
Datastream for BigQuery で Incremental な分析環境を作ってみた

こんにちは。トレタの CTO の鄧(でん)です。今回はトレタ Advent Calendar 2022 12 月 3 日分の記事でデータ基盤と分析環境の話です。
トレタでは約 1,944 GiB (RDS バックアップサイズ) のデータベースを扱っており、一般的な daily バッチ式の ETL では時間がかかり過ぎるため、元々 Debezium ベースの内製ツールを使って AWS にあるプロダクション環境 (MySQL) と GCP BigQuery で構築された分析環境を極めて高い頻度(数分間程度の遅延)で俗にいう CDC (Change Data Capure) 方式で同期させてました。ただ内製ツールだったので CDC の抽出・BigQuery へのストリームインサート・CDC ログからのテーブル構造復元の保守運用コストが課題になっておりました。この度は GCP よりサーバーレスなフルマネージドサービスという形で Datastream for BigQuery がリリースされたのでこれを使ってデータ基盤のアップグレードを検証しております。
Datastream for BigQuery はまだ Preview 段階のサービスで SLA が保証されていないのでご利用の際にはご注意ください
Datastream 自体の設定は極めて簡単で、元々 AWS と GCP の間に VPN トンネルがあったのでその上で MySQL 側の Connection Profile (データベースの ID / password を保管するデータ構造) を作り、同期する内容と BigQuery 側のデータセットや許容する遅延を設定するたけで作れます。
現状唯一事前に考慮しないといけないこととして MySQL 側のデータと BigQuery 側のデータの同期する頻度や許容される遅延 (staleness limit) を最短 0 秒から最大 1 日まで設定出来ますが、低遅延にすればするほど処理が発生して BigQuery の処理コストがかかってしまうのでユースケースやお財布事情との兼ね合いを考えないといけません。2022 年 12 月現在、 staleness limit は一度設定したら変更できないのでご注意ください。
Datastream は CDC でよくある最初に既存のデータをとってくる Backfill というプロセスがあって、その後に binlog を追って同期する仕組みになっており、初回限りの Backfill が終わってから staleness limit を監視するような運用になっており、今の所 Preview とはいえかなり安定しております。
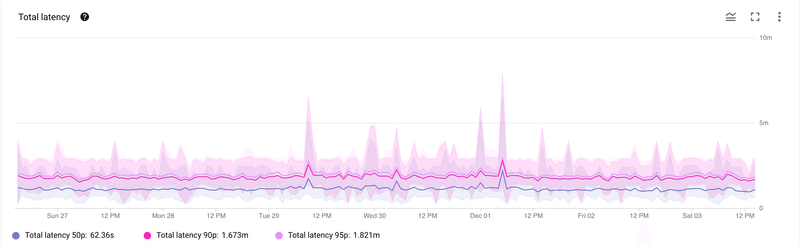
遅くても 8 分以内には BigQuery に反映されている
Preview 状態から GA になったらほぼ MySQL の 1:1 コピーが BigQuery 上にある状態になりますが、アプリケーションのデータベース(俗にいう OLTP)と分析として扱いやすいデータベース(俗にいう OLAP)は必ずしも 1:1 である必要はなく、むしろアプリケーションデータベースの高度な正規化に対して逆に分析用のデータベースはデータを反正規化(denormalization / pre-join)して分析用のクエリーを加速させる傾向があります。
これに関しては現状まだ対応されていないのですが、将来的には BigQuery の Materialized View を使って分析用途に合わせて加工したデータセットを作っていこうと考えております。

飲食店とはいえ、トレタの顧客は極めて高い安定性・可用性を求めているので。元々自前で内製ツールやバッチ処理を運用していた頃はバッチの成功 / 失敗で一喜一憂してた頃もありました。今後はこのような仕組みが徐々に増えていくことによって監視業務こそ変わりませんが、より安定した基盤を提供しつつ、より高度な機能開発にフォーカス出来るのではないかと考えております。
最後に、トレタではデータエンジニア(正社員・副業・インターン歓迎)を採用しており、もしご興味ありましたらぜひ一緒に面白い仕組みを作っていきましょう。
詳細はこちら。https://corp.toreta.in/recruit/midcareer/
この記事が気に入ったらサポートをしてみませんか?