
AI技術の変遷1 AI誕生からディープラーニングまで

AIという言葉が生まれる前の状況を知ることは、AI技術の進化を理解する上で重要です。ここでは、AIという言葉が誕生する以前から、AIの概念が形成されるまでの歴史を振り返ります。
AIの誕生前夜:1940年代から1950年代まで
1940年代:戦時中の計算技術の発展
AIという言葉は、1956年にアメリカで開催された「ダートマス会議」で初めて使われました。それ以前の1940年代、特に第二次世界大戦中には、弾道計算や暗号解読が重要な軍事技術として発展しました。

写真提供:© Schuppi, CC BY-SA 3.0, via Wikimedia Commons
弾道計算は公式を使えば正確な答えを導き出せますが、暗号解読はそう簡単ではありませんでした。この時期に、後にAIの分野で知られることになるアラン・チューリングが暗号解読の業務に従事していました。

写真提供:パブリックドメイン, via Wikimedia Commons
戦時中の軍事計算技術の進歩により、専用の計算機が開発されました。アメリカでは終戦頃に、現代のコンピュータの祖先であるEDVACが誕生しました。この開発には、ジョン・フォン・ノイマンが関わっています。

写真提供:パブリックドメイン, via Wikimedia Commons
1950年代:計算技術の進展とAIへの関心
戦後の1950年代、ジョン・フォン・ノイマンらの活躍により、計算やアルゴリズムがさらに発展しました。当時のコンピュータは、現在ほどの能力は持っていませんでしたが、複雑な計算やタスクを行う能力を備え始めていました。これにより、機械が人間のような「知能」を持つことができるかどうかへの関心が高まりました。
チューリングテストの誕生
しかし、「知能があるとは何か?」という漠然とした問いに対する解決策が必要でした。アラン・チューリングは、機械に「知能がある」と言えるかどうかを客観的に測定する方法として、チューリングテストを提案しました。
チューリングテストでは、人間の審査員が正体を隠したふたりの話者とチャットで対話し、一方が機械である場合でも人間だと判断されれば、その機械には知能があるとみなされます。このテストは現在でも知能を評価する一つの指標となっています。
1956年:ダートマス会議
1956年、アメリカの数学者・コンピュータ科学者であるジョン・マッカーシーが、「機械が知能を持つことができるか」を探求するためにダートマス会議を提案しました。この会議はアメリカのダートマス大学で開催され、「人工知能(Artificial Intelligence)」という言葉が初めて使われました。

写真提供:© Paul Lowry, CC BY-SA 2.0, via Wikimedia Commons
なお、アラン・チューリングは1954年に亡くなっており、ジョン・フォン・ノイマンも核兵器の影響で健康を害し、1957年に亡くなったため、両者はこの会議に出席していませんでした。
この会議で、AIとは「コンピュータやロボットなどに人間のような知的な情報処理能力を持たせる技術」として定義されました。これが現在のAI技術の基盤となっています。
1950~1970年代:第一次AIブーム
ゲームAIの研究
1950年代から1970年代にかけて、第一次AIブームが起こりました。この時期のAI研究は、主にゲームの勝利を目指したものでした。ゲームには明確なルールと勝利条件があり、AIアルゴリズムの評価が容易であったため、研究の対象として最適でした。また、ゲームの計算は多くの処理能力を必要とするため、コンピュータの性能評価にも適していました。
木構造とミニマックス法
ゲームの手順を探索するために、木構造(ツリー構造)が用いられました。

木構造では、1つの親ノードから複数の子ノードが枝分かれする形状で手順を表します。しかし、チェスの手の組み合わせは膨大であり(10の120乗)、すべての手を計算するには宇宙の年齢より長い時間がかかるとされています。
そこで、計算量を減らす工夫として、ノイマンが1928年に提唱したミニマックス法が用いられました。この手法は1950年代から使われ始めました。
ミニマックス法の概要
ミニマックス法は、次のような手順でチェスのようなゲームの手を計算します。
探索の打ち切り深さを決める。
最深部の局面から逆に、局面の良し悪しに点数を付ける。
自分は最高点の手を選び、相手は自分にとって最悪の手(最低点)を選ぶ。
この手法では、相手の点数を最小化(mini)、自分の点数を最大化(max)することから「ミニマックス」と呼ばれます。
さらに、アルファベータ法という計算量を減らす工夫も加えられました。これは、悪い手の先は探索しないという手法です。このような方法により、1997年にはAI「ディープブルー」がチェスの世界チャンピオンに勝利しました。
第一次AIブームの終息
1970年以降、第一次AIブームは一旦下火となりました。ゲーム以外の実世界の問題では、ミニマックス法のような方法で解決できるものが少なかったためです。
その理由としては、以下の点が挙げられます。
実世界の問題は、必ずしも2人の対立するプレイヤーによる状況ではない。
データの収集や保存、処理が容易でなかった。
このように、第一次AIブームはゲームAIの研究によって大きな成果を挙げましたが、実世界の複雑な問題には対応できず、一旦停滞期を迎えました。次のブームに向けて、AI技術のさらなる進化が求められることになります。
1980年~ 第二次AIブーム
エキスパートシステムの登場
1980年代の第二次AIブームでは、専門家の知識やルールをコンピュータに入力する「エキスパートシステム」が流行しました。エキスパートシステムは、専門家の行動ルールを人間が作成し、それをコンピュータにインプットすることで動作します。これにより、専門家の知識をコンピュータ上で再現することが試みられました。
エキスパートシステムの仕組み
エキスパートシステムでは、木構造を用いて知識を表現し、ルールに基づいて回答を導出します。例えば、病名診断の木構造では、次のような手順で診断が進みます:
「発熱があるか?」が根本の質問
「次に咳があるか?」など順次質問し、病名を特定する

このように、質問と回答を繰り返していくことで、最終的な診断結果を導き出します。
課題と終焉
エキスパートシステムには、いくつかの課題がありました。
ルールの作成とメンテナンスは人手で行う必要があり、非常に手間がかかる
曖昧な表現を扱うのが難しい
これらの課題により、エキスパートシステムは限界を迎えました。500億円以上の予算が投入されたにもかかわらず、第二次AIブームは終焉を迎えることとなりました。
機械学習の進展
1980年代後半から2000年代にかけて、コンピュータの処理能力が向上し、機械学習の研究が進展しました。機械学習とは、コンピュータが自動で学習し、データからルールやパターンを発見する手法です。
この時期の代表的な機械学習手法には以下がありました:
決定木生成:データを基に木構造を自動生成する手法
サポートベクターマシン(SVM):データを分類するための効果的な手法
ニューラルネットワーク:2層程度のシンプルなモデル
強化学習:環境との相互作用を通じて最適な行動を学ぶ手法
機械学習の実用化
1990年代後半から2000年代にかけて、これらの機械学習手法が実用化され始めました。エキスパートシステムとは異なり、機械学習ではデータから自動的にルールを抽出することができます。これにより、専門家の手を借りずに、より効率的かつ柔軟に知識を獲得することが可能になりました。
決定木生成の仕組み
決定木生成機械学習は、エキスパートシステムで使用される木構造の作成を自動化する手法です。この手法では、正解データ(学習データ)とアルゴリズムを与えることで、最適な決定木構造を自動生成します。例えば、患者の状態と病名の正解データを事前に用意する(教師あり学習)ことで、アルゴリズムが情報獲得量の大きい質問を上位に配置し、効率的な診断を可能にします。「発熱があるか?」が根本に来る可能性が高くなり、その後「次に咳があるか?」などの質問が続く形です。
過学習の問題
決定木には「過学習」という課題があります。過学習とは、訓練データに過度に適合してしまい、新規データに対して適切な予測や判断ができなくなる状態を指します。決定木の場合、質問が非常に細かくなりすぎると、新しいデータに対する予測が不適切になることがあります。

ニューラルネットワーク
ニューラルネットワークは、人間の脳の神経細胞(ニューロン)の機能を模倣して、コンピュータ上で再現したものです。この技術は、手書き数字の認識などに応用されています。人工ニューロンは、入力された情報(例:合格・不合格)を受け取り、特定のルール(閾値)に基づいて出力(合格・不合格)を決定します。
重みと閾値
各ニューロンの入力は重み付けされており、重要な入力にはより高い点数が割り当てられます(例:A=1.2点, B=1.6点)。
閾値は、合格・不合格を決めるための基準点です。ニューラルネットワークは複数のニューロンが連携することで、脳のように複雑な判断を可能にします。各ニューロンの重みと閾値が適切に設定されることで、効果的な判断が行えるようになります。

サポートベクターマシン(SVM)
サポートベクターマシン(SVM)は、データを分類するための効果的な手法で、手書き文字認識、音声認識、タンパク質データ分析など、さまざまな分野で使用されています。SVMの目的は、データを2つのクラスに明確に分けることです。これを実現するために、最大マージンを持つ境界線(決定境界)を見つけ出し、データポイントを分類します。
SVMの直感的な説明
SVMを直感的に説明すると、散布図上に点がプロットされたとき、2つのグループを最も効果的に分ける直線を見つけるイメージです。まるで運動場で男の子と女の子を分ける線を引くようなものです。
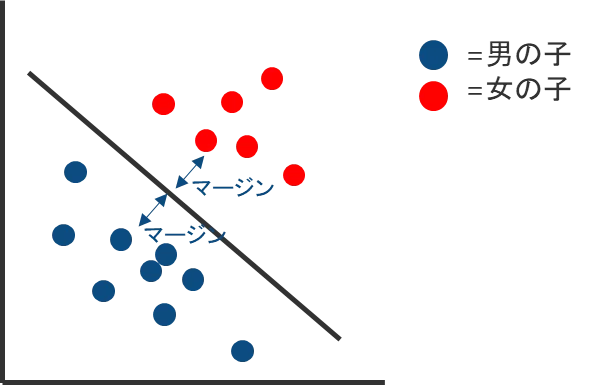
線形分離不可能な場合
データが線形分離不可能な場合、カーネル法を使用してデータをより高次元の空間にマッピングし、適切な決定境界(超平面)を見つけます。例えば、平面上では分けられないグループを3次元空間に移し、適切な高さで切断することで分類します。
→位置を変えないまま、小高い山がある場所に移動してもらい、横からスパッと上下で切り分けるイメージ。すると、切れ目は上から見ると図のような円となる。

この方法により、曲線や複雑な形状の境界線も描くことができます。
特徴と利点
SVMは学習には時間がかかる場合がありますが、一度トレーニングが完了すると、予測は非常に高速に行えます。そのため、実用的なアプリケーションにおいて高いパフォーマンスを発揮します。
1990年代後半のAI技術の問題点
技術的制約
1990年代後半のAI技術にはいくつかの技術的な制約がありました。
コンピュータの性能限界:
早期のコンピュータは計算能力が限られており、深いニューラルネットワークの構築や複雑なモデルの訓練が困難でした。勾配消失問題:
ネットワーク層を深くすると、重みの学習がうまく行かない「勾配消失」という問題が発生しました。これは、学習過程で重みの更新が十分に行われなくなることを意味します。パーセプトロンと多層パーセプトロン:
最初期のモデルは単層か、せいぜい一つの隠れ層を持つ多層パーセプトロンに限られており、複雑なタスクには対応できませんでした。ディープラーニングの欠如:
1980年代のモデルでは層が少ないため、ディープラーニングとは言えない状態でした。単純な数字の認識は可能でしたが、複雑な画像やパターンの認識は不可能でした。
データの制約
データ収集と管理の難しさ:
大量のデータを必要とするAIアルゴリズムに対して、データの収集や管理の技術が追いついていませんでした。強化学習の限界:
効率的なアルゴリズムが存在しなかったため、強化学習の適用は非効率で困難でした。
2010年代~ ディープラーニングによる第三次AIブーム
2010年代に入り、ディープラーニング技術が進化し、AI分野における第三次ブームが起こりました。これには以下の要因が大きく関与しています。
計算能力の向上:
GPUという高い計算能力を持つ装置の登場により、計算能力が飛躍的に向上しました。データの増加:
インターネットの普及により、大量のデータが容易に入手可能になりました。これにより、大規模データセットを利用した学習が現実的かつ実用的になりました。
再注目されたニューラルネットワーク
しばらく下火だったニューラルネットワークは、2012年頃から再度注目され始めました。特に、ジェフリー・ヒントン氏率いるカナダの研究チームが開発したAlexNetが、国際的な画像認識コンテストで圧倒的なパフォーマンスを示しました。この成果により、ディープラーニングが一気に注目を集めるようになりました。
次回は、ディープラーニング技術の具体的な仕組みや、ChatGPTで使われるトランスフォーマーの技術について詳しく説明していきます。
この記事が気に入ったらサポートをしてみませんか?