
ChatGPT4:ノーコードでPythonデータ可視化 Pt.4 [データ前処理の続き]

はじめに
ChatGPTを介してPythonを使うと、これまでとは感覚が変わります。
これまでは、
あるデータを〇〇のように変換したい
というときは、処理の仕方をいろいろ探して、それなりに学習して、やってみて… ということを繰り返す必要がありましたが、ChatGPTを使うと
「このデータを〇〇のように変換して」というだけ…
これは、隣にいる同僚に(Pythonのことは、まったく意識せず)適当に伝えてやってもらう感覚です。
以下、簡単な内容ではありますが、仮想データを準備し、データの前処理をChatGPTにやってもらいました。
仮想データについて
以下が準備した仮想データです。
かなり乱れていますが、現実はこのようなデータが多いと思います。
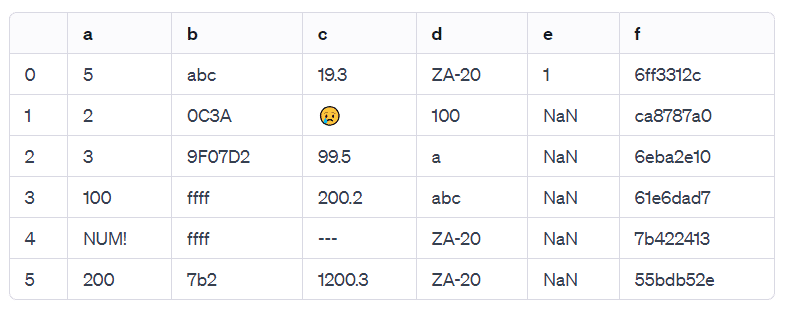
列a には、NUM! があります。これはEXCELでよく見るエラー表示です。
列b, f は、16進数です。このままでは可視化や分析はできません。
列c には、異常な値(文字:😢, ---)があります。
列d は、カテゴリー? 数値?、型式?… 数値も10進数?16進数?よくわかりませんね。
列e にある np.nan は欠損値です。データのほとんどが欠損値になっています。
何らかの前処理を行わないと、このままでデータ可視化するのはしんどいですね。
ChatGPT によるデータの前処理
まず、ChatGPTに上記の仮想データを与えました。
「列a~f に指定したデータをデータフレームに格納して表示して」というPythonのコードを与えています。
これは前処理を行うデータを与えているだけです。Pythonをご存じない方は「ふーん」でよいと思います。
以下を実行して下さい。
df = pd.DataFrame({
'a': [5, 2, 3, 100, NUM!, 200],
'b': ['abc', '0C3A', '9F07D2','ffff','ffff','7b2'],
'c': [19.3, 😢, 99.5, 200.2, ---, 1200.3],
'd': ['ZA-20', '100', 'a','abc','ZA-20','ZA-20'],
'e': [1, np.nan, np.nan, np.nan, np.nan, np.nan],
'f': ['6ff3312c', 'ca8787a0', '6eba2e10', '61e6dad7', '7b422413', '55bdb52e']
})
print(df)
データフレームが作成され、無効または不明な値は `np.nan` で置き換えられました。以下がその内容です:
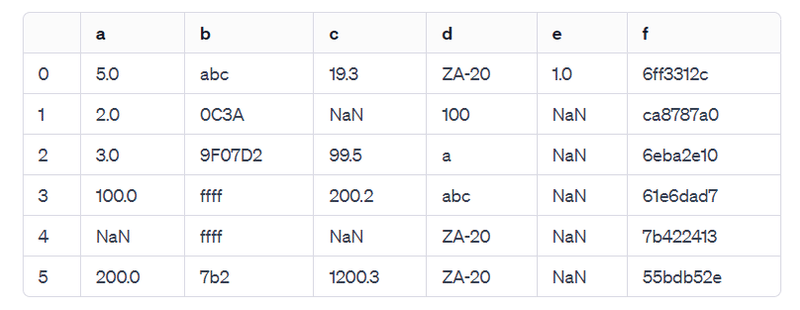
このデータフレームは6行と6列から構成されています。列 'a' と 'c' は数値型、列 'b'、'd'、および 'f' は文字列型、列 'e' は数値型で欠損値が含まれています。
な、なんと、ChatGPTは 指示しなくても無効または不明な値(=NUM!, 😢, ---)を欠損値と判断し、親切にNaN に置き換えてくれました。
なんて気が利くんだ。
次に、(わかってはいますが)ChatGPTに以下を指示しました。
指示:16進数のデータ列を教えてください。
16進数のデータを含む列を特定するためには、各列のデータが16進数の形式(0-9の数字とA-Fの文字)に従っているかどうかを確認する必要があります。このデータフレームでは、列 'b' と列 'f' が16進数のデータを含んでいる可能性が高いです。これを確認するために、これらの列の値が16進数の形式に適合しているかどうかをチェックしましょう。
データフレーム内の列 'b' と列 'f' はどちらも16進数のデータを含んでいます。これらの列の各値が16進数の形式(0-9の数字とA-Fの文字)に適合していることが確認されました。
ちゃんと認識してくれました。
列e のデータの中に 16進数らしき値がありますが、この列は違うなと解釈したのでしょう。
続けて、ChatGPTに以下を指示しました。
指示:列 'b' と列 'f' を10進数に変換して、データフレームを書き出してください。
列 'b' と列 'f' を10進数に変換した後のデータフレームは以下の通りです:
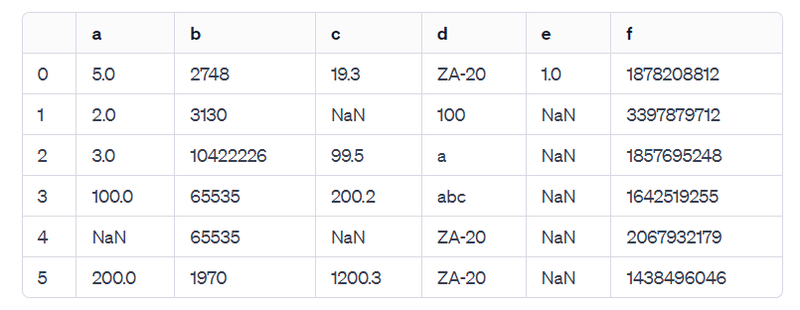
これで、列 'b' と列 'f' の値が10進数に変換され、他の列の値はそのまま保持されています。
データらしくなってきましたね。
次は、欠損値(NaN)の処理です。
欠損値の数が少ない場合は、欠損値を含む行データを削除したり、欠損値が多い列データを削除することもありますが、今回は ある値に置換することにします。
指示:NaN を-99に置換してください。
NaN 値を -99 で置き換えた後のデータフレームは以下の通りです:
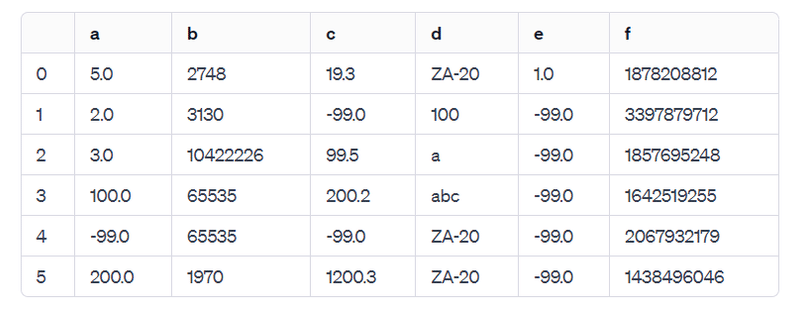
すべての列にわたってNaN値が-99で置き換えられました。
次に、(わかってはいますが)カテゴリーデータの列があるかを尋ねてみます。
指示:カテゴリーデータの列はありますか?
カテゴリーデータは、限られた数の繰り返し可能なカテゴリやグループに分類されるデータです。このデータフレームを見ると、数値データ(列 'a'、'b'、'c'、'e'、'f')とテキストデータ(列 'd')が含まれています。この中で、列 'd' はカテゴリーデータと考えられます。なぜなら、この列は限られた数の繰り返し可能な文字列値('ZA-20'、'100'、'a'、'abc')を含んでいるからです。他の列は数値データであり、明らかなカテゴリー分けはされていないようです。
ChatGPTからの回答に疑問の余地なしってことで、次に以下を指示しました。
指示:列 'd' をラベルエンコーディングしてください。
列 'd' をラベルエンコーディングした結果は以下の通りです。新しい列 'd_encoded' が追加され、元のテキスト値が数値に変換されています:
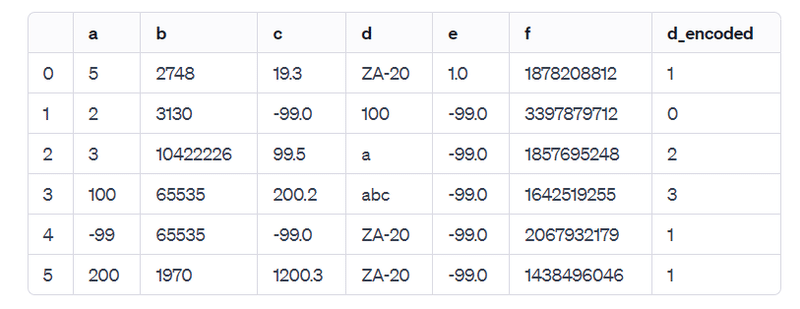
ここで、ラベルエンコーダーは各異なる文字列を一意の整数に変換しています。例えば、'ZA-20' は 1 に、'100' は 0 に、'a' は 2 に、そして 'abc' は 3 に変換されています。
うん。データらしくなりましたね。
最後に、ChatGPTに以下を指示しました。
指示:エンコーディング後のデータでペアプロットを描いてください。ペアプロットはd_encodedで層別し、プロットが見やすいように色を分け、プロット形状は「丸型」にしてください。

ペアプロットを作成しました。このプロットは、データフレームの数値列間の関係を示しており、列 'd_encoded' によって層別され、色分けされています。プロットの形状は丸型で表現されています。このプロットから、異なる変数間の関係やパターンを視覚的に分析することができます。
最後に
データを見ながら ChatGPTに前処理を指示… これを繰り返すだけ。
めっちゃ楽です。
こちらは「いうだけ」ですから。
参考
上記の内容を Pythonだけ で実行する場合、そこそこ手間がかかります。
以下は、Pythonによる前処理実行の手間を抑えるためにテンプレートを作成したという記事です。
これを振り返っても、テンプレートを利用するより、ChatGPTにお願したほうが早いし、楽です。
※この記事で紹介した前処理は一例です。
例えば、列c の「---」というデータは、ChatGPTは気を利かして「NaN」にしてくれましたが、何らかの意図をもって書き込んだ記号なら、「”---”は欠損値ではなく異常を示す記号なので、-999に置換して」と伝えて対応する等、任意です。
このようにどのような前処理を行うか?は目的によります。
よろしければサポートお願いします!