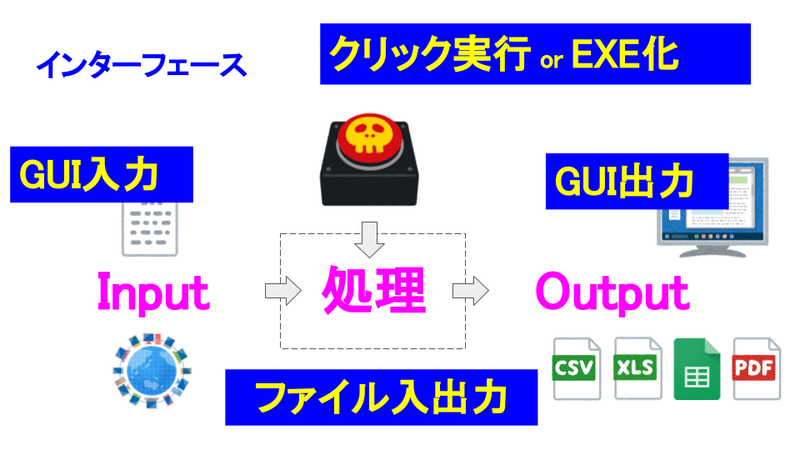
Jupyter Notebookは、コード書いたり、解析したりするのには向いてますが、スクリプトを単体のツールとして動かしたい時はちょっと面倒です。なので、PythonコードをPCでダブルクリックで実行したり、結果をGUIで表示したりするやり方があります。GUIは、PySimpleGUIというライブラリを使って、二次元リストをテーブル形式でGUIとして表示する方法を紹介しました。時間の関係でコードの説明まではできなかったので、別の機会に紹介したいと思います。
ちなみに、発表で言い忘れましたが、PySimpleGUIはツイッターでfuji.tさんに教えていただきました。知らないことって調べられないから、新しい情報をキャッチするアンテナも必要ですね。
気になる…
— fuji.t (@celaeno4) March 4, 2021
ゼロからはじめるPython(73) より簡単にデスクトップアプリが作れるPySimpleGUIを使ってみよう | TECH+ https://t.co/XNfwSK2iVN
まとめ
ということで、イベントの内容をまとめてみました。皆さん実務で使われていたり、将来の目標を熱く語って頂いたりで、とても良いイベントでした。Python中級講座開講への圧も強かったです。。
私もみなさんの発表を聞くことでエネルギーもらえました。まだまだPythonも勉強することが多いので、これからも引き続き学んでいきます。
ありがとうございました。そして、みなさま卒業おめでとうございます!

(おまけ)Togetterまとめのまとめ
Togetterからみんなのツイート内容をまとめて、ワードクラウドで可視化してみました。こんな感じでした~

これもPythonでのスクレイピング+形態素解析で作れます。講座受講された方にとってはそれほど難しくないと思います。役には立たないけど面白いので、興味がある方はやってみて下さい。
以下にコード貼っておきます。Jupyter Notebookで実行するとワードクラウドの画像が表示されます。
selenium, janome, wordcloud, matplotlibを使用しています。
import re
import matplotlib.pyplot as plt
from selenium import webdriver
from janome.tokenizer import Tokenizer
from wordcloud import WordCloud
url = 'https://togetter.com/li/1730840' # Togetterまとめのurl
browser = webdriver.Chrome('ドライバ格納場所')
browser.get(url)
# 最初のページのみ、全てのツイートを表示(残りを読むボタンクリックと同じ動作)
browser.execute_script('tgtr.moreTweets(this,' + url.split('/')[-1] + ');')
tweet_list = []
for tweet in browser.find_elements_by_class_name('tweet'):
tweet_list.append(' '.join(re.sub('[##()()]', '', tweet.text).splitlines()))
# 2ページ目以降の処理
page = 2
while True:
browser.get(f'{url}?page={page}')
if browser.current_url == url: # ページ数が上限を超えると最初のurlに飛ぶので、そうしたらループを抜ける
break
for tweet in browser.find_elements_by_class_name('tweet'):
tweet_list.append(' '.join(re.sub('[##()()]', '', tweet.text).splitlines()))
page += 1
browser.quit()
# 形態素解析
t = Tokenizer()
words = []
for text in tweet_list:
tokens = t.tokenize(text)
words += [token.surface for token in tokens if token.part_of_speech.startswith('名詞')]
# ノイズ除去処理
mod_words = [word for word in words if word != 'さん']
word_list = ' '.join(mod_words).replace('ノンプロ 研', '')
# WordCloudで表示
wordcloud = WordCloud(
font_path = r'C:\Windows\Fonts\meiryob.ttc',
width = 2000, height = 1000,
background_color = 'white',
).generate(word_list)
plt.figure(figsize = (100, 50))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()最後まで読んで頂き、ありがとうございました。