
Google Colabで時系列基盤モデルを試す③:IBM granite

はじめに
前々回のGoogle Timesfm、前回のMomentに引き続き、HuggingFaceにある商用可能なライセンスの時系列基盤モデルを4つ試し、比較していきたいと思います。
利用するデータはETTh1という電力変圧器温度に関する多変量時系列データセットです。事前学習にこのデータが含まれる可能性があるため、モデルの絶対的な評価に繋がらないことに注意してください。
ダウンロード数:4.59k
モデルサイズ:200m
ライセンス:Apache-2.0
ダウンロード数:5.79k
モデルサイズ:385m
ライセンス:MIT
ibm-granite/granite-timeseries-ttm-v1 (今回)
ダウンロード数:10.1k
モデルサイズ:805k (小さい!!)
ライセンス:Apache-2.0
ダウンロード数:256k (多い!!)
モデルサイズ:709m
ライセンス:Apache-2.0
6月2日時点でダウンロード数が少ない順に実施していきます。
今回はIBMのgranite-timeseries-ttmです。graniteはIBMの出している言語モデルの名前で、その時系列版ということのようです。
TTMはTinyTimeMixersの略です。このモデルは他の3つとは方向性が異なり、"Tiny"であることを特徴としています。実際、TimesFMの1/250、chronos-t5-largeの1/1000ほどのサイズです。
現在のバージョンでは分単位から時間単位の予測タスクをサポートしているようです。
MOMENTと同様にGraniteもそのチュートリアルでETTh1のデータが使用されているので、ETTh1が事前学習で利用されていることはないと思います。
1. 推論
ライブラリの準備
# library install
!pip install git+https://github.com/ibm-granite/granite-tsfm.gitデータ準備
前回同様ETTh1.csvを使います。取得はこちらから可能です。
import pandas as pd
# データ読み込み
# https://github.com/zhouhaoyi/ETDataset/blob/main/ETT-small/ETTh1.csv
df = pd.read_csv("ETTh1.csv")
print(len(df))
df.head(2)データは以下のような形式です。OT(Oil Temperature)が目的変数となります。

データ加工
モデルに与える長さを512、予測する長さを96と今回はおきます。Fine Tuningに使うため、後ろから予測するデータをとっておきます。
前回とはモデルに与えるTensorの形が異なることに注意してください。
import torch
context_length = 512
forecast_horizon = 96
# データセット分割
df_train = df.iloc[-(context_length+forecast_horizon):-forecast_horizon]
df_test = df.iloc[-forecast_horizon:]
# 形式の変更
train_tensor = torch.tensor(df_train[["HUFL", "HULL", "MUFL", "MULL", "LUFL", "LULL", "OT"]].values, dtype=torch.float)
train_tensor = train_tensor.unsqueeze(0)
test_tensor = torch.tensor(df_test[["HUFL", "HULL", "MUFL", "MULL", "LUFL", "LULL", "OT"]].values, dtype=torch.float)
test_tensor = test_tensor.unsqueeze(0)モデルの取得
今回は512のInputから96を予測するのでTTM_MODEL_REVISION = "main"を使用します。1024の長さのInputから96の長さのデータを予測するモデルもあるようで、その場合はrevisionに"1024_96_v1"を指定してください。
graniteでは入力、予測の長さは512(1024), 96で固定のようです。
from tsfm_public.models.tinytimemixer import TinyTimeMixerForPrediction
# TTM model branch
# Use main for 512-96 model
# Use "1024_96_v1" for 1024-96 model
TTM_MODEL_REVISION = "main"
model = TinyTimeMixerForPrediction.from_pretrained(
"ibm/TTM", revision=TTM_MODEL_REVISION
)
model.to("cuda:0")modelは以下のような構成です。Encoder-Decoder Architectureのようですが、Momentやchronos-t5と違いT5ベースではなくオリジナルのアーキテクチャを採用しています。
また、Momentと異なり予測用のHeadもあらかじめ学習されています。
TinyTimeMixerForPrediction(
(backbone): TinyTimeMixerModel(
(encoder): TinyTimeMixerEncoder(
(patcher): Linear(in_features=64, out_features=192, bias=True)
(mlp_mixer_encoder): TinyTimeMixerBlock(
(mixers): ModuleList(
(0): TinyTimeMixerAdaptivePatchingBlock(
(mixer_layers): ModuleList(
(0-1): 2 x TinyTimeMixerLayer(
(patch_mixer): PatchMixerBlock(
(norm): TinyTimeMixerNormLayer(
(norm): LayerNorm((48,), eps=1e-05, elementwise_affine=True)
)
(mlp): TinyTimeMixerMLP(
(fc1): Linear(in_features=32, out_features=64, bias=True)
(dropout1): Dropout(p=0.2, inplace=False)
(fc2): Linear(in_features=64, out_features=32, bias=True)
(dropout2): Dropout(p=0.2, inplace=False)
)
(gating_block): TinyTimeMixerGatedAttention(
(attn_layer): Linear(in_features=32, out_features=32, bias=True)
(attn_softmax): Softmax(dim=-1)
)
)
(feature_mixer): FeatureMixerBlock(
(norm): TinyTimeMixerNormLayer(
(norm): LayerNorm((48,), eps=1e-05, elementwise_affine=True)
)
(mlp): TinyTimeMixerMLP(
(fc1): Linear(in_features=48, out_features=96, bias=True)
(dropout1): Dropout(p=0.2, inplace=False)
(fc2): Linear(in_features=96, out_features=48, bias=True)
(dropout2): Dropout(p=0.2, inplace=False)
)
(gating_block): TinyTimeMixerGatedAttention(
(attn_layer): Linear(in_features=48, out_features=48, bias=True)
(attn_softmax): Softmax(dim=-1)
)
)
)
)
)
(1): TinyTimeMixerAdaptivePatchingBlock(
(mixer_layers): ModuleList(
(0-1): 2 x TinyTimeMixerLayer(
(patch_mixer): PatchMixerBlock(
(norm): TinyTimeMixerNormLayer(
(norm): LayerNorm((96,), eps=1e-05, elementwise_affine=True)
)
(mlp): TinyTimeMixerMLP(
(fc1): Linear(in_features=16, out_features=32, bias=True)
(dropout1): Dropout(p=0.2, inplace=False)
(fc2): Linear(in_features=32, out_features=16, bias=True)
(dropout2): Dropout(p=0.2, inplace=False)
)
(gating_block): TinyTimeMixerGatedAttention(
(attn_layer): Linear(in_features=16, out_features=16, bias=True)
(attn_softmax): Softmax(dim=-1)
)
)
(feature_mixer): FeatureMixerBlock(
(norm): TinyTimeMixerNormLayer(
(norm): LayerNorm((96,), eps=1e-05, elementwise_affine=True)
)
(mlp): TinyTimeMixerMLP(
(fc1): Linear(in_features=96, out_features=192, bias=True)
(dropout1): Dropout(p=0.2, inplace=False)
(fc2): Linear(in_features=192, out_features=96, bias=True)
(dropout2): Dropout(p=0.2, inplace=False)
)
(gating_block): TinyTimeMixerGatedAttention(
(attn_layer): Linear(in_features=96, out_features=96, bias=True)
(attn_softmax): Softmax(dim=-1)
)
)
)
)
)
(2): TinyTimeMixerAdaptivePatchingBlock(
(mixer_layers): ModuleList(
(0-1): 2 x TinyTimeMixerLayer(
(patch_mixer): PatchMixerBlock(
(norm): TinyTimeMixerNormLayer(
(norm): LayerNorm((192,), eps=1e-05, elementwise_affine=True)
)
(mlp): TinyTimeMixerMLP(
(fc1): Linear(in_features=8, out_features=16, bias=True)
(dropout1): Dropout(p=0.2, inplace=False)
(fc2): Linear(in_features=16, out_features=8, bias=True)
(dropout2): Dropout(p=0.2, inplace=False)
)
(gating_block): TinyTimeMixerGatedAttention(
(attn_layer): Linear(in_features=8, out_features=8, bias=True)
(attn_softmax): Softmax(dim=-1)
)
)
(feature_mixer): FeatureMixerBlock(
(norm): TinyTimeMixerNormLayer(
(norm): LayerNorm((192,), eps=1e-05, elementwise_affine=True)
)
(mlp): TinyTimeMixerMLP(
(fc1): Linear(in_features=192, out_features=384, bias=True)
(dropout1): Dropout(p=0.2, inplace=False)
(fc2): Linear(in_features=384, out_features=192, bias=True)
(dropout2): Dropout(p=0.2, inplace=False)
)
(gating_block): TinyTimeMixerGatedAttention(
(attn_layer): Linear(in_features=192, out_features=192, bias=True)
(attn_softmax): Softmax(dim=-1)
)
)
)
)
)
)
)
)
(patching): TinyTimeMixerPatchify()
(scaler): TinyTimeMixerStdScaler()
)
(decoder): TinyTimeMixerDecoder(
(adapter): Linear(in_features=192, out_features=128, bias=True)
(decoder_block): TinyTimeMixerBlock(
(mixers): ModuleList(
(0-1): 2 x TinyTimeMixerLayer(
(patch_mixer): PatchMixerBlock(
(norm): TinyTimeMixerNormLayer(
(norm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
)
(mlp): TinyTimeMixerMLP(
(fc1): Linear(in_features=8, out_features=16, bias=True)
(dropout1): Dropout(p=0.2, inplace=False)
(fc2): Linear(in_features=16, out_features=8, bias=True)
(dropout2): Dropout(p=0.2, inplace=False)
)
(gating_block): TinyTimeMixerGatedAttention(
(attn_layer): Linear(in_features=8, out_features=8, bias=True)
(attn_softmax): Softmax(dim=-1)
)
)
(feature_mixer): FeatureMixerBlock(
(norm): TinyTimeMixerNormLayer(
(norm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
)
(mlp): TinyTimeMixerMLP(
(fc1): Linear(in_features=128, out_features=256, bias=True)
(dropout1): Dropout(p=0.2, inplace=False)
(fc2): Linear(in_features=256, out_features=128, bias=True)
(dropout2): Dropout(p=0.2, inplace=False)
)
(gating_block): TinyTimeMixerGatedAttention(
(attn_layer): Linear(in_features=128, out_features=128, bias=True)
(attn_softmax): Softmax(dim=-1)
)
)
)
)
)
)
(head): TinyTimeMixerForPredictionHead(
(dropout_layer): Dropout(p=0.2, inplace=False)
(base_forecast_block): Linear(in_features=1024, out_features=96, bias=True)
(flatten): Flatten(start_dim=-2, end_dim=-1)
)
)推論
import torch
# 推論
forecast = model(train_tensor.to("cuda:0"))
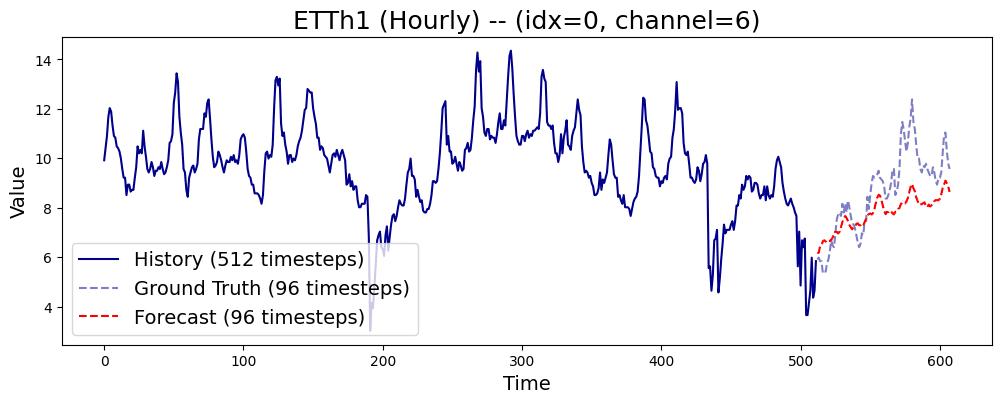
forecast_tensor = forecast.prediction_outputs.cpu()推論結果の出力
予測結果としてOT(Oil Temperature)がみたいのでchannel_idxとして6を指定します。
import matplotlib.pyplot as plt
channel_idx = 6
time_index = 0
history = train_tensor[time_index, :, channel_idx].detach().numpy()
true = test_tensor[time_index, :, channel_idx].detach().numpy()
pred = forecast_tensor[time_index, :, channel_idx].detach().numpy()
plt.figure(figsize=(12, 4))
# Plotting the first time series from history
plt.plot(range(len(history)), history, label='History (512 timesteps)', c='darkblue')
# Plotting ground truth and prediction
num_forecasts = len(true)
offset = len(history)
plt.plot(range(offset, offset + len(true)), true, label='Ground Truth (96 timesteps)', color='darkblue', linestyle='--', alpha=0.5)
plt.plot(range(offset, offset + len(pred)), pred, label='Forecast (96 timesteps)', color='red', linestyle='--')
plt.title(f"ETTh1 (Hourly) -- (idx={time_index}, channel={channel_idx})", fontsize=18)
plt.xlabel('Time', fontsize=14)
plt.ylabel('Value', fontsize=14)
plt.legend(fontsize=14)
plt.show()結果は以下のようになります。
モデルサイズが250倍あるTimesFMには流石に及んでいませんが、ある程度の予測はできている気がします。

2. Fine Tuning
Fine Tuningのコードがあったので、試していきます。
ライブラリ準備
使い慣れたTransformersのTrainerを使ってFine Tuningすることができます。
# Standard
import os
import math
import torch
# Third Party
from torch.optim import AdamW
from torch.optim.lr_scheduler import OneCycleLR
from transformers import EarlyStoppingCallback, Trainer, TrainingArguments, set_seed
import numpy as np
import pandas as pd
# Local
from tsfm_public.toolkit.callbacks import TrackingCallback
# Dataset
from tsfm_public.toolkit.dataset import ForecastDFDatasetデータセット準備
# ETTh1.csvを読み込む
df = pd.read_csv("ETTh1.csv")
# データを前8割をトレーニング用、後ろ2割をテスト用に分割
train_size = int(0.8 * len(df))
print(train_size)
df_train = df.iloc[:train_size]
df_test = df.iloc[train_size:-(context_length+forecast_horizon)]
# ForecastDFDatasetを作成
timestamp_column="date"
target_columns=["HUFL", "HULL", "MUFL", "MULL", "LUFL", "LULL", "OT"]
train_dataset = ForecastDFDataset(df_train, timestamp_column=timestamp_column, target_columns=target_columns, context_length=512, prediction_length=96)
test_dataset = ForecastDFDataset(df_test, timestamp_column=timestamp_column, target_columns=target_columns, context_length=512, prediction_length=96)モデル準備
# Load model
model = TinyTimeMixerForPrediction.from_pretrained(
"ibm/TTM", revision=TTM_MODEL_REVISION, head_dropout=0.7
)
# Freeze the backbone of the model
for param in model.backbone.parameters():
param.requires_grad = FalseTrainingArgumentsの設定
他モデルと同様に1epochだけ学習させます。
# Argsの設定
batch_size = 64
out_dir = "ttm_finetuned_models/"
num_epochs = 1
learning_rate = 0.001
finetune_forecast_args = TrainingArguments(
output_dir=os.path.join(out_dir, "output"),
overwrite_output_dir=True,
learning_rate=learning_rate,
num_train_epochs=num_epochs,
do_eval=True,
evaluation_strategy="epoch",
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
dataloader_num_workers=8,
report_to=None,
save_strategy="epoch",
logging_strategy="epoch",
save_total_limit=1,
logging_dir=os.path.join(out_dir, "logs"), # Make sure to specify a logging directory
load_best_model_at_end=True, # Load the best model when training ends
metric_for_best_model="eval_loss", # Metric to monitor for early stopping
greater_is_better=False, # For loss
)Optimizer等の宣言
# Create the early stopping callback
early_stopping_callback = EarlyStoppingCallback(
early_stopping_patience=10, # Number of epochs with no improvement after which to stop
early_stopping_threshold=0.0, # Minimum improvement required to consider as improvement
)
tracking_callback = TrackingCallback()
あ
# Optimizer and scheduler
optimizer = AdamW(model.parameters(), lr=learning_rate)
scheduler = OneCycleLR(
optimizer,
learning_rate,
epochs=num_epochs,
steps_per_epoch=math.ceil(len(train_dataset) / (batch_size)),
)Trainerの宣言と実行
モデルサイズが小さいため、学習は5秒で終わりました。(Google ColabのT4を利用)
finetune_forecast_trainer = Trainer(
model=model,
args=finetune_forecast_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
callbacks=[early_stopping_callback, tracking_callback],
optimizers=(optimizer, scheduler),
)
# Fine tune
finetune_forecast_trainer.train()3. 推論(Fine Tuning後)
最後に、先に試したのと同じ区間で推論を再度実施してみます。
データ準備
import torch
context_length = 512
forecast_horizon = 96
# データセット分割
df_train = df.iloc[-(context_length+forecast_horizon):-forecast_horizon]
df_test = df.iloc[-forecast_horizon:]
# 形式の変更
train_tensor = torch.tensor(df_train[["HUFL", "HULL", "MUFL", "MULL", "LUFL", "LULL", "OT"]].values, dtype=torch.float)
train_tensor = train_tensor.unsqueeze(0)
test_tensor = torch.tensor(df_test[["HUFL", "HULL", "MUFL", "MULL", "LUFL", "LULL", "OT"]].values, dtype=torch.float)
test_tensor = test_tensor.unsqueeze(0)推論
import torch
# 推論
model.eval()
forecast = model(train_tensor.to("cuda:0"))
forecast_tensor = forecast.prediction_outputs.cpu()推論結果の出力
import matplotlib.pyplot as plt
channel_idx = 6
time_index = 0
history = train_tensor[time_index, :, channel_idx].detach().numpy()
true = test_tensor[time_index, :, channel_idx].detach().numpy()
pred = forecast_tensor[time_index, :, channel_idx].detach().numpy()
plt.figure(figsize=(12, 4))
# Plotting the first time series from history
plt.plot(range(len(history)), history, label='History (512 timesteps)', c='darkblue')
# Plotting ground truth and prediction
num_forecasts = len(true)
offset = len(history)
plt.plot(range(offset, offset + len(true)), true, label='Ground Truth (96 timesteps)', color='darkblue', linestyle='--', alpha=0.5)
plt.plot(range(offset, offset + len(pred)), pred, label='Forecast (96 timesteps)', color='red', linestyle='--')
plt.title(f"ETTh1 (Hourly) -- (idx={time_index}, channel={channel_idx})", fontsize=18)
plt.xlabel('Time', fontsize=14)
plt.ylabel('Value', fontsize=14)
plt.legend(fontsize=14)
plt.show()結果は以下のようになりました。
4. 結果
他のモデルと比較して0.1-0.4%ほどのサイズですが、ある程度予測できる能力があるといえそうです。また、Fine Tuningできちんと予測精度を上げることもできました。
0-shotでの予測精度は他のモデルには及びませんが、その特徴的なサイズ感やFine Tuningできちんと性能が向上する点から使い道はありそうだなと感じました。
次回
参照
この記事が気に入ったらサポートをしてみませんか?